 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEco-Mobility-on-Demand Fleet Control with Ride-Sharing
Aug 23, 2019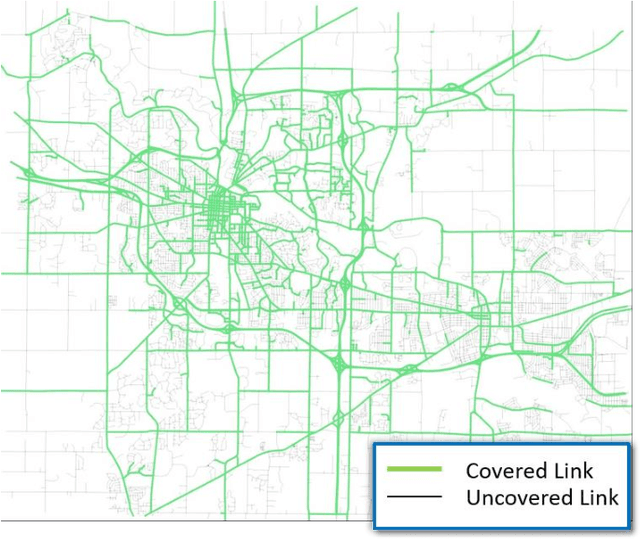
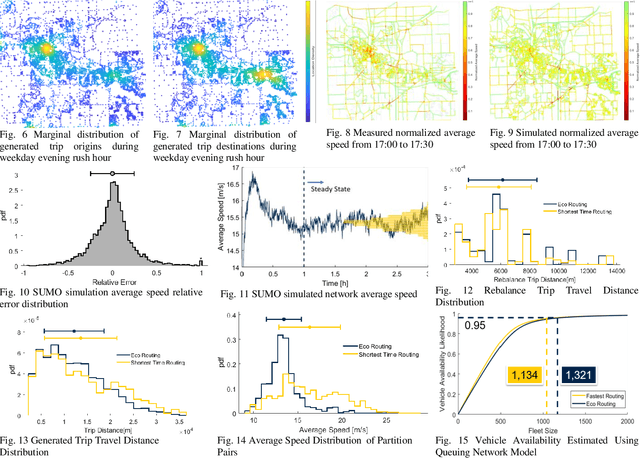

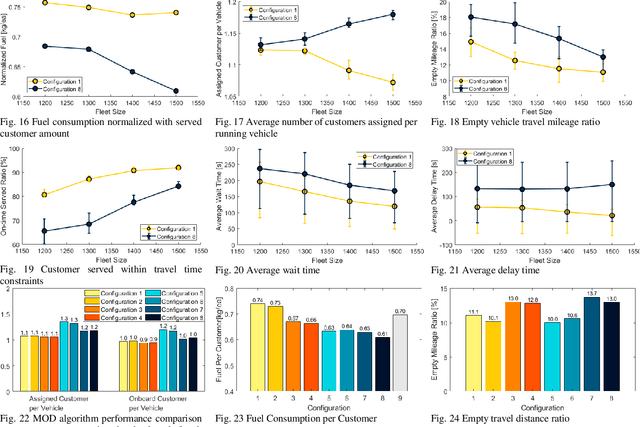
Shared Mobility-on-Demand using automated vehicles can reduce energy consumption and cost for future mobility. However, its full potential in energy saving has not been fully explored. An algorithm to minimize fleet fuel consumption while satisfying customers travel time constraints is developed in this paper. Numerical simulations with realistic travel demand and route choice are performed, showing that if fuel consumption is not considered, the MOD service can increase fleet fuel consumption due to increased empty vehicle mileage. With fuel consumption as part of the cost function, we can reduce total fuel consumption by 12 percent while maintaining a high level of mobility service.
Scalable Data Augmentation for Deep Learning
Mar 22, 2019



Scalable Data Augmentation (SDA) provides a framework for training deep learning models using auxiliary hidden layers. Scalable MCMC is available for network training and inference. SDA provides a number of computational advantages over traditional algorithms, such as avoiding backtracking, local modes and can perform optimization with stochastic gradient descent (SGD) in TensorFlow. Standard deep neural networks with logit, ReLU and SVM activation functions are straightforward to implement. To illustrate our architectures and methodology, we use P\'{o}lya-Gamma logit data augmentation for a number of standard datasets. Finally, we conclude with directions for future research.
Deep Learning
Aug 03, 2018
Deep learning (DL) is a high dimensional data reduction technique for constructing high-dimensional predictors in input-output models. DL is a form of machine learning that uses hierarchical layers of latent features. In this article, we review the state-of-the-art of deep learning from a modeling and algorithmic perspective. We provide a list of successful areas of applications in Artificial Intelligence (AI), Image Processing, Robotics and Automation. Deep learning is predictive in its nature rather then inferential and can be viewed as a black-box methodology for high-dimensional function estimation.
Deep Learning for Spatio-Temporal Modeling: Dynamic Traffic Flows and High Frequency Trading
May 07, 2018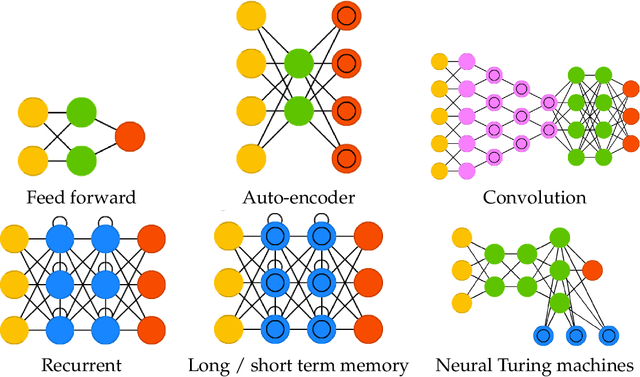


Deep learning applies hierarchical layers of hidden variables to construct nonlinear high dimensional predictors. Our goal is to develop and train deep learning architectures for spatio-temporal modeling. Training a deep architecture is achieved by stochastic gradient descent (SGD) and drop-out (DO) for parameter regularization with a goal of minimizing out-of-sample predictive mean squared error. To illustrate our methodology, we predict the sharp discontinuities in traffic flow data, and secondly, we develop a classification rule to predict short-term futures market prices as a function of the order book depth. Finally, we conclude with directions for future research.