 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoGLAD: Hierarchical Graph Neural Networks for Left Ventricle Landmark Detection on Echocardiograms
Jul 23, 2023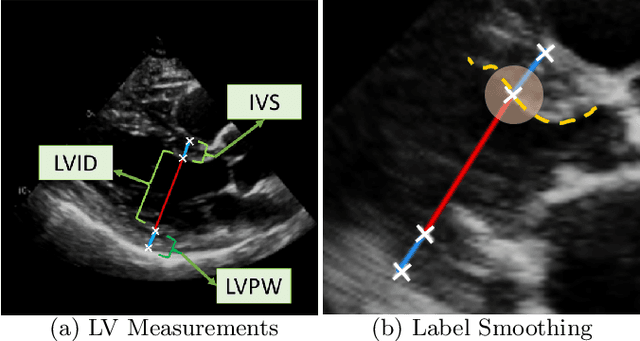
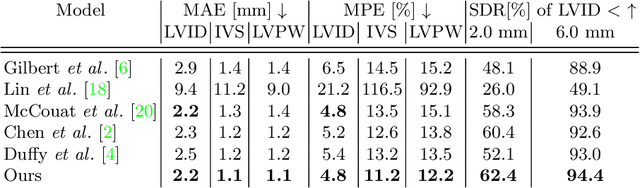
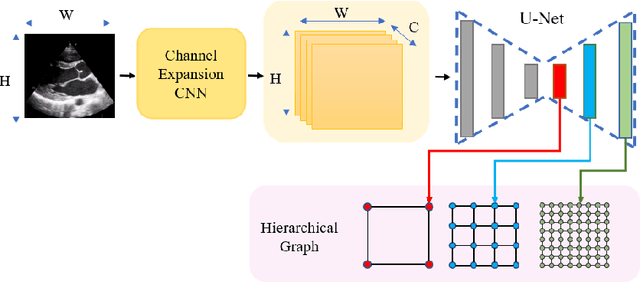
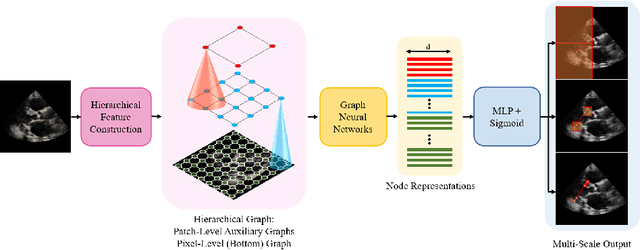
The functional assessment of the left ventricle chamber of the heart requires detecting four landmark locations and measuring the internal dimension of the left ventricle and the approximate mass of the surrounding muscle. The key challenge of automating this task with machine learning is the sparsity of clinical labels, i.e., only a few landmark pixels in a high-dimensional image are annotated, leading many prior works to heavily rely on isotropic label smoothing. However, such a label smoothing strategy ignores the anatomical information of the image and induces some bias. To address this challenge, we introduce an echocardiogram-based, hierarchical graph neural network (GNN) for left ventricle landmark detection (EchoGLAD). Our main contributions are: 1) a hierarchical graph representation learning framework for multi-resolution landmark detection via GNNs; 2) induced hierarchical supervision at different levels of granularity using a multi-level loss. We evaluate our model on a public and a private dataset under the in-distribution (ID) and out-of-distribution (OOD) settings. For the ID setting, we achieve the state-of-the-art mean absolute errors (MAEs) of 1.46 mm and 1.86 mm on the two datasets. Our model also shows better OOD generalization than prior works with a testing MAE of 4.3 mm.
Pointwise Attention-Based Atrous Convolutional Neural Networks
Dec 27, 2019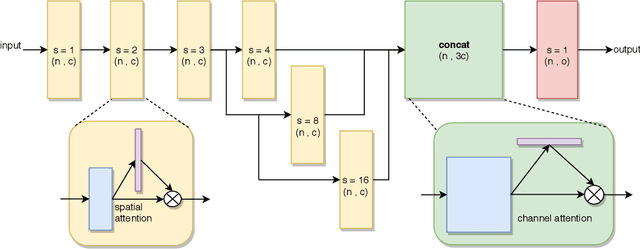
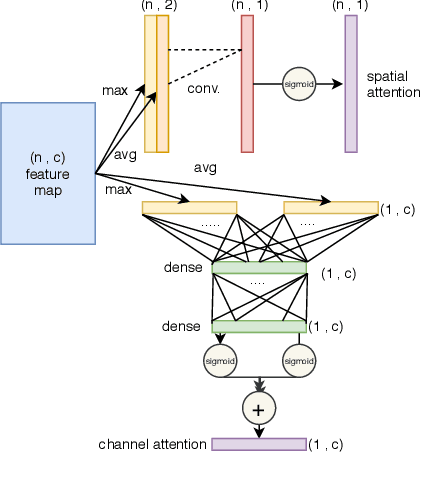
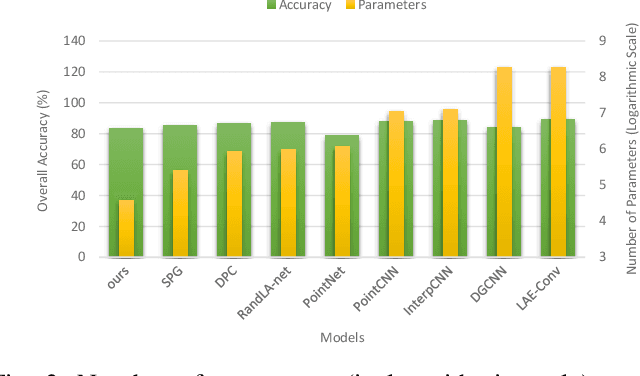
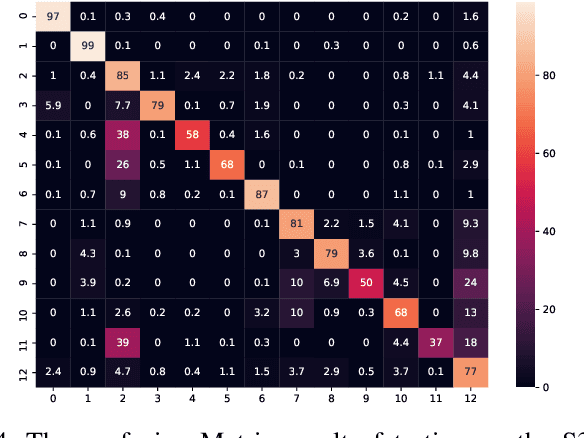
With the rapid progress of deep convolutional neural networks, in almost all robotic applications, the availability of 3D point clouds improves the accuracy of 3D semantic segmentation methods. Rendering of these irregular, unstructured, and unordered 3D points to 2D images from multiple viewpoints imposes some issues such as loss of information due to 3D to 2D projection, discretizing artifacts, and high computational costs. To efficiently deal with a large number of points and incorporate more context of each point, a pointwise attention-based atrous convolutional neural network architecture is proposed. It focuses on salient 3D feature points among all feature maps while considering outstanding contextual information via spatial channel-wise attention modules. The proposed model has been evaluated on the two most important 3D point cloud datasets for the 3D semantic segmentation task. It achieves a reasonable performance compared to state-of-the-art models in terms of accuracy, with a much smaller number of parameters.