 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulation-based Inference via Langevin Dynamics with Score Matching
Sep 04, 2025Simulation-based inference (SBI) enables Bayesian analysis when the likelihood is intractable but model simulations are available. Recent advances in statistics and machine learning, including Approximate Bayesian Computation and deep generative models, have expanded the applicability of SBI, yet these methods often face challenges in moderate to high-dimensional parameter spaces. Motivated by the success of gradient-based Monte Carlo methods in Bayesian sampling, we propose a novel SBI method that integrates score matching with Langevin dynamics to explore complex posterior landscapes more efficiently in such settings. Our approach introduces tailored score-matching procedures for SBI, including a localization scheme that reduces simulation costs and an architectural regularization that embeds the statistical structure of log-likelihood scores to improve score-matching accuracy. We provide theoretical analysis of the method and illustrate its practical benefits on benchmark tasks and on more challenging problems in moderate to high dimensions, where it performs favorably compared to existing approaches.
Adversarial Bayesian Simulation
Aug 25, 2022


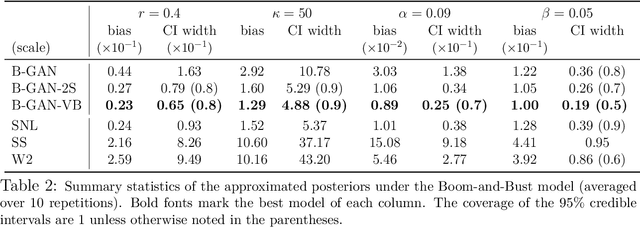
In the absence of explicit or tractable likelihoods, Bayesians often resort to approximate Bayesian computation (ABC) for inference. Our work bridges ABC with deep neural implicit samplers based on generative adversarial networks (GANs) and adversarial variational Bayes. Both ABC and GANs compare aspects of observed and fake data to simulate from posteriors and likelihoods, respectively. We develop a Bayesian GAN (B-GAN) sampler that directly targets the posterior by solving an adversarial optimization problem. B-GAN is driven by a deterministic mapping learned on the ABC reference by conditional GANs. Once the mapping has been trained, iid posterior samples are obtained by filtering noise at a negligible additional cost. We propose two post-processing local refinements using (1) data-driven proposals with importance reweighing, and (2) variational Bayes. We support our findings with frequentist-Bayesian results, showing that the typical total variation distance between the true and approximate posteriors converges to zero for certain neural network generators and discriminators. Our findings on simulated data show highly competitive performance relative to some of the most recent likelihood-free posterior simulators.
Approximate Bayesian Computation via Classification
Nov 22, 2021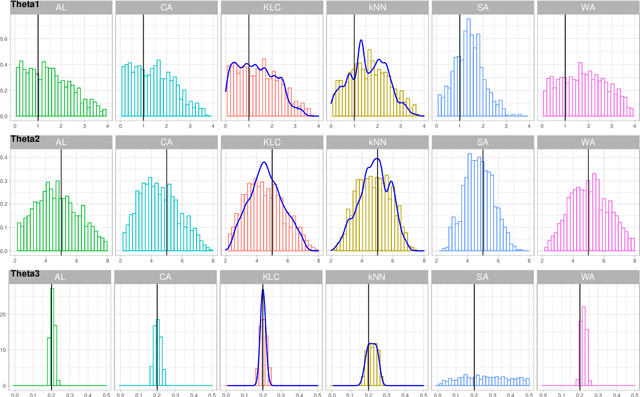
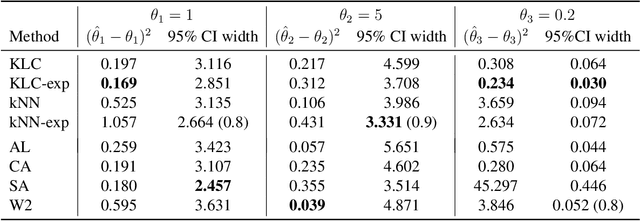
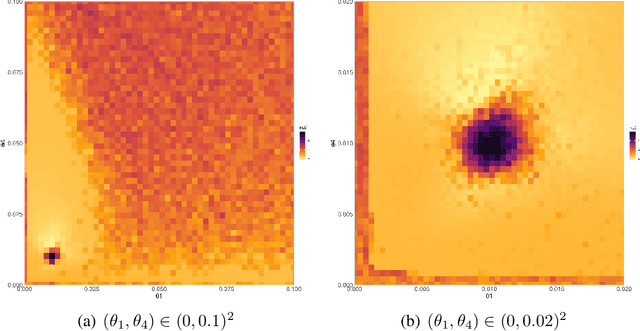
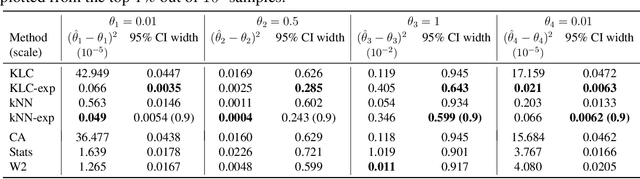
Approximate Bayesian Computation (ABC) enables statistical inference in complex models whose likelihoods are difficult to calculate but easy to simulate from. ABC constructs a kernel-type approximation to the posterior distribution through an accept/reject mechanism which compares summary statistics of real and simulated data. To obviate the need for summary statistics, we directly compare empirical distributions with a Kullback-Leibler (KL) divergence estimator obtained via classification. In particular, we blend flexible machine learning classifiers within ABC to automate fake/real data comparisons. We consider the traditional accept/reject kernel as well as an exponential weighting scheme which does not require the ABC acceptance threshold. Our theoretical results show that the rate at which our ABC posterior distributions concentrate around the true parameter depends on the estimation error of the classifier. We derive limiting posterior shape results and find that, with a properly scaled exponential kernel, asymptotic normality holds. We demonstrate the usefulness of our approach on simulated examples as well as real data in the context of stock volatility estimation.
Uncertainty Quantification for Sparse Deep Learning
Feb 26, 2020
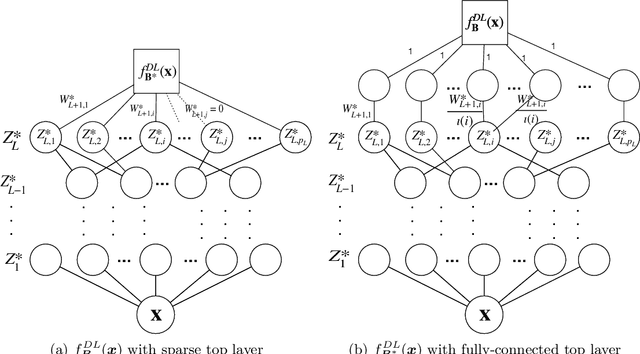
Deep learning methods continue to have a decided impact on machine learning, both in theory and in practice. Statistical theoretical developments have been mostly concerned with approximability or rates of estimation when recovering infinite dimensional objects (curves or densities). Despite the impressive array of available theoretical results, the literature has been largely silent about uncertainty quantification for deep learning. This paper takes a step forward in this important direction by taking a Bayesian point of view. We study Gaussian approximability of certain aspects of posterior distributions of sparse deep ReLU architectures in non-parametric regression. Building on tools from Bayesian non-parametrics, we provide semi-parametric Bernstein-von Mises theorems for linear and quadratic functionals, which guarantee that implied Bayesian credible regions have valid frequentist coverage. Our results provide new theoretical justifications for (Bayesian) deep learning with ReLU activation functions, highlighting their inferential potential.
Scalable Data Augmentation for Deep Learning
Mar 22, 2019



Scalable Data Augmentation (SDA) provides a framework for training deep learning models using auxiliary hidden layers. Scalable MCMC is available for network training and inference. SDA provides a number of computational advantages over traditional algorithms, such as avoiding backtracking, local modes and can perform optimization with stochastic gradient descent (SGD) in TensorFlow. Standard deep neural networks with logit, ReLU and SVM activation functions are straightforward to implement. To illustrate our architectures and methodology, we use P\'{o}lya-Gamma logit data augmentation for a number of standard datasets. Finally, we conclude with directions for future research.