 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiply-and-Fire : An Event-driven Sparse Neural Network Accelerator
Apr 20, 2022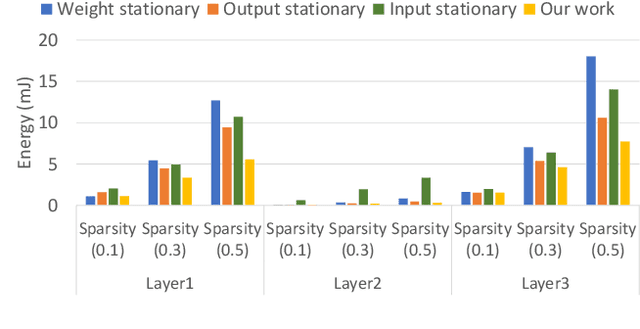
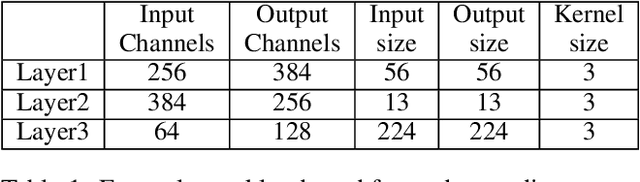
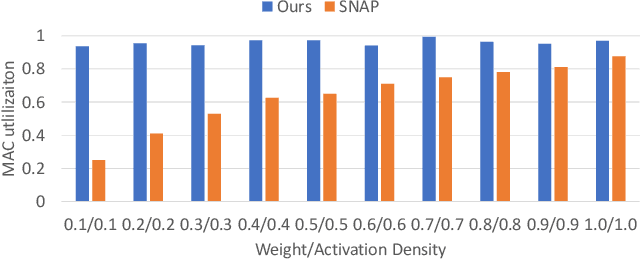
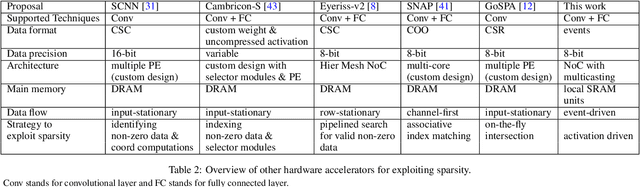
Machine learning, particularly deep neural network inference, has become a vital workload for many computing systems, from data centers and HPC systems to edge-based computing. As advances in sparsity have helped improve the efficiency of AI acceleration, there is a continued need for improved system efficiency for both high-performance and system-level acceleration. This work takes a unique look at sparsity with an event (or activation-driven) approach to ANN acceleration that aims to minimize useless work, improve utilization, and increase performance and energy efficiency. Our analytical and experimental results show that this event-driven solution presents a new direction to enable highly efficient AI inference for both CNN and MLP workloads. This work demonstrates state-of-the-art energy efficiency and performance centring on activation-based sparsity and a highly-parallel dataflow method that improves the overall functional unit utilization (at 30 fps). This work enhances energy efficiency over a state-of-the-art solution by 1.46$\times$. Taken together, this methodology presents a novel, new direction to achieve high-efficiency, high-performance designs for next-generation AI acceleration platforms.
Ultra-low power on-chip learning of speech commands with phase-change memories
Oct 21, 2020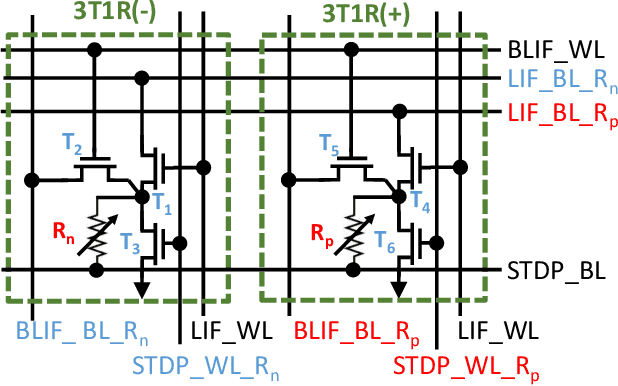
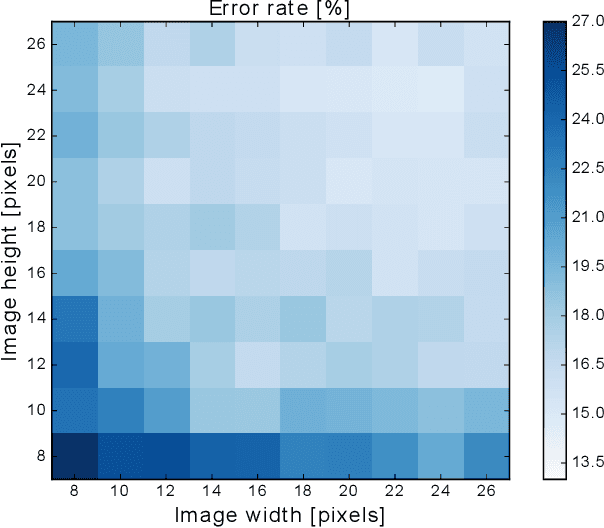
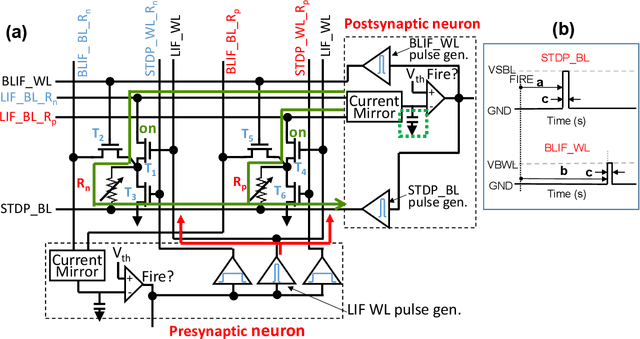
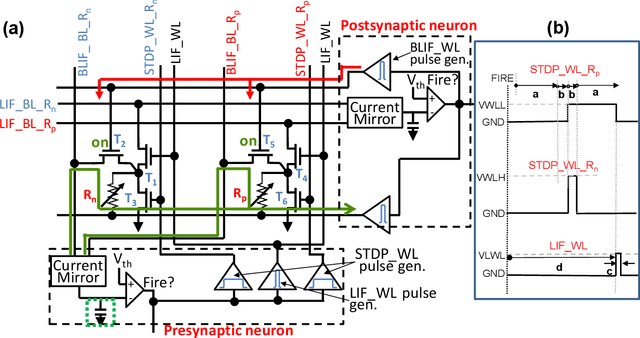
Embedding artificial intelligence at the edge (edge-AI) is an elegant solution to tackle the power and latency issues in the rapidly expanding Internet of Things. As edge devices typically spend most of their time in sleep mode and only wake-up infrequently to collect and process sensor data, non-volatile in-memory computing (NVIMC) is a promising approach to design the next generation of edge-AI devices. Recently, we proposed an NVIMC-based neuromorphic accelerator using the phase change memories (PCMs), which we call as Raven. In this work, we demonstrate the ultra-low-power on-chip training and inference of speech commands using Raven. We showed that Raven can be trained on-chip with power consumption as low as 30~uW, which is suitable for edge applications. Furthermore, we showed that at iso-accuracies, Raven needs 70.36x and 269.23x less number of computations to be performed than a deep neural network (DNN) during inference and training, respectively. Owing to such low power and computational requirements, Raven provides a promising pathway towards ultra-low-power training and inference at the edge.