 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiply-and-Fire : An Event-driven Sparse Neural Network Accelerator
Apr 20, 2022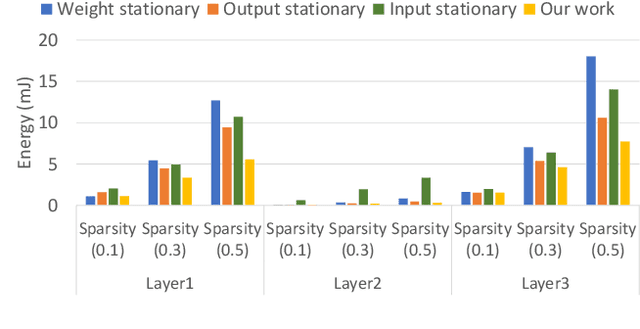
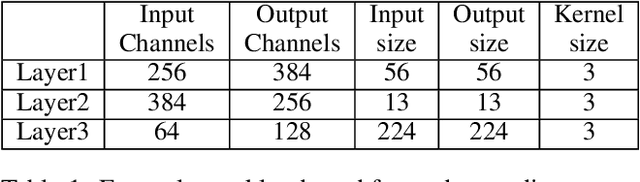
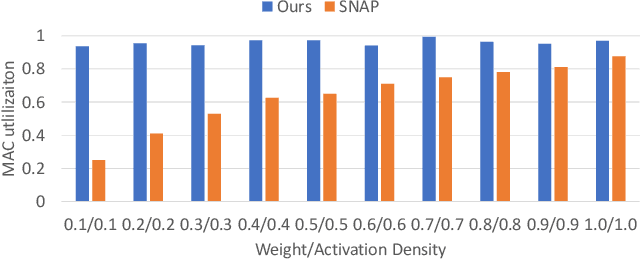
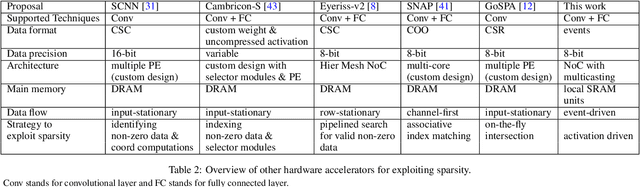
Machine learning, particularly deep neural network inference, has become a vital workload for many computing systems, from data centers and HPC systems to edge-based computing. As advances in sparsity have helped improve the efficiency of AI acceleration, there is a continued need for improved system efficiency for both high-performance and system-level acceleration. This work takes a unique look at sparsity with an event (or activation-driven) approach to ANN acceleration that aims to minimize useless work, improve utilization, and increase performance and energy efficiency. Our analytical and experimental results show that this event-driven solution presents a new direction to enable highly efficient AI inference for both CNN and MLP workloads. This work demonstrates state-of-the-art energy efficiency and performance centring on activation-based sparsity and a highly-parallel dataflow method that improves the overall functional unit utilization (at 30 fps). This work enhances energy efficiency over a state-of-the-art solution by 1.46$\times$. Taken together, this methodology presents a novel, new direction to achieve high-efficiency, high-performance designs for next-generation AI acceleration platforms.