 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrban Neural Surface Reconstruction from Constrained Sparse Aerial Imagery with 3D SAR Fusion
Jan 29, 2026Neural surface reconstruction (NSR) has recently shown strong potential for urban 3D reconstruction from multi-view aerial imagery. However, existing NSR methods often suffer from geometric ambiguity and instability, particularly under sparse-view conditions. This issue is critical in large-scale urban remote sensing, where aerial image acquisition is limited by flight paths, terrain, and cost. To address this challenge, we present the first urban NSR framework that fuses 3D synthetic aperture radar (SAR) point clouds with aerial imagery for high-fidelity reconstruction under constrained, sparse-view settings. 3D SAR can efficiently capture large-scale geometry even from a single side-looking flight path, providing robust priors that complement photometric cues from images. Our framework integrates radar-derived spatial constraints into an SDF-based NSR backbone, guiding structure-aware ray selection and adaptive sampling for stable and efficient optimization. We also construct the first benchmark dataset with co-registered 3D SAR point clouds and aerial imagery, facilitating systematic evaluation of cross-modal 3D reconstruction. Extensive experiments show that incorporating 3D SAR markedly enhances reconstruction accuracy, completeness, and robustness compared with single-modality baselines under highly sparse and oblique-view conditions, highlighting a viable route toward scalable high-fidelity urban reconstruction with advanced airborne and spaceborne optical-SAR sensing.
On the Dimension-Free Approximation of Deep Neural Networks for Symmetric Korobov Functions
Nov 16, 2025
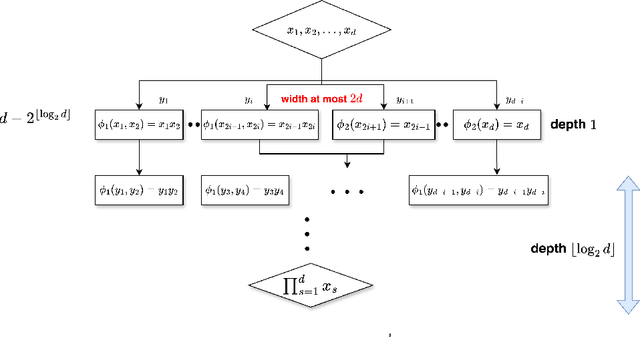
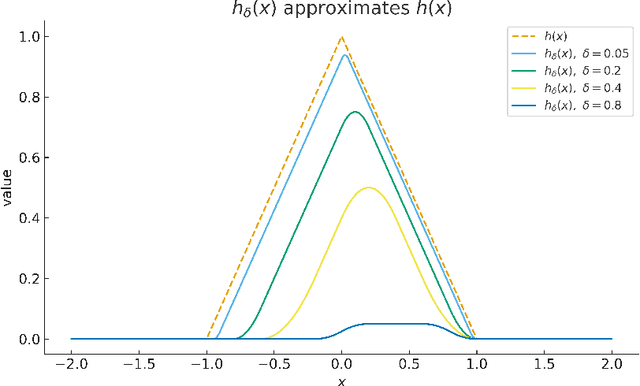
Deep neural networks have been widely used as universal approximators for functions with inherent physical structures, including permutation symmetry. In this paper, we construct symmetric deep neural networks to approximate symmetric Korobov functions and prove that both the convergence rate and the constant prefactor scale at most polynomially with respect to the ambient dimension. This represents a substantial improvement over prior approximation guarantees that suffer from the curse of dimensionality. Building on these approximation bounds, we further derive a generalization-error rate for learning symmetric Korobov functions whose leading factors likewise avoid the curse of dimensionality.
Approximation Rates for Shallow ReLU$^k$ Neural Networks on Sobolev Spaces via the Radon Transform
Aug 20, 2024
Let $\Omega\subset \mathbb{R}^d$ be a bounded domain. We consider the problem of how efficiently shallow neural networks with the ReLU$^k$ activation function can approximate functions from Sobolev spaces $W^s(L_p(\Omega))$ with error measured in the $L_q(\Omega)$-norm. Utilizing the Radon transform and recent results from discrepancy theory, we provide a simple proof of nearly optimal approximation rates in a variety of cases, including when $q\leq p$, $p\geq 2$, and $s \leq k + (d+1)/2$. The rates we derive are optimal up to logarithmic factors, and significantly generalize existing results. An interesting consequence is that the adaptivity of shallow ReLU$^k$ neural networks enables them to obtain optimal approximation rates for smoothness up to order $s = k + (d+1)/2$, even though they represent piecewise polynomials of fixed degree $k$.
Expressivity and Approximation Properties of Deep Neural Networks with ReLU$^k$ Activation
Jan 11, 2024In this paper, we investigate the expressivity and approximation properties of deep neural networks employing the ReLU$^k$ activation function for $k \geq 2$. Although deep ReLU networks can approximate polynomials effectively, deep ReLU$^k$ networks have the capability to represent higher-degree polynomials precisely. Our initial contribution is a comprehensive, constructive proof for polynomial representation using deep ReLU$^k$ networks. This allows us to establish an upper bound on both the size and count of network parameters. Consequently, we are able to demonstrate a suboptimal approximation rate for functions from Sobolev spaces as well as for analytic functions. Additionally, through an exploration of the representation power of deep ReLU$^k$ networks for shallow networks, we reveal that deep ReLU$^k$ networks can approximate functions from a range of variation spaces, extending beyond those generated solely by the ReLU$^k$ activation function. This finding demonstrates the adaptability of deep ReLU$^k$ networks in approximating functions within various variation spaces.
Tractability of approximation by general shallow networks
Aug 07, 2023In this paper, we present a sharper version of the results in the paper Dimension independent bounds for general shallow networks; Neural Networks, \textbf{123} (2020), 142-152. Let $\mathbb{X}$ and $\mathbb{Y}$ be compact metric spaces. We consider approximation of functions of the form $ x\mapsto\int_{\mathbb{Y}} G( x, y)d\tau( y)$, $ x\in\mathbb{X}$, by $G$-networks of the form $ x\mapsto \sum_{k=1}^n a_kG( x, y_k)$, $ y_1,\cdots, y_n\in\mathbb{Y}$, $a_1,\cdots, a_n\in\mathbb{R}$. Defining the dimensions of $\mathbb{X}$ and $\mathbb{Y}$ in terms of covering numbers, we obtain dimension independent bounds on the degree of approximation in terms of $n$, where also the constants involved are all dependent at most polynomially on the dimensions. Applications include approximation by power rectified linear unit networks, zonal function networks, certain radial basis function networks as well as the important problem of function extension to higher dimensional spaces.
Rates of Approximation by ReLU Shallow Neural Networks
Jul 24, 2023Neural networks activated by the rectified linear unit (ReLU) play a central role in the recent development of deep learning. The topic of approximating functions from H\"older spaces by these networks is crucial for understanding the efficiency of the induced learning algorithms. Although the topic has been well investigated in the setting of deep neural networks with many layers of hidden neurons, it is still open for shallow networks having only one hidden layer. In this paper, we provide rates of uniform approximation by these networks. We show that ReLU shallow neural networks with $m$ hidden neurons can uniformly approximate functions from the H\"older space $W_\infty^r([-1, 1]^d)$ with rates $O((\log m)^{\frac{1}{2} +d}m^{-\frac{r}{d}\frac{d+2}{d+4}})$ when $r<d/2 +2$. Such rates are very close to the optimal one $O(m^{-\frac{r}{d}})$ in the sense that $\frac{d+2}{d+4}$ is close to $1$, when the dimension $d$ is large.
Encoding of data sets and algorithms
Mar 02, 2023In many high-impact applications, it is important to ensure the quality of output of a machine learning algorithm as well as its reliability in comparison with the complexity of the algorithm used. In this paper, we have initiated a mathematically rigorous theory to decide which models (algorithms applied on data sets) are close to each other in terms of certain metrics, such as performance and the complexity level of the algorithm. This involves creating a grid on the hypothetical spaces of data sets and algorithms so as to identify a finite set of probability distributions from which the data sets are sampled and a finite set of algorithms. A given threshold metric acting on this grid will express the nearness (or statistical distance) from each algorithm and data set of interest to any given application. A technically difficult part of this project is to estimate the so-called metric entropy of a compact subset of functions of \textbf{infinitely many variables} that arise in the definition of these spaces.
Theory of Deep Convolutional Neural Networks III: Approximating Radial Functions
Jul 02, 2021We consider a family of deep neural networks consisting of two groups of convolutional layers, a downsampling operator, and a fully connected layer. The network structure depends on two structural parameters which determine the numbers of convolutional layers and the width of the fully connected layer. We establish an approximation theory with explicit approximation rates when the approximated function takes a composite form $f\circ Q$ with a feature polynomial $Q$ and a univariate function $f$. In particular, we prove that such a network can outperform fully connected shallow networks in approximating radial functions with $Q(x) =|x|^2$, when the dimension $d$ of data from $\mathbb{R}^d$ is large. This gives the first rigorous proof for the superiority of deep convolutional neural networks in approximating functions with special structures. Then we carry out generalization analysis for empirical risk minimization with such a deep network in a regression framework with the regression function of the form $f\circ Q$. Our network structure which does not use any composite information or the functions $Q$ and $f$ can automatically extract features and make use of the composite nature of the regression function via tuning the structural parameters. Our analysis provides an error bound which decreases with the network depth to a minimum and then increases, verifying theoretically a trade-off phenomenon observed for network depths in many practical applications.