 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Expanded Massive Multilingual Dataset for High-Performance Language Technologies
Mar 13, 2025Training state-of-the-art large language models requires vast amounts of clean and diverse textual data. However, building suitable multilingual datasets remains a challenge. In this work, we present HPLT v2, a collection of high-quality multilingual monolingual and parallel corpora. The monolingual portion of the data contains 8T tokens covering 193 languages, while the parallel data contains 380M sentence pairs covering 51 languages. We document the entire data pipeline and release the code to reproduce it. We provide extensive analysis of the quality and characteristics of our data. Finally, we evaluate the performance of language models and machine translation systems trained on HPLT v2, demonstrating its value.
SAO WMT19 Test Suite: Machine Translation of Audit Reports
Sep 04, 2019


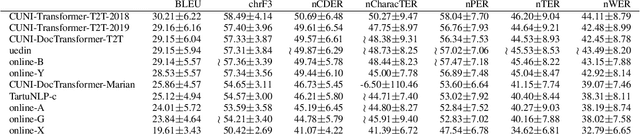
This paper describes a machine translation test set of documents from the auditing domain and its use as one of the "test suites" in the WMT19 News Translation Task for translation directions involving Czech, English and German. Our evaluation suggests that current MT systems optimized for the general news domain can perform quite well even in the particular domain of audit reports. The detailed manual evaluation however indicates that deep factual knowledge of the domain is necessary. For the naked eye of a non-expert, translations by many systems seem almost perfect and automatic MT evaluation with one reference is practically useless for considering these details. Furthermore, we show on a sample document from the domain of agreements that even the best systems completely fail in preserving the semantics of the agreement, namely the identity of the parties.
* WMT19 (http://www.statmt.org/wmt19/)
A Speech Test Set of Practice Business Presentations with Additional Relevant Texts
Aug 02, 2019



We present a test corpus of audio recordings and transcriptions of presentations of students' enterprises together with their slides and web-pages. The corpus is intended for evaluation of automatic speech recognition (ASR) systems, especially in conditions where the prior availability of in-domain vocabulary and named entities is benefitable. The corpus consists of 39 presentations in English, each up to 90 seconds long. The speakers are high school students from European countries with English as their second language. We benchmark three baseline ASR systems on the corpus and show their imperfection.