 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Shot GAN: Learning to Generate Samples from Single Images and Videos
Paper and Code
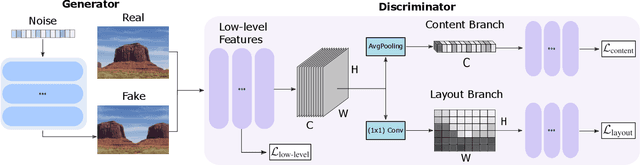
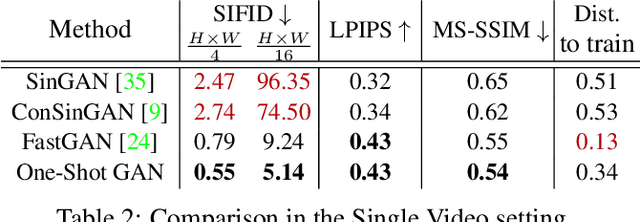

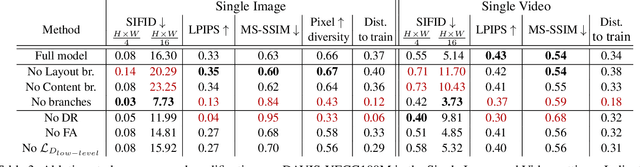
Given a large number of training samples, GANs can achieve remarkable performance for the image synthesis task. However, training GANs in extremely low-data regimes remains a challenge, as overfitting often occurs, leading to memorization or training divergence. In this work, we introduce One-Shot GAN, an unconditional generative model that can learn to generate samples from a single training image or a single video clip. We propose a two-branch discriminator architecture, with content and layout branches designed to judge internal content and scene layout realism separately from each other. This allows synthesis of visually plausible, novel compositions of a scene, with varying content and layout, while preserving the context of the original sample. Compared to previous single-image GAN models, One-Shot GAN generates more diverse, higher quality images, while also not being restricted to a single image setting. We show that our model successfully deals with other one-shot regimes, and introduce a new task of learning generative models from a single video.