 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilarity metrics for Different Market Scenarios in Abides
Jul 20, 2021
Markov Decision Processes (MDPs) are an effective way to formally describe many Machine Learning problems. In fact, recently MDPs have also emerged as a powerful framework to model financial trading tasks. For example, financial MDPs can model different market scenarios. However, the learning of a (near-)optimal policy for each of these financial MDPs can be a very time-consuming process, especially when nothing is known about the policy to begin with. An alternative approach is to find a similar financial MDP for which we have already learned its policy, and then reuse such policy in the learning of a new policy for a new financial MDP. Such a knowledge transfer between market scenarios raises several issues. On the one hand, how to measure the similarity between financial MDPs. On the other hand, how to use this similarity measurement to effectively transfer the knowledge between financial MDPs. This paper addresses both of these issues. Regarding the first one, this paper analyzes the use of three similarity metrics based on conceptual, structural and performance aspects of the financial MDPs. Regarding the second one, this paper uses Probabilistic Policy Reuse to balance the exploitation/exploration in the learning of a new financial MDP according to the similarity of the previous financial MDPs whose knowledge is reused.
A Taxonomy of Similarity Metrics for Markov Decision Processes
Mar 08, 2021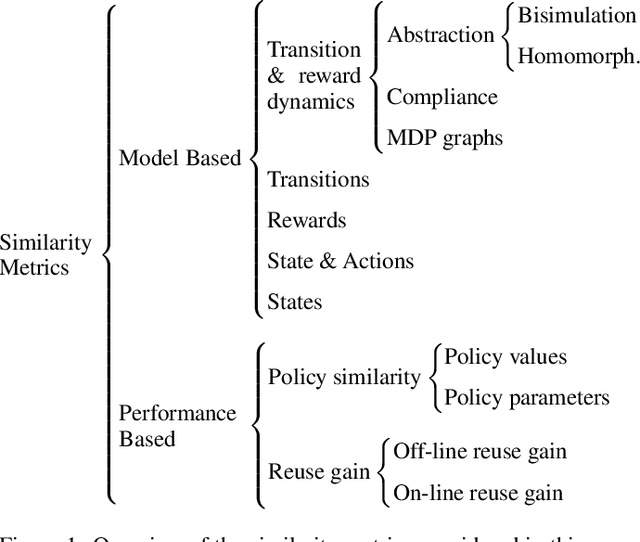
Although the notion of task similarity is potentially interesting in a wide range of areas such as curriculum learning or automated planning, it has mostly been tied to transfer learning. Transfer is based on the idea of reusing the knowledge acquired in the learning of a set of source tasks to a new learning process in a target task, assuming that the target and source tasks are close enough. In recent years, transfer learning has succeeded in making Reinforcement Learning (RL) algorithms more efficient (e.g., by reducing the number of samples needed to achieve the (near-)optimal performance). Transfer in RL is based on the core concept of similarity: whenever the tasks are similar, the transferred knowledge can be reused to solve the target task and significantly improve the learning performance. Therefore, the selection of good metrics to measure these similarities is a critical aspect when building transfer RL algorithms, especially when this knowledge is transferred from simulation to the real world. In the literature, there are many metrics to measure the similarity between MDPs, hence, many definitions of similarity or its complement distance have been considered. In this paper, we propose a categorization of these metrics and analyze the definitions of similarity proposed so far, taking into account such categorization. We also follow this taxonomy to survey the existing literature, as well as suggesting future directions for the construction of new metrics.
Disturbing Reinforcement Learning Agents with Corrupted Rewards
Feb 12, 2021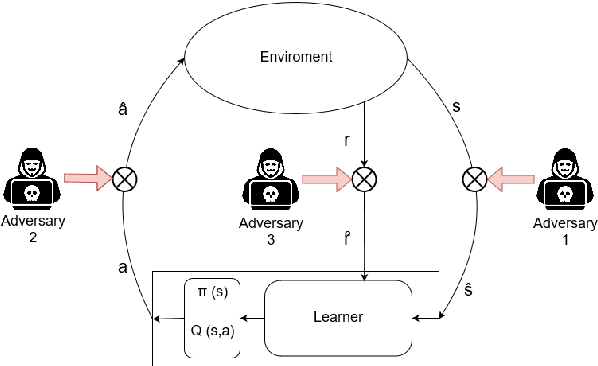
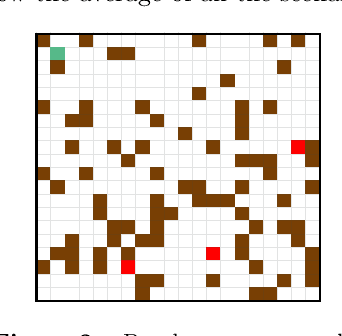

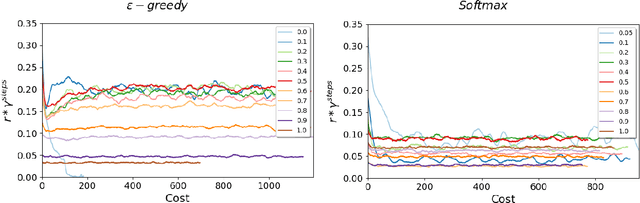
Reinforcement Learning (RL) algorithms have led to recent successes in solving complex games, such as Atari or Starcraft, and to a huge impact in real-world applications, such as cybersecurity or autonomous driving. In the side of the drawbacks, recent works have shown how the performance of RL algorithms decreases under the influence of soft changes in the reward function. However, little work has been done about how sensitive these disturbances are depending on the aggressiveness of the attack and the learning exploration strategy. In this paper, we propose to fill this gap in the literature analyzing the effects of different attack strategies based on reward perturbations, and studying the effect in the learner depending on its exploration strategy. In order to explain all the behaviors, we choose a sub-class of MDPs: episodic, stochastic goal-only-rewards MDPs, and in particular, an intelligible grid domain as a benchmark. In this domain, we demonstrate that smoothly crafting adversarial rewards are able to mislead the learner, and that using low exploration probability values, the policy learned is more robust to corrupt rewards. Finally, in the proposed learning scenario, a counterintuitive result arises: attacking at each learning episode is the lowest cost attack strategy.