 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Forecasting of Imbalance Prices in the Belgian Context
Jun 09, 2021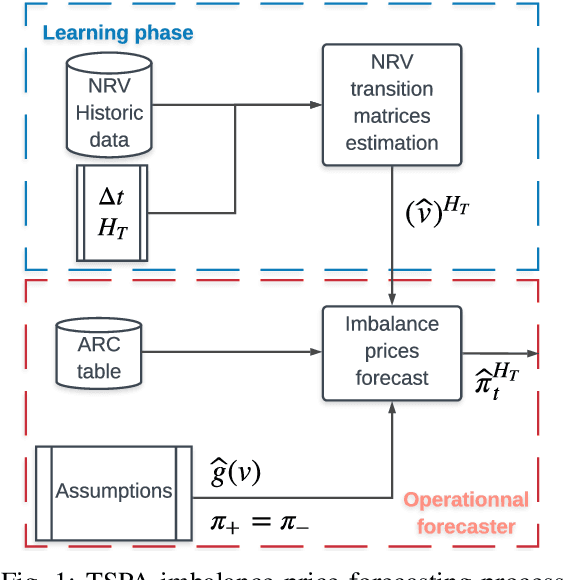
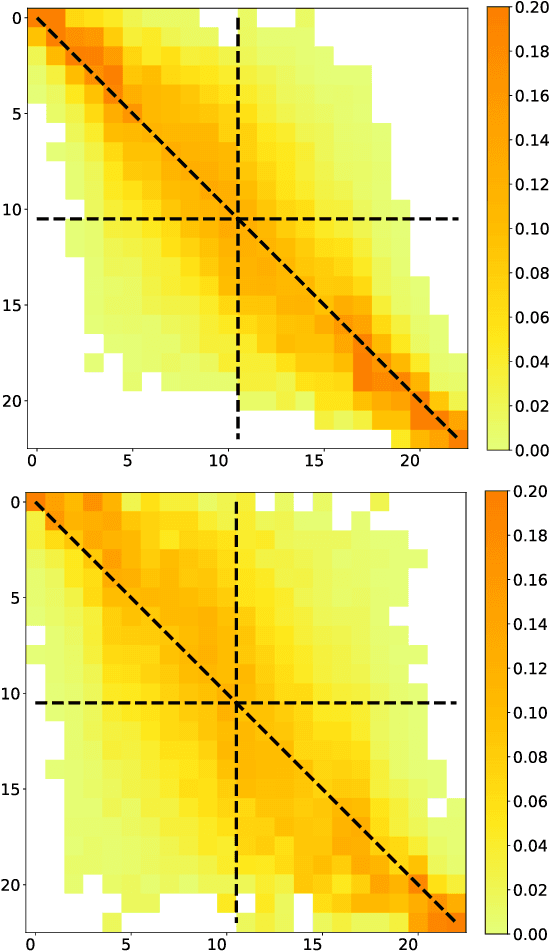

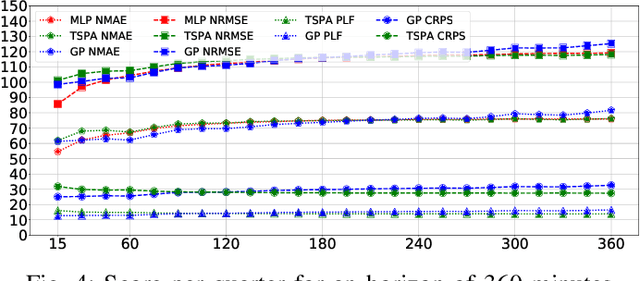
Forecasting imbalance prices is essential for strategic participation in the short-term energy markets. A novel two-step probabilistic approach is proposed, with a particular focus on the Belgian case. The first step consists of computing the net regulation volume state transition probabilities. It is modeled as a matrix computed using historical data. This matrix is then used to infer the imbalance prices since the net regulation volume can be related to the level of reserves activated and the corresponding marginal prices for each activation level are published by the Belgian Transmission System Operator one day before electricity delivery. This approach is compared to a deterministic model, a multi-layer perceptron, and a widely used probabilistic technique, Gaussian Processes.
Learning optimal environments using projected stochastic gradient ascent
Jun 02, 2020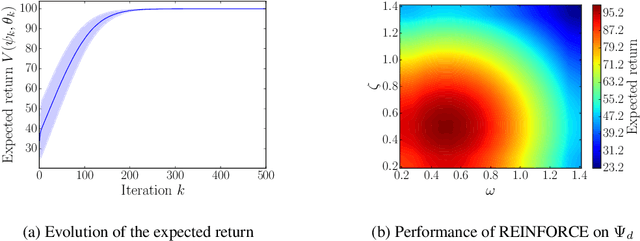

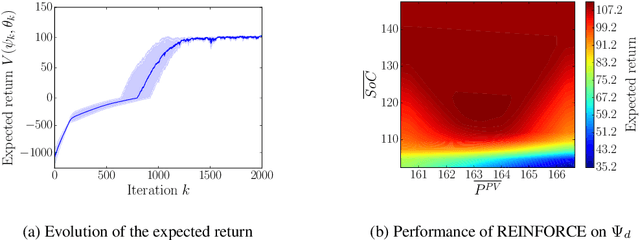
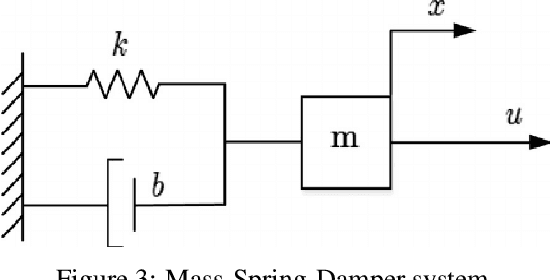
In this work, we generalize the direct policy search algorithms to an algorithm we call Direct Environment Search with (projected stochastic) Gradient Ascent (DESGA). The latter can be used to jointly learn a reinforcement learning (RL) environment and a policy with maximal expected return over a joint hypothesis space of environments and policies. We illustrate the performance of DESGA on two benchmarks. First, we consider a parametrized space of Mass-Spring-Damper (MSD) environments. Then, we use our algorithm for optimizing the size of the components and the operation of a small-scale and autonomous energy system, i.e. a solar off-grid microgrid, composed of photovoltaic panels, batteries, etc. The results highlight the excellent performances of the DESGA algorithm.
Lifelong Control of Off-grid Microgrid with Model Based Reinforcement Learning
May 16, 2020
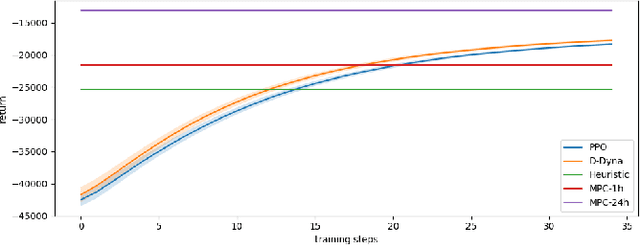
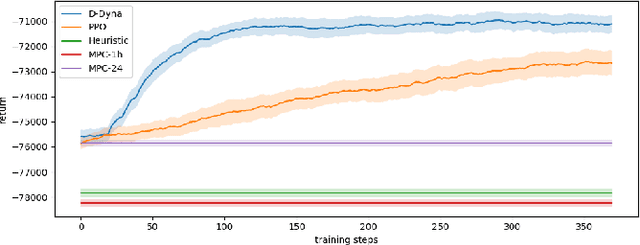
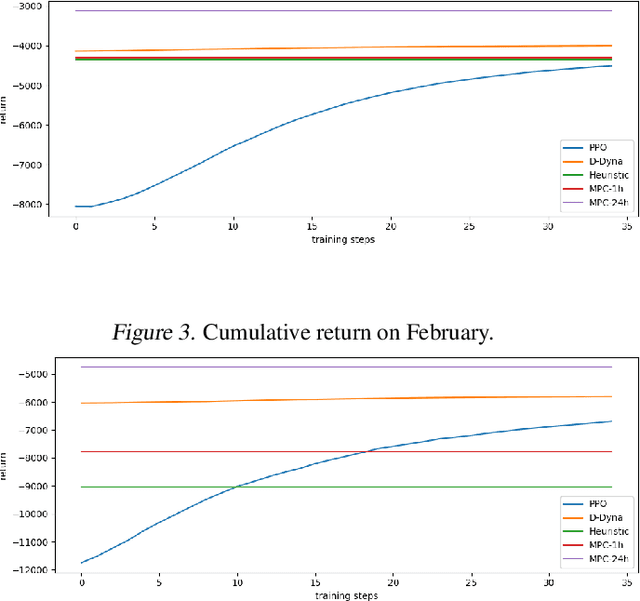
The lifelong control problem of an off-grid microgrid is composed of two tasks, namely estimation of the condition of the microgrid devices and operational planning accounting for the uncertainties by forecasting the future consumption and the renewable production. The main challenge for the effective control arises from the various changes that take place over time. In this paper, we present an open-source reinforcement framework for the modeling of an off-grid microgrid for rural electrification. The lifelong control problem of an isolated microgrid is formulated as a Markov Decision Process (MDP). We categorize the set of changes that can occur in progressive and abrupt changes. We propose a novel model based reinforcement learning algorithm that is able to address both types of changes. In particular the proposed algorithm demonstrates generalisation properties, transfer capabilities and better robustness in case of fast-changing system dynamics. The proposed algorithm is compared against a rule-based policy and a model predictive controller with look-ahead. The results show that the trained agent is able to outperform both benchmarks in the lifelong setting where the system dynamics are changing over time.
A Deep Reinforcement Learning Framework for Continuous Intraday Market Bidding
Apr 13, 2020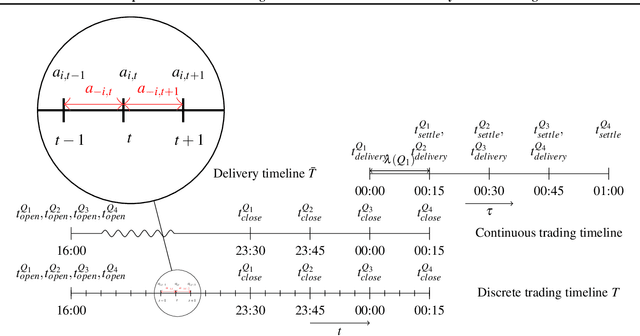

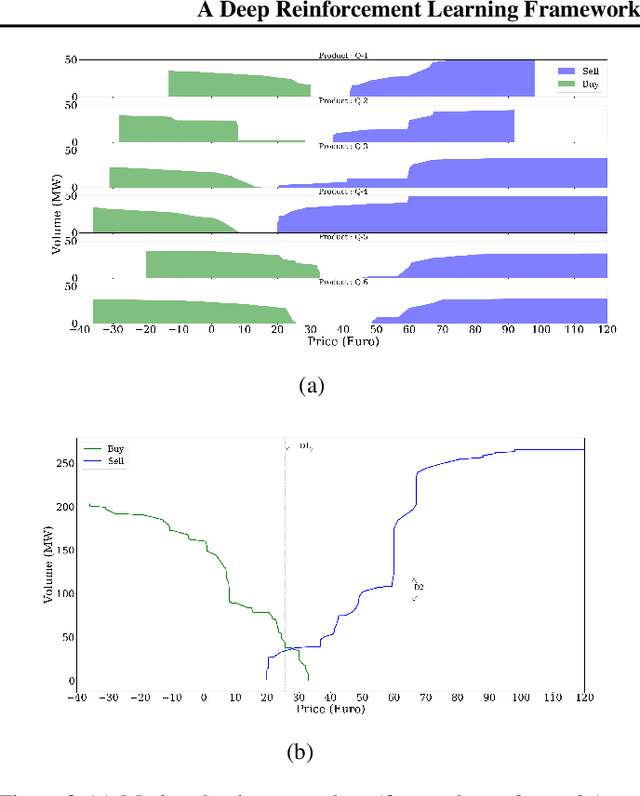

The large integration of variable energy resources is expected to shift a large part of the energy exchanges closer to real-time, where more accurate forecasts are available. In this context, the short-term electricity markets and in particular the intraday market are considered a suitable trading floor for these exchanges to occur. A key component for the successful renewable energy sources integration is the usage of energy storage. In this paper, we propose a novel modelling framework for the strategic participation of energy storage in the European continuous intraday market where exchanges occur through a centralized order book. The goal of the storage device operator is the maximization of the profits received over the entire trading horizon, while taking into account the operational constraints of the unit. The sequential decision-making problem of trading in the intraday market is modelled as a Markov Decision Process. An asynchronous distributed version of the fitted Q iteration algorithm is chosen for solving this problem due to its sample efficiency. The large and variable number of the existing orders in the order book motivates the use of high-level actions and an alternative state representation. Historical data are used for the generation of a large number of artificial trajectories in order to address exploration issues during the learning process. The resulting policy is back-tested and compared against a benchmark strategy that is the current industrial standard. Results indicate that the agent converges to a policy that achieves in average higher total revenues than the benchmark strategy.