 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Point-of-Care Ultrasound Video Acquisition for Probabilistic Multi-Task Heart Failure Detection
Feb 14, 2026Purpose: Echocardiography with point-of-care ultrasound (POCUS) must support clinical decision-making under tight bedside time and operator-effort constraints. We introduce a personalized data acquisition strategy in which an RL agent, given a partially observed multi-view study, selects the next view to acquire or terminates acquisition to support heart-failure (HF) assessment. Upon termination, a diagnostic model jointly predicts aortic stenosis (AS) severity and left ventricular ejection fraction (LVEF), two key HF biomarkers, and outputs uncertainty, enabling an explicit trade-off between diagnostic performance and acquisition cost. Methods: We model POCUS as a sequential acquisition problem: at each step, a video selector (RL agent) chooses the next view to acquire or terminates acquisition. Upon termination, a shared multi-view transformer performs multi-task inference with two heads, ordinal AS classification, and LVEF regression, and outputs Gaussian predictive distributions yielding ordinal probabilities over AS classes and EF thresholds. These probabilities drive a reward that balances expected diagnostic benefit against acquisition cost, producing patient-specific acquisition pathways. Results: The dataset comprises 12,180 patient-level studies, split into training/validation/test sets (75/15/15). On the 1,820 test studies, our method matches full-study performance while using 32% fewer videos, achieving 77.2% mean balanced accuracy (bACC) across AS severity classification and LVEF estimation, demonstrating robust multi-task performance under acquisition budgets. Conclusion: Patient-tailored, cost-aware acquisition can streamline POCUS workflows while preserving decision quality, producing interpretable scan pathways suited to bedside use. The framework is extensible to additional cardiac endpoints and merits prospective evaluation for clinical integration.
EchoAgent: Guideline-Centric Reasoning Agent for Echocardiography Measurement and Interpretation
Nov 17, 2025Purpose: Echocardiographic interpretation requires video-level reasoning and guideline-based measurement analysis, which current deep learning models for cardiac ultrasound do not support. We present EchoAgent, a framework that enables structured, interpretable automation for this domain. Methods: EchoAgent orchestrates specialized vision tools under Large Language Model (LLM) control to perform temporal localization, spatial measurement, and clinical interpretation. A key contribution is a measurement-feasibility prediction model that determines whether anatomical structures are reliably measurable in each frame, enabling autonomous tool selection. We curated a benchmark of diverse, clinically validated video-query pairs for evaluation. Results: EchoAgent achieves accurate, interpretable results despite added complexity of spatiotemporal video analysis. Outputs are grounded in visual evidence and clinical guidelines, supporting transparency and traceability. Conclusion: This work demonstrates the feasibility of agentic, guideline-aligned reasoning for echocardiographic video analysis, enabled by task-specific tools and full video-level automation. EchoAgent sets a new direction for trustworthy AI in cardiac ultrasound.
GEMTrans: A General, Echocardiography-based, Multi-Level Transformer Framework for Cardiovascular Diagnosis
Aug 25, 2023

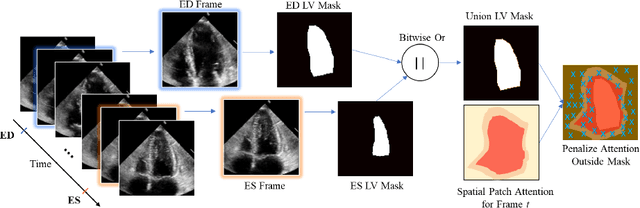
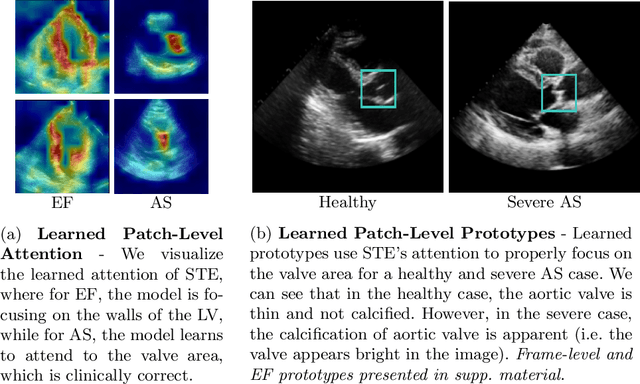
Echocardiography (echo) is an ultrasound imaging modality that is widely used for various cardiovascular diagnosis tasks. Due to inter-observer variability in echo-based diagnosis, which arises from the variability in echo image acquisition and the interpretation of echo images based on clinical experience, vision-based machine learning (ML) methods have gained popularity to act as secondary layers of verification. For such safety-critical applications, it is essential for any proposed ML method to present a level of explainability along with good accuracy. In addition, such methods must be able to process several echo videos obtained from various heart views and the interactions among them to properly produce predictions for a variety of cardiovascular measurements or interpretation tasks. Prior work lacks explainability or is limited in scope by focusing on a single cardiovascular task. To remedy this, we propose a General, Echo-based, Multi-Level Transformer (GEMTrans) framework that provides explainability, while simultaneously enabling multi-video training where the inter-play among echo image patches in the same frame, all frames in the same video, and inter-video relationships are captured based on a downstream task. We show the flexibility of our framework by considering two critical tasks including ejection fraction (EF) and aortic stenosis (AS) severity detection. Our model achieves mean absolute errors of 4.15 and 4.84 for single and dual-video EF estimation and an accuracy of 96.5 % for AS detection, while providing informative task-specific attention maps and prototypical explainability.
ProtoASNet: Dynamic Prototypes for Inherently Interpretable and Uncertainty-Aware Aortic Stenosis Classification in Echocardiography
Jul 26, 2023


Aortic stenosis (AS) is a common heart valve disease that requires accurate and timely diagnosis for appropriate treatment. Most current automatic AS severity detection methods rely on black-box models with a low level of trustworthiness, which hinders clinical adoption. To address this issue, we propose ProtoASNet, a prototypical network that directly detects AS from B-mode echocardiography videos, while making interpretable predictions based on the similarity between the input and learned spatio-temporal prototypes. This approach provides supporting evidence that is clinically relevant, as the prototypes typically highlight markers such as calcification and restricted movement of aortic valve leaflets. Moreover, ProtoASNet utilizes abstention loss to estimate aleatoric uncertainty by defining a set of prototypes that capture ambiguity and insufficient information in the observed data. This provides a reliable system that can detect and explain when it may fail. We evaluate ProtoASNet on a private dataset and the publicly available TMED-2 dataset, where it outperforms existing state-of-the-art methods with an accuracy of 80.0% and 79.7%, respectively. Furthermore, ProtoASNet provides interpretability and an uncertainty measure for each prediction, which can improve transparency and facilitate the interactive usage of deep networks to aid clinical decision-making. Our source code is available at: https://github.com/hooman007/ProtoASNet.
EchoGLAD: Hierarchical Graph Neural Networks for Left Ventricle Landmark Detection on Echocardiograms
Jul 23, 2023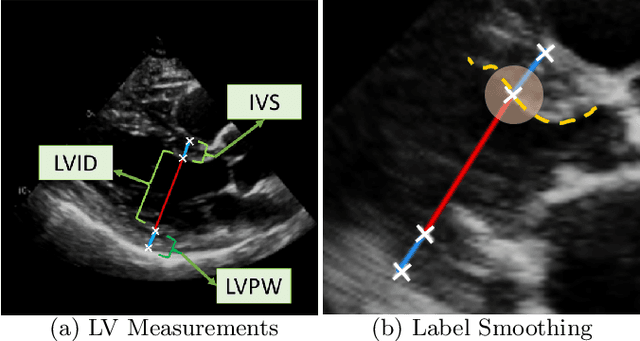
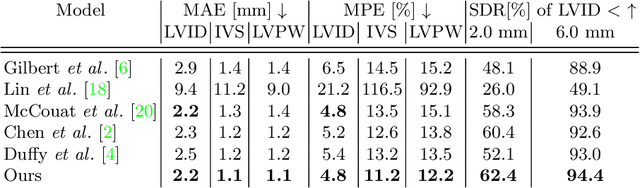
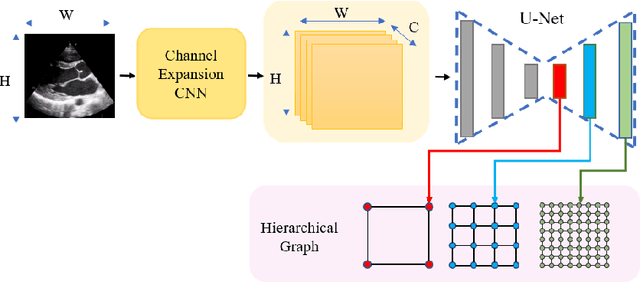
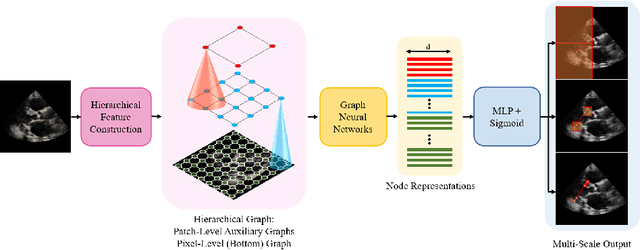
The functional assessment of the left ventricle chamber of the heart requires detecting four landmark locations and measuring the internal dimension of the left ventricle and the approximate mass of the surrounding muscle. The key challenge of automating this task with machine learning is the sparsity of clinical labels, i.e., only a few landmark pixels in a high-dimensional image are annotated, leading many prior works to heavily rely on isotropic label smoothing. However, such a label smoothing strategy ignores the anatomical information of the image and induces some bias. To address this challenge, we introduce an echocardiogram-based, hierarchical graph neural network (GNN) for left ventricle landmark detection (EchoGLAD). Our main contributions are: 1) a hierarchical graph representation learning framework for multi-resolution landmark detection via GNNs; 2) induced hierarchical supervision at different levels of granularity using a multi-level loss. We evaluate our model on a public and a private dataset under the in-distribution (ID) and out-of-distribution (OOD) settings. For the ID setting, we achieve the state-of-the-art mean absolute errors (MAEs) of 1.46 mm and 1.86 mm on the two datasets. Our model also shows better OOD generalization than prior works with a testing MAE of 4.3 mm.