 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk-Sensitive Policy with Distributional Reinforcement Learning
Dec 30, 2022



Classical reinforcement learning (RL) techniques are generally concerned with the design of decision-making policies driven by the maximisation of the expected outcome. Nevertheless, this approach does not take into consideration the potential risk associated with the actions taken, which may be critical in certain applications. To address that issue, the present research work introduces a novel methodology based on distributional RL to derive sequential decision-making policies that are sensitive to the risk, the latter being modelled by the tail of the return probability distribution. The core idea is to replace the $Q$ function generally standing at the core of learning schemes in RL by another function taking into account both the expected return and the risk. Named the risk-based utility function $U$, it can be extracted from the random return distribution $Z$ naturally learnt by any distributional RL algorithm. This enables to span the complete potential trade-off between risk minimisation and expected return maximisation, in contrast to fully risk-averse methodologies. Fundamentally, this research yields a truly practical and accessible solution for learning risk-sensitive policies with minimal modification to the distributional RL algorithm, and with an emphasis on the interpretability of the resulting decision-making process.
Distributional Reinforcement Learning with Unconstrained Monotonic Neural Networks
Jun 06, 2021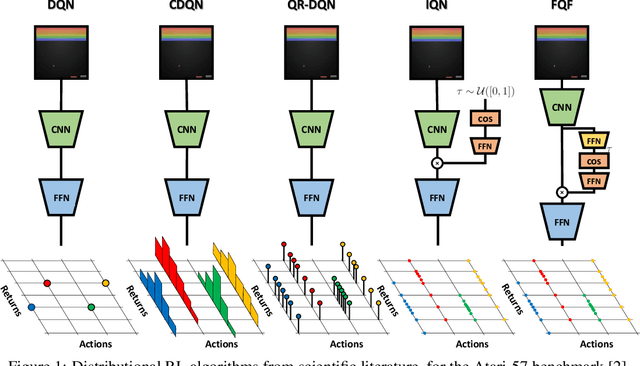



The distributional reinforcement learning (RL) approach advocates for representing the complete probability distribution of the random return instead of only modelling its expectation. A distributional RL algorithm may be characterised by two main components, namely the representation and parameterisation of the distribution and the probability metric defining the loss. This research considers the unconstrained monotonic neural network (UMNN) architecture, a universal approximator of continuous monotonic functions which is particularly well suited for modelling different representations of a distribution (PDF, CDF, quantile function). This property enables the decoupling of the effect of the function approximator class from that of the probability metric. The paper firstly introduces a methodology for learning different representations of the random return distribution. Secondly, a novel distributional RL algorithm named unconstrained monotonic deep Q-network (UMDQN) is presented. Lastly, in light of this new algorithm, an empirical comparison is performed between three probability quasimetrics, namely the Kullback-Leibler divergence, Cramer distance and Wasserstein distance. The results call for a reconsideration of all probability metrics in distributional RL, which contrasts with the dominance of the Wasserstein distance in recent publications.
An Artificial Intelligence Solution for Electricity Procurement in Forward Markets
Jun 10, 2020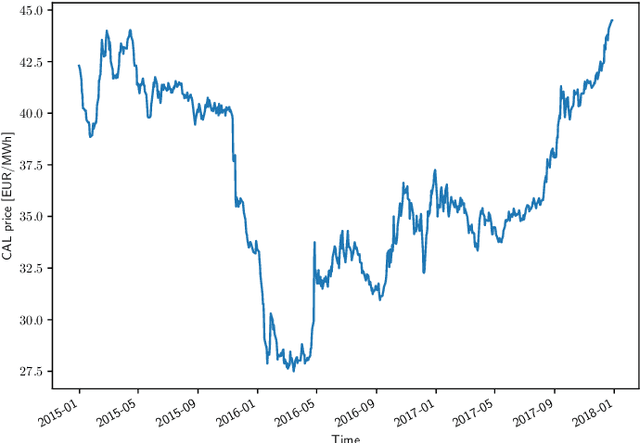

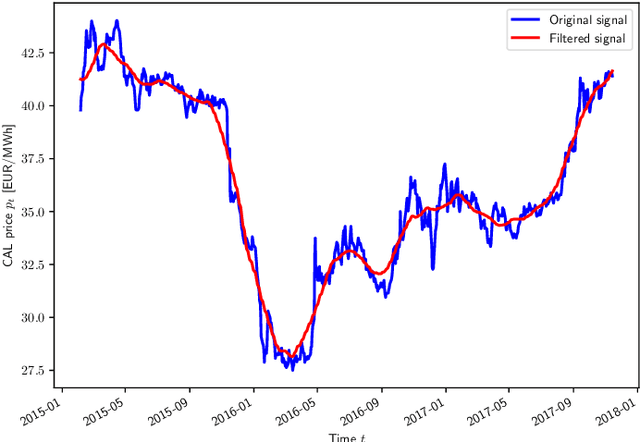
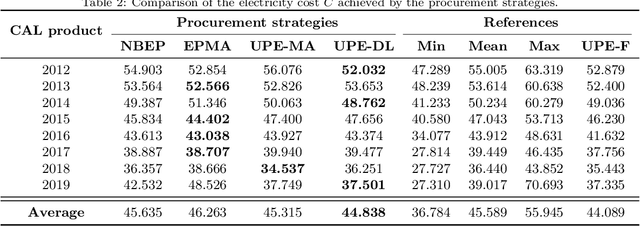
Retailers and major consumers of electricity generally purchase a critical percentage of their estimated electricity needs years ahead on the forward markets. This long-term electricity procurement task consists of determining when to buy electricity so that the resulting energy cost is minimised, and the forecast consumption is covered. In this scientific article, the focus is set on a yearly base load product, named calendar (CAL), which is tradable up to three years ahead of the delivery period. This research paper introduces a novel algorithm providing recommendations to either buy electricity now or wait for a future opportunity based on the history of CAL prices. This algorithm relies on deep learning forecasting techniques and on an indicator quantifying the deviation from a perfectly uniform reference procurement strategy. Basically, a new purchase operation is advised when this mathematical indicator hits the trigger associated with the market direction predicted by the forecaster. On average, the proposed approach surpasses benchmark procurement strategies and achieves a reduction in costs of 1.65% with respect to the perfectly uniform reference procurement strategy achieving the mean electricity price. Moreover, in addition to automating the electricity procurement task, this algorithm demonstrates more consistent results throughout the years compared to the benchmark strategies.
A Deep Reinforcement Learning Framework for Continuous Intraday Market Bidding
Apr 13, 2020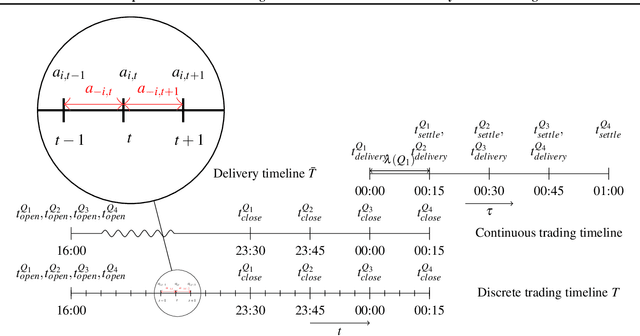

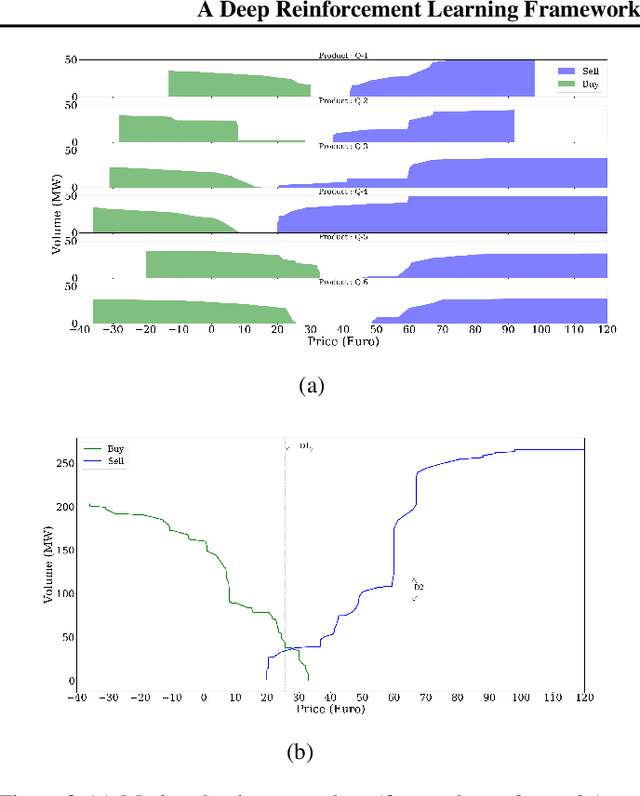

The large integration of variable energy resources is expected to shift a large part of the energy exchanges closer to real-time, where more accurate forecasts are available. In this context, the short-term electricity markets and in particular the intraday market are considered a suitable trading floor for these exchanges to occur. A key component for the successful renewable energy sources integration is the usage of energy storage. In this paper, we propose a novel modelling framework for the strategic participation of energy storage in the European continuous intraday market where exchanges occur through a centralized order book. The goal of the storage device operator is the maximization of the profits received over the entire trading horizon, while taking into account the operational constraints of the unit. The sequential decision-making problem of trading in the intraday market is modelled as a Markov Decision Process. An asynchronous distributed version of the fitted Q iteration algorithm is chosen for solving this problem due to its sample efficiency. The large and variable number of the existing orders in the order book motivates the use of high-level actions and an alternative state representation. Historical data are used for the generation of a large number of artificial trajectories in order to address exploration issues during the learning process. The resulting policy is back-tested and compared against a benchmark strategy that is the current industrial standard. Results indicate that the agent converges to a policy that achieves in average higher total revenues than the benchmark strategy.
An Application of Deep Reinforcement Learning to Algorithmic Trading
Apr 07, 2020



This scientific research paper presents an innovative approach based on deep reinforcement learning (DRL) to solve the algorithmic trading problem of determining the optimal trading position at any point in time during a trading activity in stock markets. It proposes a novel DRL trading strategy so as to maximise the resulting Sharpe ratio performance indicator on a broad range of stock markets. Denominated the Trading Deep Q-Network algorithm (TDQN), this new trading strategy is inspired from the popular DQN algorithm and significantly adapted to the specific algorithmic trading problem at hand. The training of the resulting reinforcement learning (RL) agent is entirely based on the generation of artificial trajectories from a limited set of stock market historical data. In order to objectively assess the performance of trading strategies, the research paper also proposes a novel, more rigorous performance assessment methodology. Following this new performance assessment approach, promising results are reported for the TDQN strategy.