 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothness Similarity Regularization for Few-Shot GAN Adaptation
Aug 18, 2023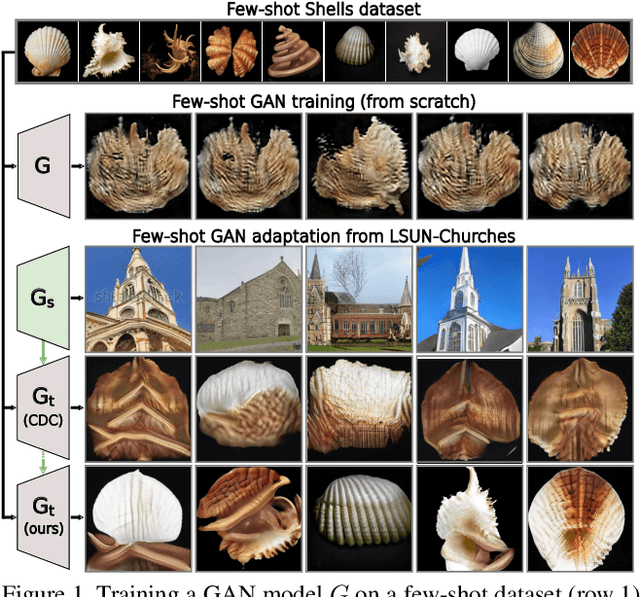
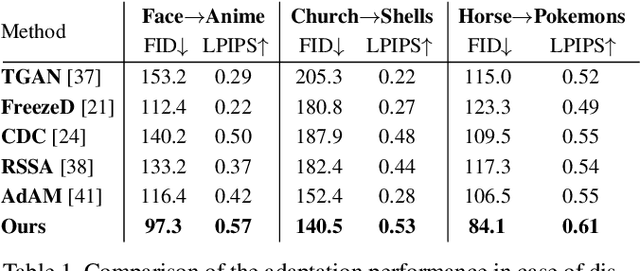
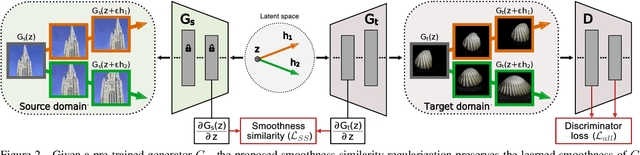
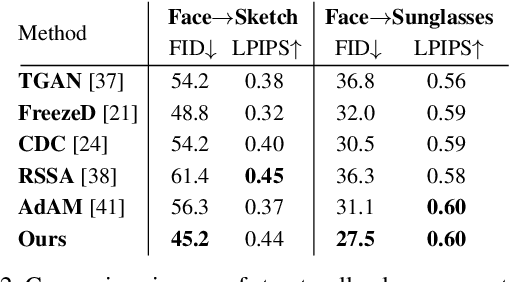
The task of few-shot GAN adaptation aims to adapt a pre-trained GAN model to a small dataset with very few training images. While existing methods perform well when the dataset for pre-training is structurally similar to the target dataset, the approaches suffer from training instabilities or memorization issues when the objects in the two domains have a very different structure. To mitigate this limitation, we propose a new smoothness similarity regularization that transfers the inherently learned smoothness of the pre-trained GAN to the few-shot target domain even if the two domains are very different. We evaluate our approach by adapting an unconditional and a class-conditional GAN to diverse few-shot target domains. Our proposed method significantly outperforms prior few-shot GAN adaptation methods in the challenging case of structurally dissimilar source-target domains, while performing on par with the state of the art for similar source-target domains.
Discovering Class-Specific GAN Controls for Semantic Image Synthesis
Dec 02, 2022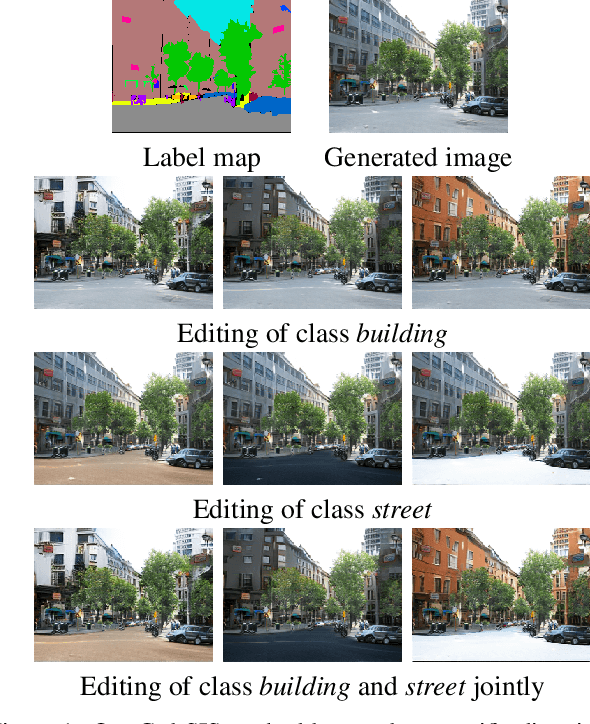

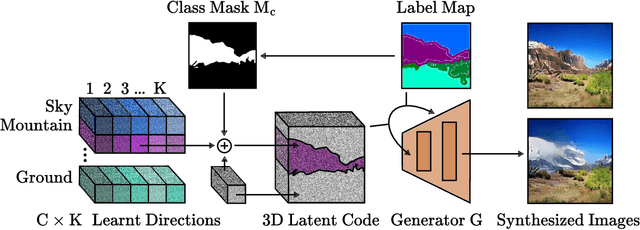
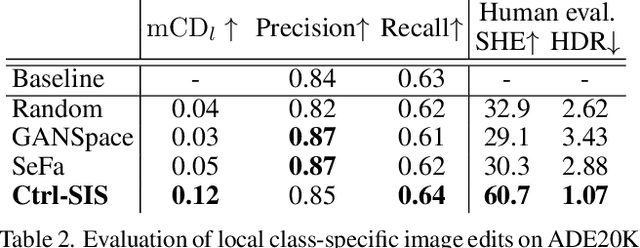
Prior work has extensively studied the latent space structure of GANs for unconditional image synthesis, enabling global editing of generated images by the unsupervised discovery of interpretable latent directions. However, the discovery of latent directions for conditional GANs for semantic image synthesis (SIS) has remained unexplored. In this work, we specifically focus on addressing this gap. We propose a novel optimization method for finding spatially disentangled class-specific directions in the latent space of pretrained SIS models. We show that the latent directions found by our method can effectively control the local appearance of semantic classes, e.g., changing their internal structure, texture or color independently from each other. Visual inspection and quantitative evaluation of the discovered GAN controls on various datasets demonstrate that our method discovers a diverse set of unique and semantically meaningful latent directions for class-specific edits.
One-Shot Synthesis of Images and Segmentation Masks
Sep 15, 2022

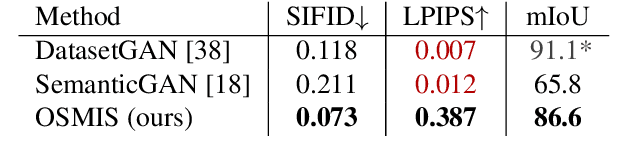
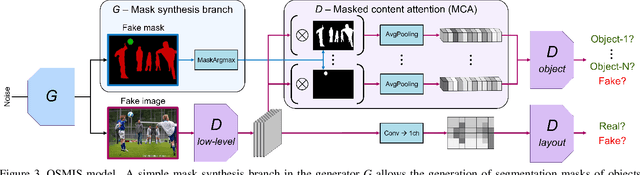
Joint synthesis of images and segmentation masks with generative adversarial networks (GANs) is promising to reduce the effort needed for collecting image data with pixel-wise annotations. However, to learn high-fidelity image-mask synthesis, existing GAN approaches first need a pre-training phase requiring large amounts of image data, which limits their utilization in restricted image domains. In this work, we take a step to reduce this limitation, introducing the task of one-shot image-mask synthesis. We aim to generate diverse images and their segmentation masks given only a single labelled example, and assuming, contrary to previous models, no access to any pre-training data. To this end, inspired by the recent architectural developments of single-image GANs, we introduce our OSMIS model which enables the synthesis of segmentation masks that are precisely aligned to the generated images in the one-shot regime. Besides achieving the high fidelity of generated masks, OSMIS outperforms state-of-the-art single-image GAN models in image synthesis quality and diversity. In addition, despite not using any additional data, OSMIS demonstrates an impressive ability to serve as a source of useful data augmentation for one-shot segmentation applications, providing performance gains that are complementary to standard data augmentation techniques. Code is available at https://github.com/ boschresearch/one-shot-synthesis
Decentralized Personalized Federated Min-Max Problems
Jun 14, 2021
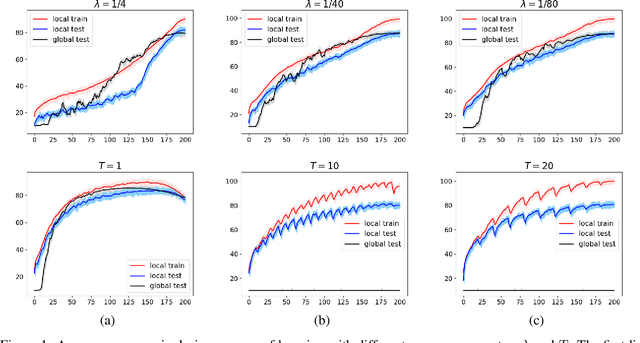
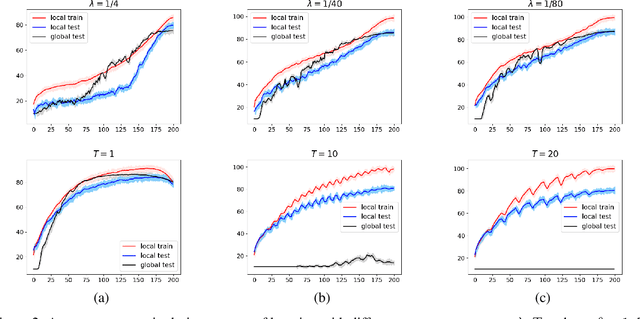
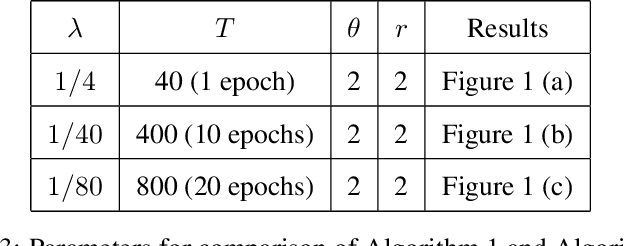
Personalized Federated Learning has recently seen tremendous progress, allowing the design of novel machine learning applications preserving privacy of the data used for training. Existing theoretical results in this field mainly focus on distributed optimization under minimization problems. This paper is the first to study PFL for saddle point problems, which cover a broader class of optimization tasks and are thus of more relevance for applications than the minimization. In this work, we consider a recently proposed PFL setting with the mixing objective function, an approach combining the learning of a global model together with local distributed learners. Unlike most of the previous papers, which considered only the centralized setting, we work in a more general and decentralized setup. This allows to design and to analyze more practical and federated ways to connect devices to the network. We present two new algorithms for our problem. A theoretical analysis of the methods is presented for smooth (strongly-)convex-(strongly-)concave saddle point problems. We also demonstrate the effectiveness of our problem formulation and the proposed algorithms on experiments with neural networks with adversarial noise.
Learning to Generate Novel Scene Compositions from Single Images and Videos
May 12, 2021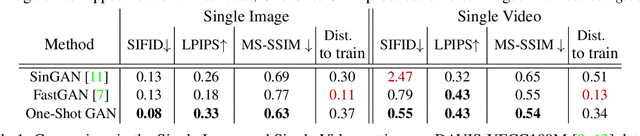
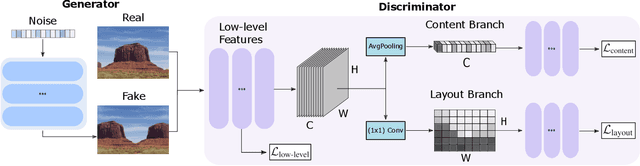


Training GANs in low-data regimes remains a challenge, as overfitting often leads to memorization or training divergence. In this work, we introduce One-Shot GAN that can learn to generate samples from a training set as little as one image or one video. We propose a two-branch discriminator, with content and layout branches designed to judge the internal content separately from the scene layout realism. This allows synthesis of visually plausible, novel compositions of a scene, with varying content and layout, while preserving the context of the original sample. Compared to previous single-image GAN models, One-Shot GAN achieves higher diversity and quality of synthesis. It is also not restricted to the single image setting, successfully learning in the introduced setting of a single video.
One-Shot GAN: Learning to Generate Samples from Single Images and Videos
Mar 24, 2021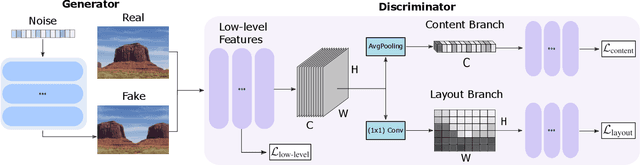
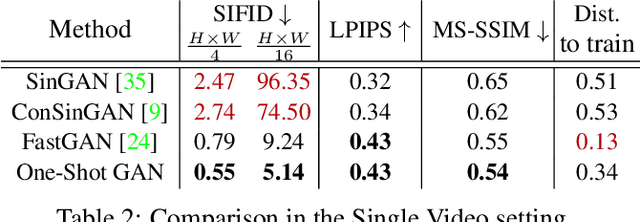

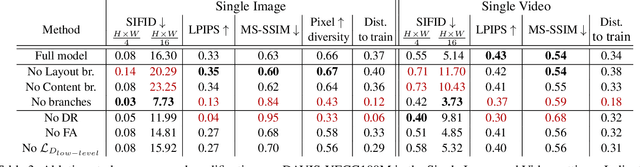
Given a large number of training samples, GANs can achieve remarkable performance for the image synthesis task. However, training GANs in extremely low-data regimes remains a challenge, as overfitting often occurs, leading to memorization or training divergence. In this work, we introduce One-Shot GAN, an unconditional generative model that can learn to generate samples from a single training image or a single video clip. We propose a two-branch discriminator architecture, with content and layout branches designed to judge internal content and scene layout realism separately from each other. This allows synthesis of visually plausible, novel compositions of a scene, with varying content and layout, while preserving the context of the original sample. Compared to previous single-image GAN models, One-Shot GAN generates more diverse, higher quality images, while also not being restricted to a single image setting. We show that our model successfully deals with other one-shot regimes, and introduce a new task of learning generative models from a single video.
You Only Need Adversarial Supervision for Semantic Image Synthesis
Dec 08, 2020
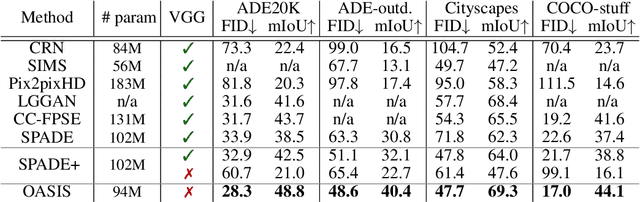

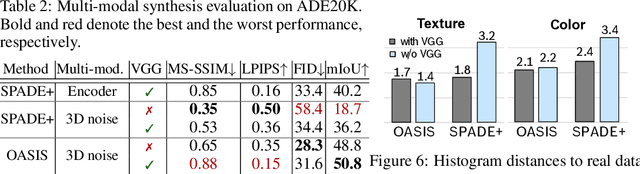
Despite their recent successes, GAN models for semantic image synthesis still suffer from poor image quality when trained with only adversarial supervision. Historically, additionally employing the VGG-based perceptual loss has helped to overcome this issue, significantly improving the synthesis quality, but at the same time limiting the progress of GAN models for semantic image synthesis. In this work, we propose a novel, simplified GAN model, which needs only adversarial supervision to achieve high quality results. We re-design the discriminator as a semantic segmentation network, directly using the given semantic label maps as the ground truth for training. By providing stronger supervision to the discriminator as well as to the generator through spatially- and semantically-aware discriminator feedback, we are able to synthesize images of higher fidelity with better alignment to their input label maps, making the use of the perceptual loss superfluous. Moreover, we enable high-quality multi-modal image synthesis through global and local sampling of a 3D noise tensor injected into the generator, which allows complete or partial image change. We show that images synthesized by our model are more diverse and follow the color and texture distributions of real images more closely. We achieve an average improvement of $6$ FID and $5$ mIoU points over the state of the art across different datasets using only adversarial supervision.