 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiased or Limited: Modeling Sub-Rational Human Investors in Financial Markets
Oct 16, 2022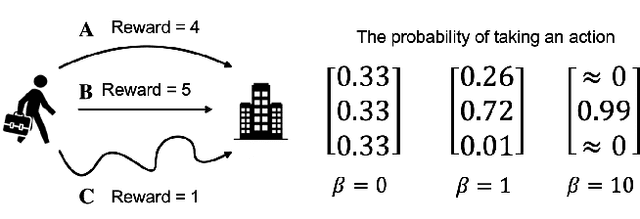
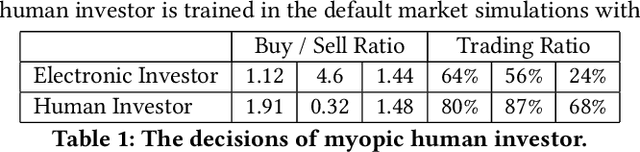
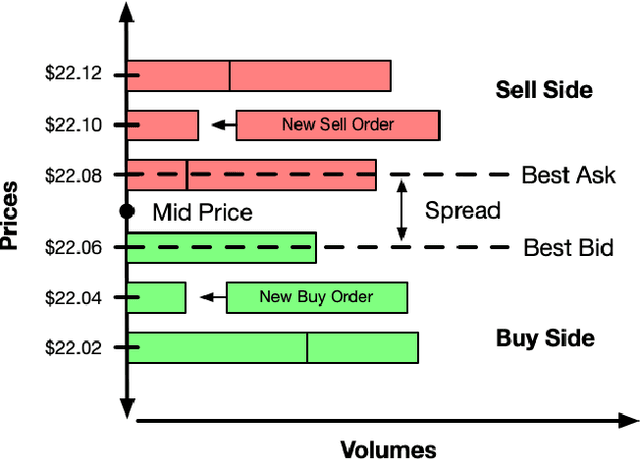
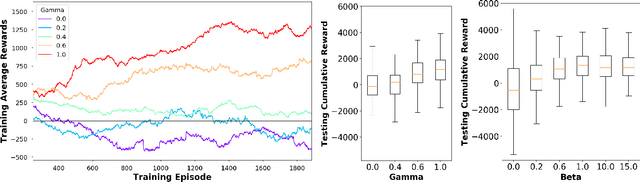
Multi-agent market simulation is an effective tool to investigate the impact of various trading strategies in financial markets. One way of designing a trading agent in simulated markets is through reinforcement learning where the agent is trained to optimize its cumulative rewards (e.g., maximizing profits, minimizing risk, improving equitability). While the agent learns a rational policy that optimizes the reward function, in reality, human investors are sub-rational with their decisions often differing from the optimal. In this work, we model human sub-rationality as resulting from two possible causes: psychological bias and computational limitation. We first examine the relationship between investor profits and their degree of sub-rationality, and create hand-crafted market scenarios to intuitively explain the sub-rational human behaviors. Through experiments, we show that our models successfully capture human sub-rationality as observed in the behavioral finance literature. We also examine the impact of sub-rational human investors on market observables such as traded volumes, spread and volatility. We believe our work will benefit research in behavioral finance and provide a better understanding of human trading behavior.
Optimal Stopping with Gaussian Processes
Oct 07, 2022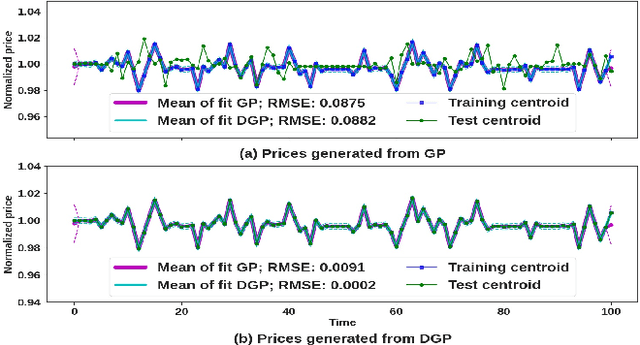
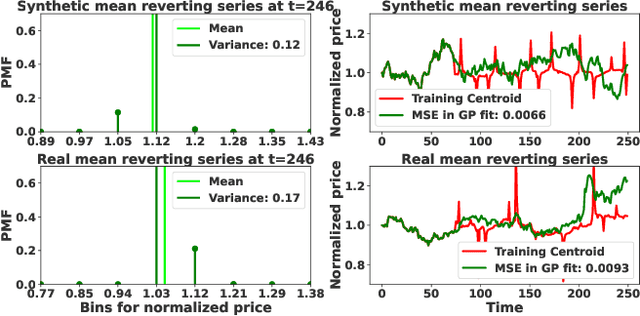
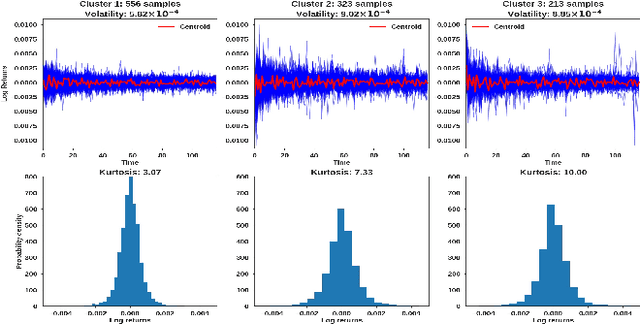
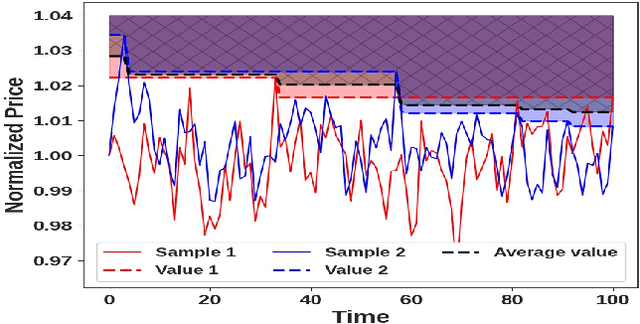
We propose a novel group of Gaussian Process based algorithms for fast approximate optimal stopping of time series with specific applications to financial markets. We show that structural properties commonly exhibited by financial time series (e.g., the tendency to mean-revert) allow the use of Gaussian and Deep Gaussian Process models that further enable us to analytically evaluate optimal stopping value functions and policies. We additionally quantify uncertainty in the value function by propagating the price model through the optimal stopping analysis. We compare and contrast our proposed methods against a sampling-based method, as well as a deep learning based benchmark that is currently considered the state-of-the-art in the literature. We show that our family of algorithms outperforms benchmarks on three historical time series datasets that include intra-day and end-of-day equity stock prices as well as the daily US treasury yield curve rates.
Equitable Marketplace Mechanism Design
Sep 22, 2022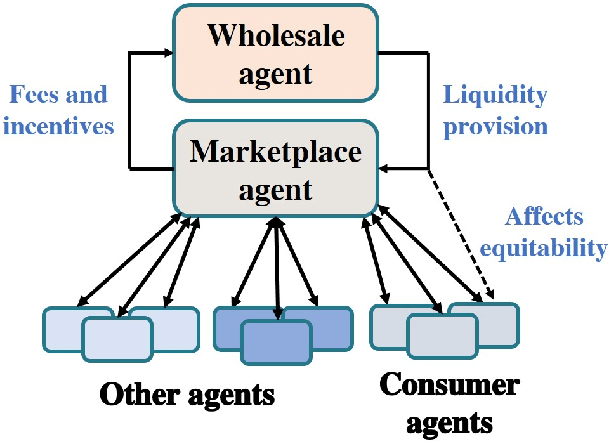
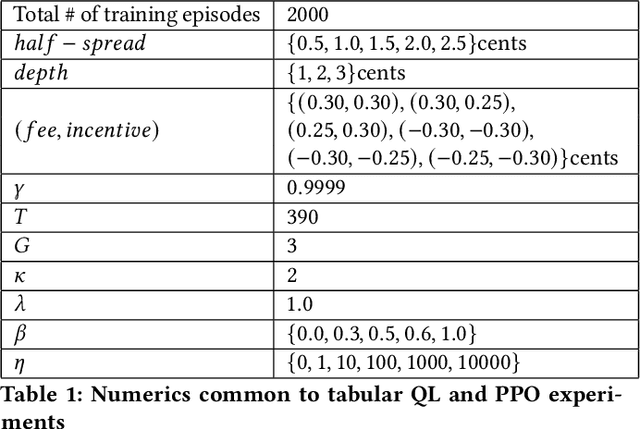
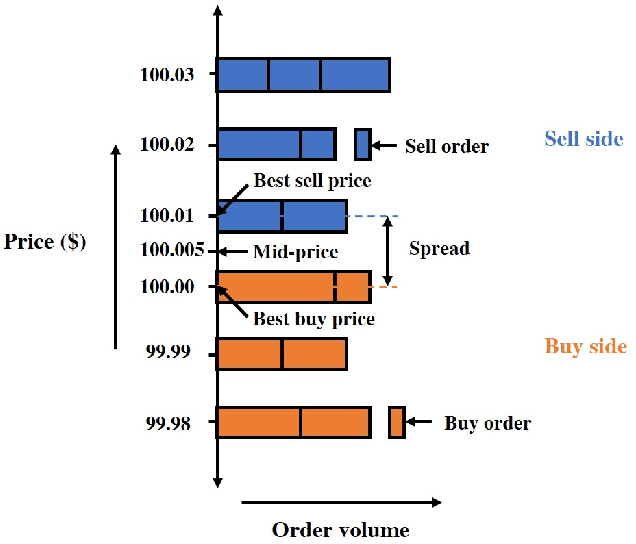
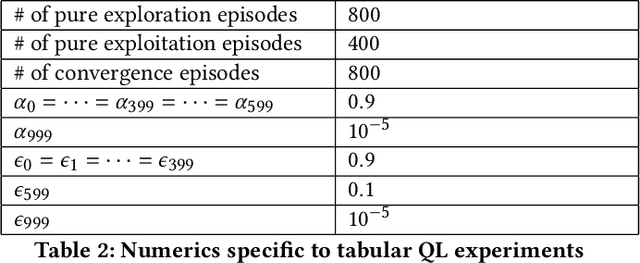
We consider a trading marketplace that is populated by traders with diverse trading strategies and objectives. The marketplace allows the suppliers to list their goods and facilitates matching between buyers and sellers. In return, such a marketplace typically charges fees for facilitating trade. The goal of this work is to design a dynamic fee schedule for the marketplace that is equitable and profitable to all traders while being profitable to the marketplace at the same time (from charging fees). Since the traders adapt their strategies to the fee schedule, we present a reinforcement learning framework for simultaneously learning a marketplace fee schedule and trading strategies that adapt to this fee schedule using a weighted optimization objective of profits and equitability. We illustrate the use of the proposed approach in detail on a simulated stock exchange with different types of investors, specifically market makers and consumer investors. As we vary the equitability weights across different investor classes, we see that the learnt exchange fee schedule starts favoring the class of investors with the highest weight. We further discuss the observed insights from the simulated stock exchange in light of the general framework of equitable marketplace mechanism design.
Similarity metrics for Different Market Scenarios in Abides
Jul 20, 2021
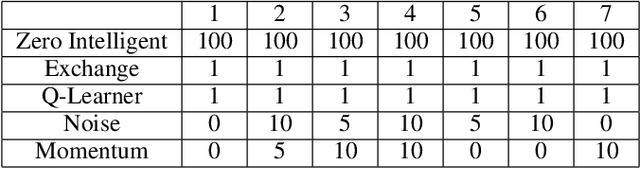
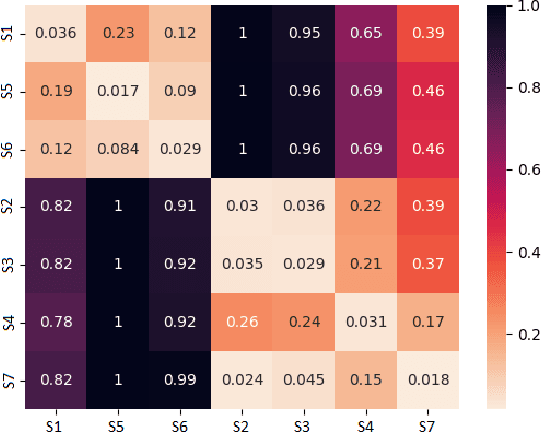
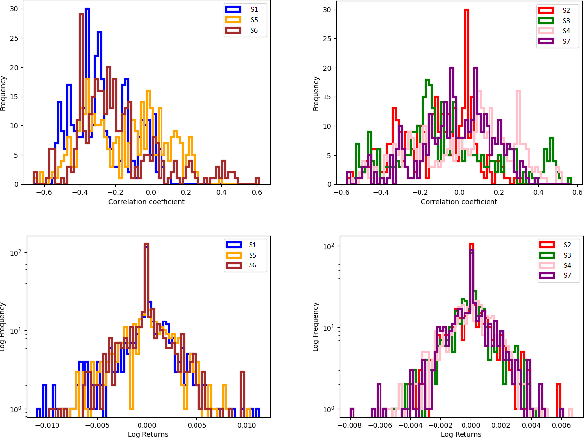
Markov Decision Processes (MDPs) are an effective way to formally describe many Machine Learning problems. In fact, recently MDPs have also emerged as a powerful framework to model financial trading tasks. For example, financial MDPs can model different market scenarios. However, the learning of a (near-)optimal policy for each of these financial MDPs can be a very time-consuming process, especially when nothing is known about the policy to begin with. An alternative approach is to find a similar financial MDP for which we have already learned its policy, and then reuse such policy in the learning of a new policy for a new financial MDP. Such a knowledge transfer between market scenarios raises several issues. On the one hand, how to measure the similarity between financial MDPs. On the other hand, how to use this similarity measurement to effectively transfer the knowledge between financial MDPs. This paper addresses both of these issues. Regarding the first one, this paper analyzes the use of three similarity metrics based on conceptual, structural and performance aspects of the financial MDPs. Regarding the second one, this paper uses Probabilistic Policy Reuse to balance the exploitation/exploration in the learning of a new financial MDP according to the similarity of the previous financial MDPs whose knowledge is reused.