 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Treatment on Networks
May 07, 2026In networks, effective dynamic treatment allocation requires deciding both whom to treat and also when, so as to amplify policy impact through spillovers. An early intervention at a well-connected node can trigger cascades that change which nodes are worth targeting in the next period. Existing treatment strategies under network interference are largely static while dynamic treatment frameworks typically ignore network structure altogether. We integrate these perspectives and propose Q-Ising, a three-stage pipeline that (i) estimates network adoption dynamics via a Bayesian dynamic Ising model from a single observed panel, (ii) augments treatment adoption histories with continuous posterior latent states, and (iii) learns a dynamic policy via offline reinforcement learning. The Bayesian mechanism enables uncertainty quantification over dynamic decisions, yielding posterior ensemble policies with interpretable spillover estimates. We provide a finite-sample regret upper bound that decomposes into standard offline-RL uncertainty, network abstraction error, and first stage error in Ising state estimation. We apply our method to data from Indian village microfinance networks and synthetic stochastic block models under simulated heterogeneous susceptible-infected-susceptible (SIS) dynamics and demonstrate that adaptive targeting outperforms static centrality benchmarks.
Jigsaw Regularization in Whole-Slide Image Classification
Mar 20, 2026Computational pathology involves the digitization of stained tissues into whole-slide images (WSIs) that contain billions of pixels arranged as contiguous patches. Statistical analysis of WSIs largely focuses on classification via multiple instance learning (MIL), in which slide-level labels are inferred from unlabeled patches. Most MIL methods treat patches as exchangeable, overlooking the rich spatial and topological structure that underlies tissue images. This work builds on recent graph-based methods that aim to incorporate spatial awareness into MIL. Our approach is new in two regards: (1) we deploy vision \emph{foundation-model embeddings} to incorporate local spatial structure within each patch, and (2) achieve across-patch spatial awareness using graph neural networks together with a novel {\em jigsaw regularization}. We find that a combination of these two features markedly improves classification over state-of-the-art attention-based MIL approaches on benchmark datasets in breast, head-and-neck, and colon cancer.
AI-Powered Bayesian Inference
Feb 26, 2025The advent of Generative Artificial Intelligence (GAI) has heralded an inflection point that changed how society thinks about knowledge acquisition. While GAI cannot be fully trusted for decision-making, it may still provide valuable information that can be integrated into a decision pipeline. Rather than seeing the lack of certitude and inherent randomness of GAI as a problem, we view it as an opportunity. Indeed, variable answers to given prompts can be leveraged to construct a prior distribution which reflects assuredness of AI predictions. This prior distribution may be combined with tailored datasets for a fully Bayesian analysis with an AI-driven prior. In this paper, we explore such a possibility within a non-parametric Bayesian framework. The basic idea consists of assigning a Dirichlet process prior distribution on the data-generating distribution with AI generative model as its baseline. Hyper-parameters of the prior can be tuned out-of-sample to assess the informativeness of the AI prior. Posterior simulation is achieved by computing a suitably randomized functional on an augmented data that consists of observed (labeled) data as well as fake data whose labels have been imputed using AI. This strategy can be parallelized and rapidly produces iid samples from the posterior by optimization as opposed to sampling from conditionals. Our method enables (predictive) inference and uncertainty quantification leveraging AI predictions in a coherent probabilistic manner.
Deep Generative Quantile Bayes
Oct 10, 2024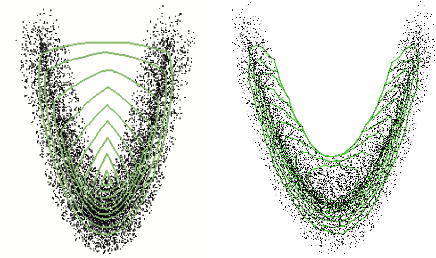
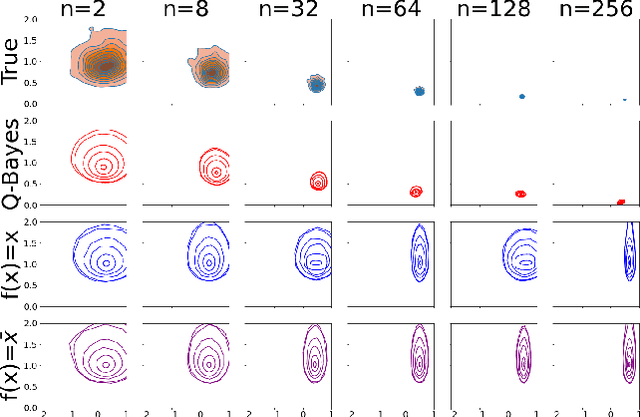
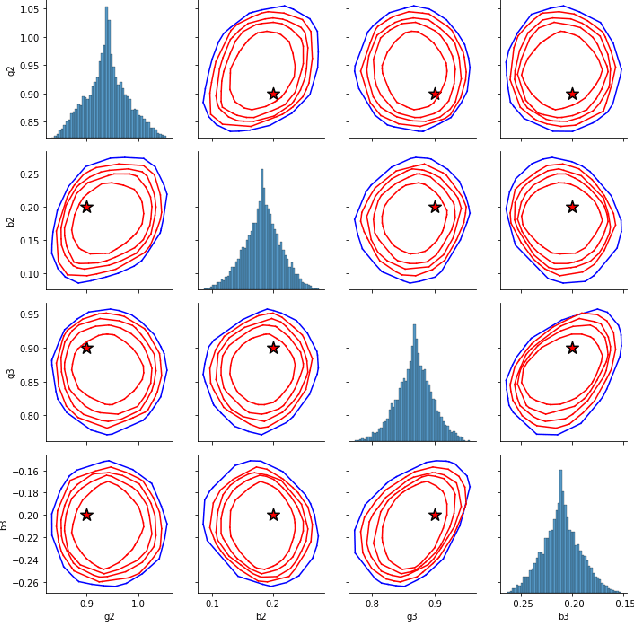
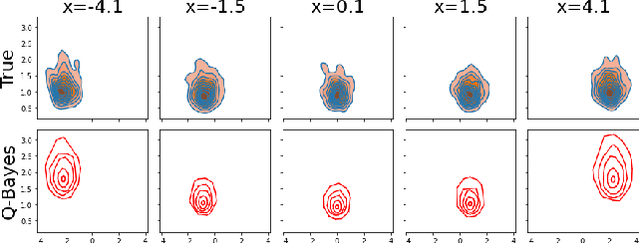
We develop a multivariate posterior sampling procedure through deep generative quantile learning. Simulation proceeds implicitly through a push-forward mapping that can transform i.i.d. random vector samples from the posterior. We utilize Monge-Kantorovich depth in multivariate quantiles to directly sample from Bayesian credible sets, a unique feature not offered by typical posterior sampling methods. To enhance the training of the quantile mapping, we design a neural network that automatically performs summary statistic extraction. This additional neural network structure has performance benefits, including support shrinkage (i.e., contraction of our posterior approximation) as the observation sample size increases. We demonstrate the usefulness of our approach on several examples where the absence of likelihood renders classical MCMC infeasible. Finally, we provide the following frequentist theoretical justifications for our quantile learning framework: {consistency of the estimated vector quantile, of the recovered posterior distribution, and of the corresponding Bayesian credible sets.
Adversarial Bayesian Simulation
Aug 25, 2022


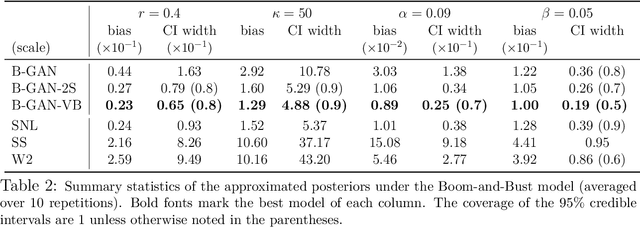
In the absence of explicit or tractable likelihoods, Bayesians often resort to approximate Bayesian computation (ABC) for inference. Our work bridges ABC with deep neural implicit samplers based on generative adversarial networks (GANs) and adversarial variational Bayes. Both ABC and GANs compare aspects of observed and fake data to simulate from posteriors and likelihoods, respectively. We develop a Bayesian GAN (B-GAN) sampler that directly targets the posterior by solving an adversarial optimization problem. B-GAN is driven by a deterministic mapping learned on the ABC reference by conditional GANs. Once the mapping has been trained, iid posterior samples are obtained by filtering noise at a negligible additional cost. We propose two post-processing local refinements using (1) data-driven proposals with importance reweighing, and (2) variational Bayes. We support our findings with frequentist-Bayesian results, showing that the typical total variation distance between the true and approximate posteriors converges to zero for certain neural network generators and discriminators. Our findings on simulated data show highly competitive performance relative to some of the most recent likelihood-free posterior simulators.
Approximate Bayesian Computation via Classification
Nov 22, 2021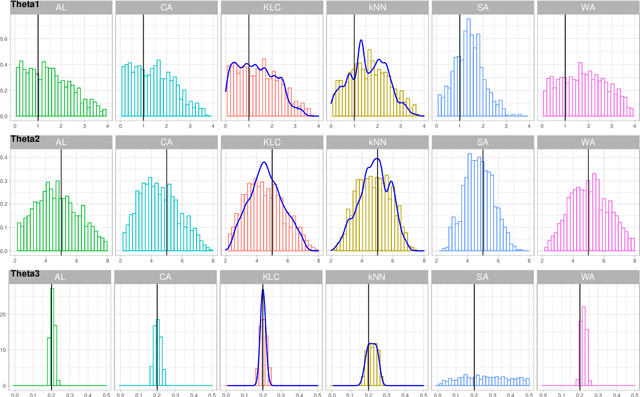
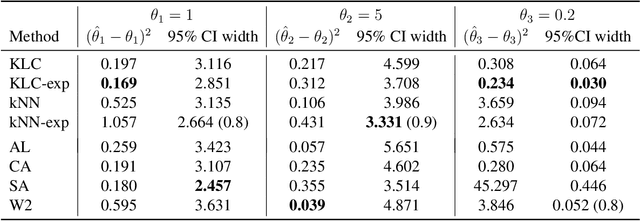
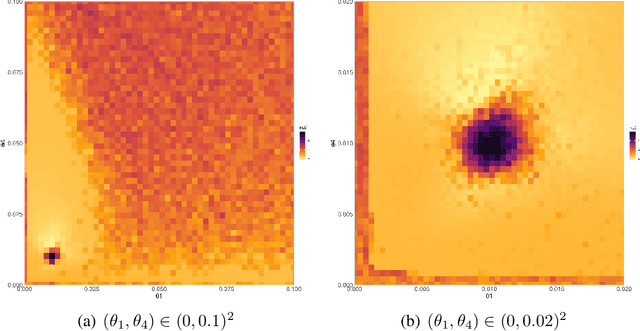
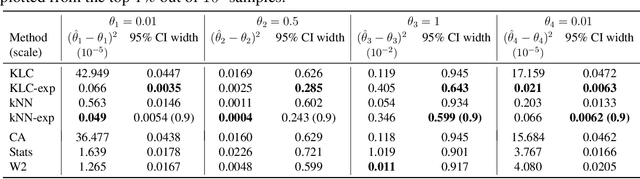
Approximate Bayesian Computation (ABC) enables statistical inference in complex models whose likelihoods are difficult to calculate but easy to simulate from. ABC constructs a kernel-type approximation to the posterior distribution through an accept/reject mechanism which compares summary statistics of real and simulated data. To obviate the need for summary statistics, we directly compare empirical distributions with a Kullback-Leibler (KL) divergence estimator obtained via classification. In particular, we blend flexible machine learning classifiers within ABC to automate fake/real data comparisons. We consider the traditional accept/reject kernel as well as an exponential weighting scheme which does not require the ABC acceptance threshold. Our theoretical results show that the rate at which our ABC posterior distributions concentrate around the true parameter depends on the estimation error of the classifier. We derive limiting posterior shape results and find that, with a properly scaled exponential kernel, asymptotic normality holds. We demonstrate the usefulness of our approach on simulated examples as well as real data in the context of stock volatility estimation.
Uncertainty Quantification for Sparse Deep Learning
Feb 26, 2020
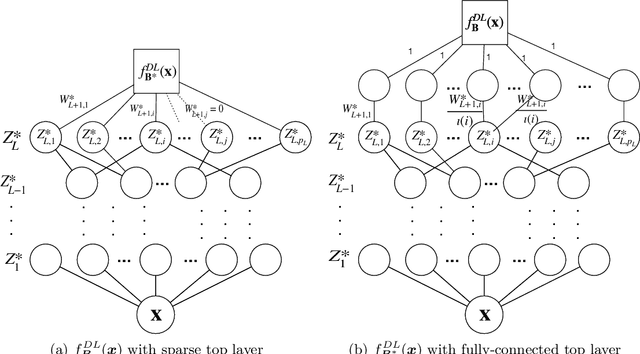
Deep learning methods continue to have a decided impact on machine learning, both in theory and in practice. Statistical theoretical developments have been mostly concerned with approximability or rates of estimation when recovering infinite dimensional objects (curves or densities). Despite the impressive array of available theoretical results, the literature has been largely silent about uncertainty quantification for deep learning. This paper takes a step forward in this important direction by taking a Bayesian point of view. We study Gaussian approximability of certain aspects of posterior distributions of sparse deep ReLU architectures in non-parametric regression. Building on tools from Bayesian non-parametrics, we provide semi-parametric Bernstein-von Mises theorems for linear and quadratic functionals, which guarantee that implied Bayesian credible regions have valid frequentist coverage. Our results provide new theoretical justifications for (Bayesian) deep learning with ReLU activation functions, highlighting their inferential potential.