 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOTERIA: In Search of Efficient Neural Networks for Private Inference
Jul 25, 2020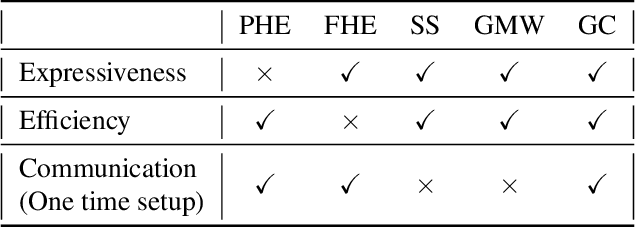
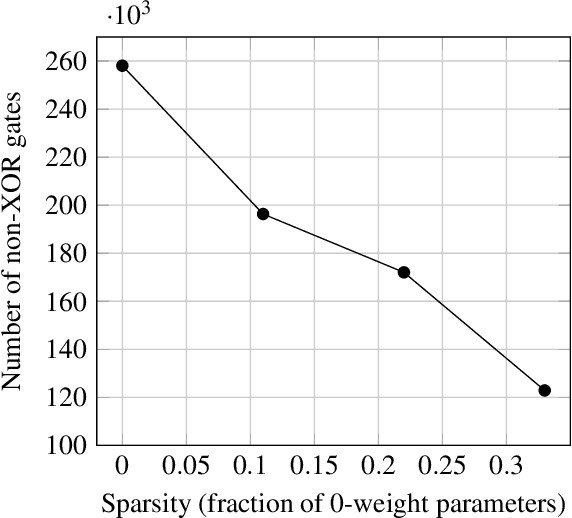
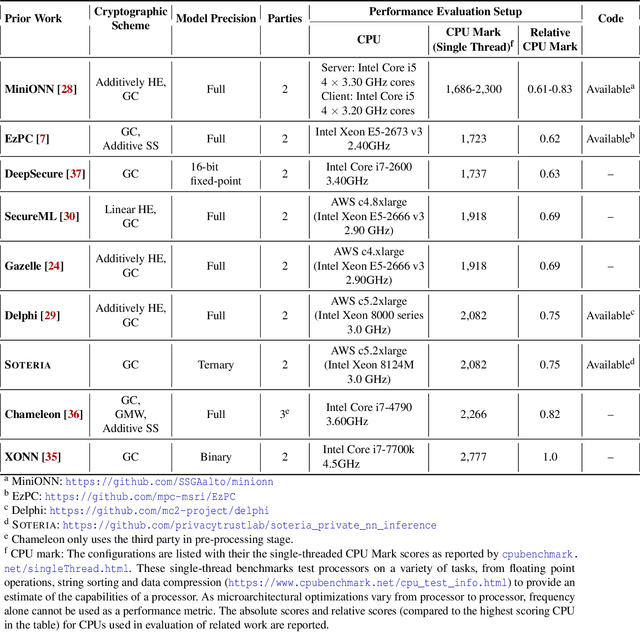
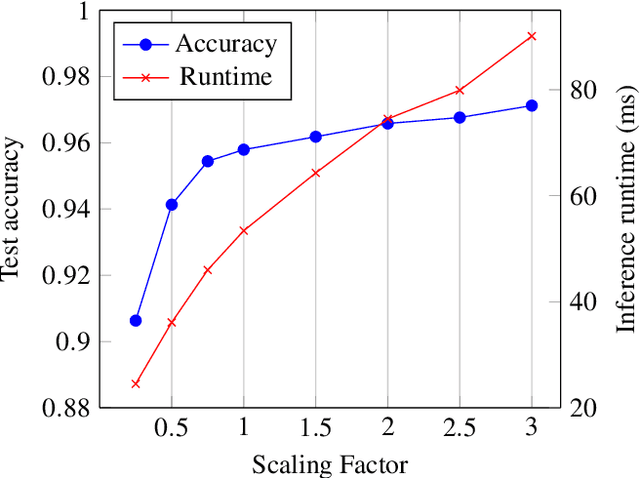
ML-as-a-service is gaining popularity where a cloud server hosts a trained model and offers prediction (inference) service to users. In this setting, our objective is to protect the confidentiality of both the users' input queries as well as the model parameters at the server, with modest computation and communication overhead. Prior solutions primarily propose fine-tuning cryptographic methods to make them efficient for known fixed model architectures. The drawback with this line of approach is that the model itself is never designed to operate with existing efficient cryptographic computations. We observe that the network architecture, internal functions, and parameters of a model, which are all chosen during training, significantly influence the computation and communication overhead of a cryptographic method, during inference. Based on this observation, we propose SOTERIA -- a training method to construct model architectures that are by-design efficient for private inference. We use neural architecture search algorithms with the dual objective of optimizing the accuracy of the model and the overhead of using cryptographic primitives for secure inference. Given the flexibility of modifying a model during training, we find accurate models that are also efficient for private computation. We select garbled circuits as our underlying cryptographic primitive, due to their expressiveness and efficiency, but this approach can be extended to hybrid multi-party computation settings. We empirically evaluate SOTERIA on MNIST and CIFAR10 datasets, to compare with the prior work. Our results confirm that SOTERIA is indeed effective in balancing performance and accuracy.