 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiply-and-Fire : An Event-driven Sparse Neural Network Accelerator
Apr 20, 2022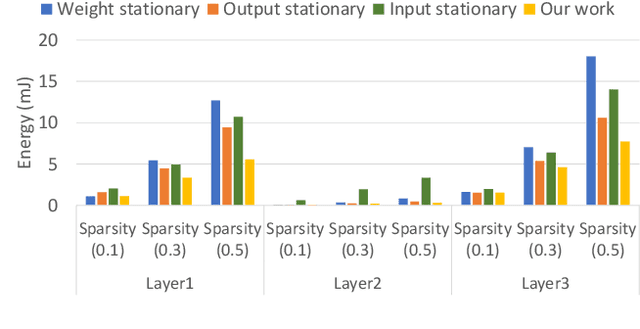
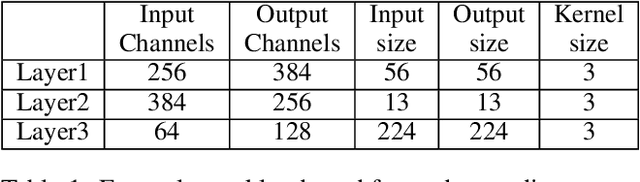
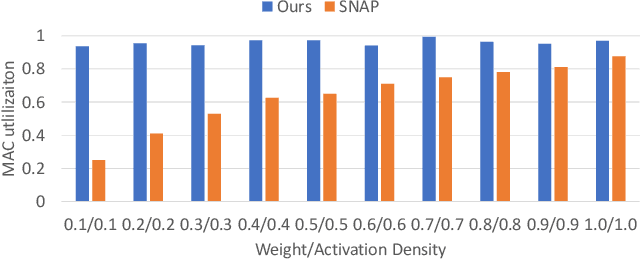
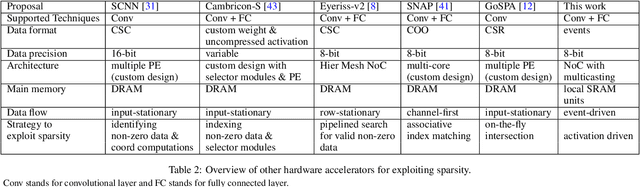
Machine learning, particularly deep neural network inference, has become a vital workload for many computing systems, from data centers and HPC systems to edge-based computing. As advances in sparsity have helped improve the efficiency of AI acceleration, there is a continued need for improved system efficiency for both high-performance and system-level acceleration. This work takes a unique look at sparsity with an event (or activation-driven) approach to ANN acceleration that aims to minimize useless work, improve utilization, and increase performance and energy efficiency. Our analytical and experimental results show that this event-driven solution presents a new direction to enable highly efficient AI inference for both CNN and MLP workloads. This work demonstrates state-of-the-art energy efficiency and performance centring on activation-based sparsity and a highly-parallel dataflow method that improves the overall functional unit utilization (at 30 fps). This work enhances energy efficiency over a state-of-the-art solution by 1.46$\times$. Taken together, this methodology presents a novel, new direction to achieve high-efficiency, high-performance designs for next-generation AI acceleration platforms.
SOTERIA: In Search of Efficient Neural Networks for Private Inference
Jul 25, 2020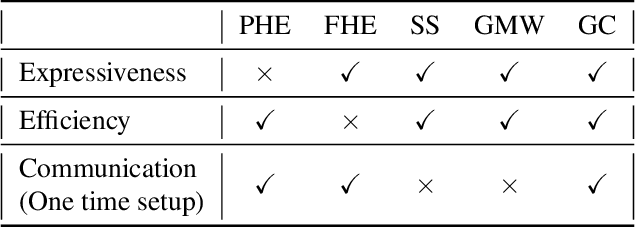
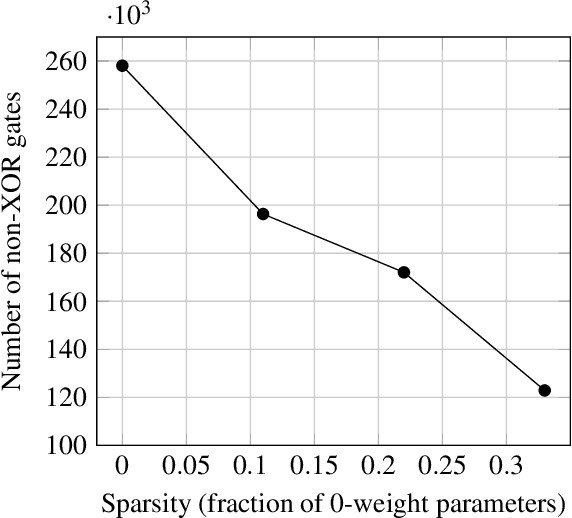
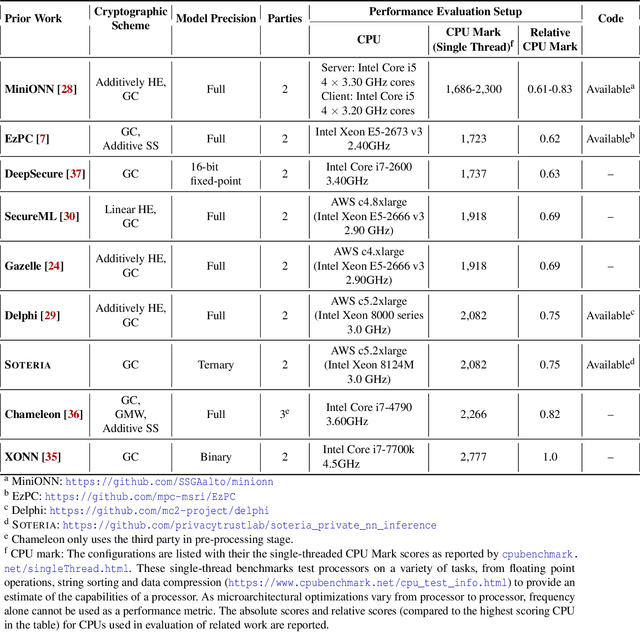
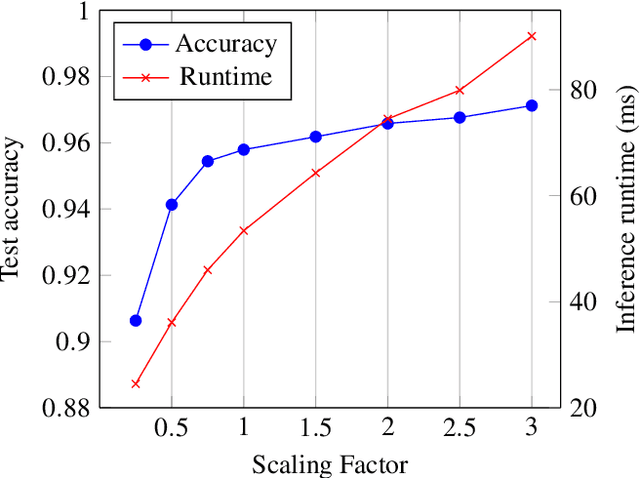
ML-as-a-service is gaining popularity where a cloud server hosts a trained model and offers prediction (inference) service to users. In this setting, our objective is to protect the confidentiality of both the users' input queries as well as the model parameters at the server, with modest computation and communication overhead. Prior solutions primarily propose fine-tuning cryptographic methods to make them efficient for known fixed model architectures. The drawback with this line of approach is that the model itself is never designed to operate with existing efficient cryptographic computations. We observe that the network architecture, internal functions, and parameters of a model, which are all chosen during training, significantly influence the computation and communication overhead of a cryptographic method, during inference. Based on this observation, we propose SOTERIA -- a training method to construct model architectures that are by-design efficient for private inference. We use neural architecture search algorithms with the dual objective of optimizing the accuracy of the model and the overhead of using cryptographic primitives for secure inference. Given the flexibility of modifying a model during training, we find accurate models that are also efficient for private computation. We select garbled circuits as our underlying cryptographic primitive, due to their expressiveness and efficiency, but this approach can be extended to hybrid multi-party computation settings. We empirically evaluate SOTERIA on MNIST and CIFAR10 datasets, to compare with the prior work. Our results confirm that SOTERIA is indeed effective in balancing performance and accuracy.
You Only Spike Once: Improving Energy-Efficient Neuromorphic Inference to ANN-Level Accuracy
Jun 03, 2020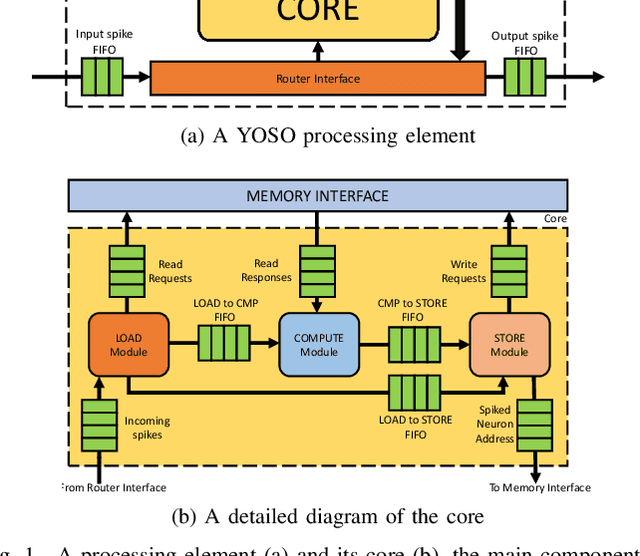
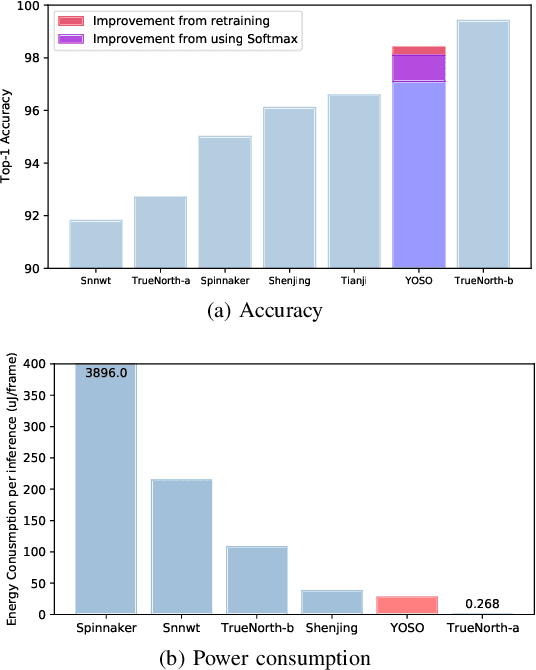


In the past decade, advances in Artificial Neural Networks (ANNs) have allowed them to perform extremely well for a wide range of tasks. In fact, they have reached human parity when performing image recognition, for example. Unfortunately, the accuracy of these ANNs comes at the expense of a large number of cache and/or memory accesses and compute operations. Spiking Neural Networks (SNNs), a type of neuromorphic, or brain-inspired network, have recently gained significant interest as power-efficient alternatives to ANNs, because they are sparse, accessing very few weights, and typically only use addition operations instead of the more power-intensive multiply-and-accumulate (MAC) operations. The vast majority of neuromorphic hardware designs support rate-encoded SNNs, where the information is encoded in spike rates. Rate-encoded SNNs could be seen as inefficient as an encoding scheme because it involves the transmission of a large number of spikes. A more efficient encoding scheme, Time-To-First-Spike (TTFS) encoding, encodes information in the relative time of arrival of spikes. While TTFS-encoded SNNs are more efficient than rate-encoded SNNs, they have, up to now, performed poorly in terms of accuracy compared to previous methods. Hence, in this work, we aim to overcome the limitations of TTFS-encoded neuromorphic systems. To accomplish this, we propose: (1) a novel optimization algorithm for TTFS-encoded SNNs converted from ANNs and (2) a novel hardware accelerator for TTFS-encoded SNNs, with a scalable and low-power design. Overall, our work in TTFS encoding and training improves the accuracy of SNNs to achieve state-of-the-art results on MNIST MLPs, while reducing power consumption by 1.29$\times$ over the state-of-the-art neuromorphic hardware.