 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal-and-local attention networks for visual recognition
Sep 06, 2018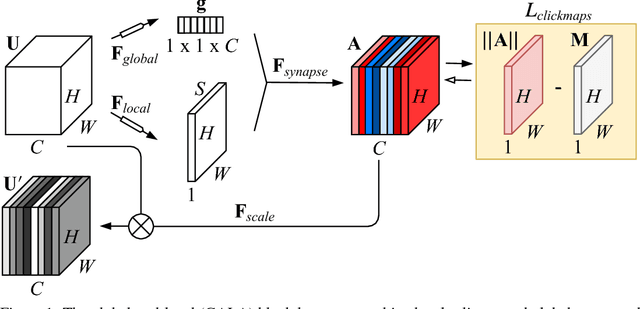
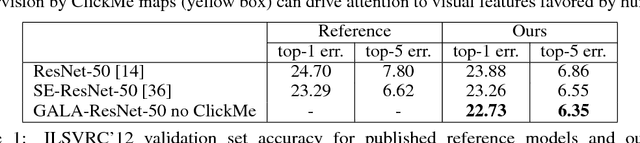

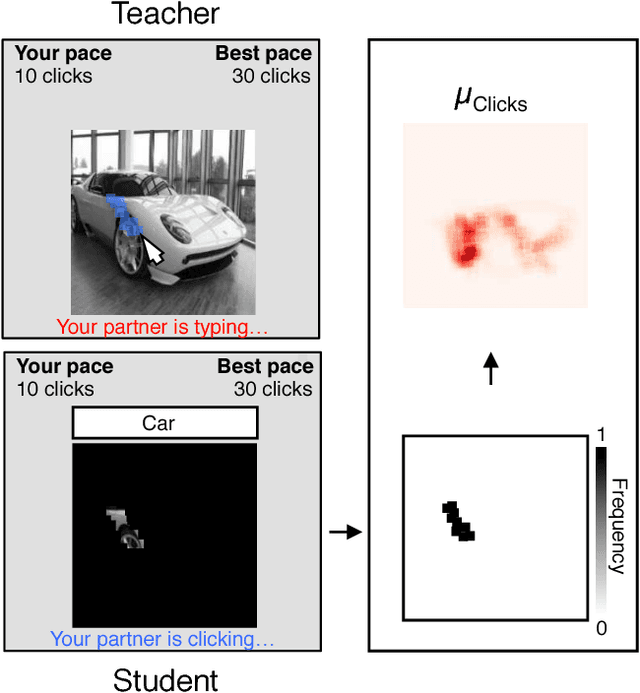
State-of-the-art deep convolutional networks (DCNs) such as squeeze-and- excitation (SE) residual networks implement a form of attention, also known as contextual guidance, which is derived from global image features. Here, we explore a complementary form of attention, known as visual saliency, which is derived from local image features. We extend the SE module with a novel global-and-local attention (GALA) module which combines both forms of attention -- resulting in state-of-the-art accuracy on ILSVRC. We further describe ClickMe.ai, a large-scale online experiment designed for human participants to identify diagnostic image regions to co-train a GALA network. Adding humans-in-the-loop is shown to significantly improve network accuracy, while also yielding visual features that are more interpretable and more similar to those used by human observers.
What are the visual features underlying human versus machine vision?
Nov 07, 2017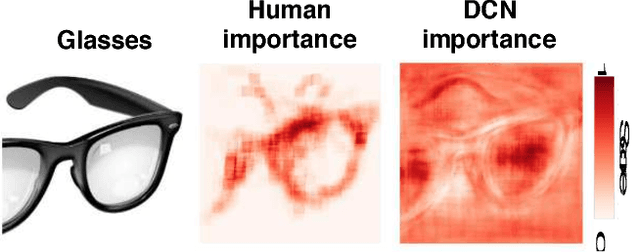

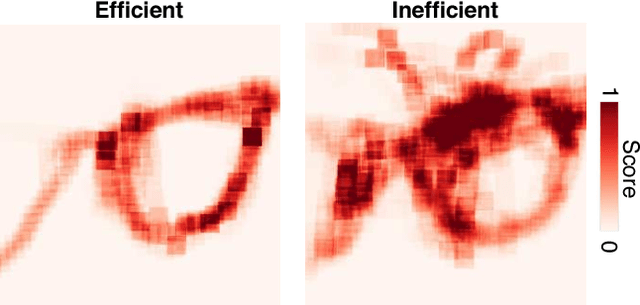
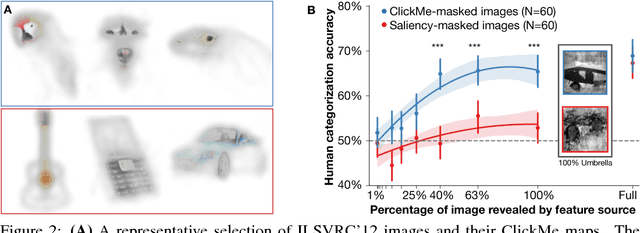
Although Deep Convolutional Networks (DCNs) are approaching the accuracy of human observers at object recognition, it is unknown whether they leverage similar visual representations to achieve this performance. To address this, we introduce Clicktionary, a web-based game for identifying visual features used by human observers during object recognition. Importance maps derived from the game are consistent across participants and uncorrelated with image saliency measures. These results suggest that Clicktionary identifies image regions that are meaningful and diagnostic for object recognition but different than those driving eye movements. Surprisingly, Clicktionary importance maps are only weakly correlated with relevance maps derived from DCNs trained for object recognition. Our study demonstrates that the narrowing gap between the object recognition accuracy of human observers and DCNs obscures distinct visual strategies used by each to achieve this performance.
How Deep is the Feature Analysis underlying Rapid Visual Categorization?
Jun 03, 2016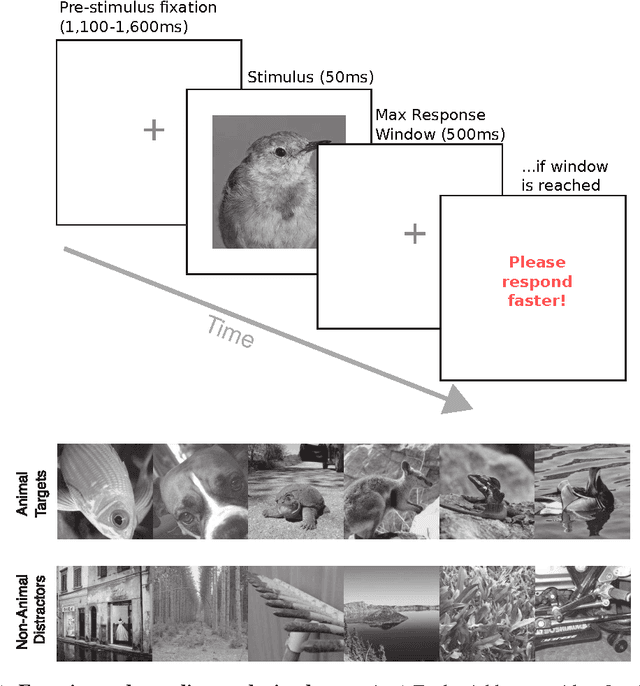
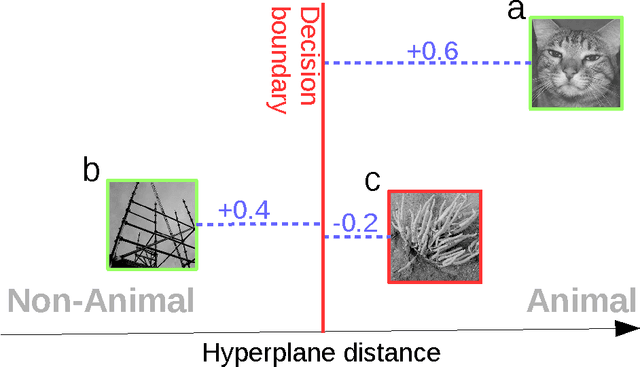
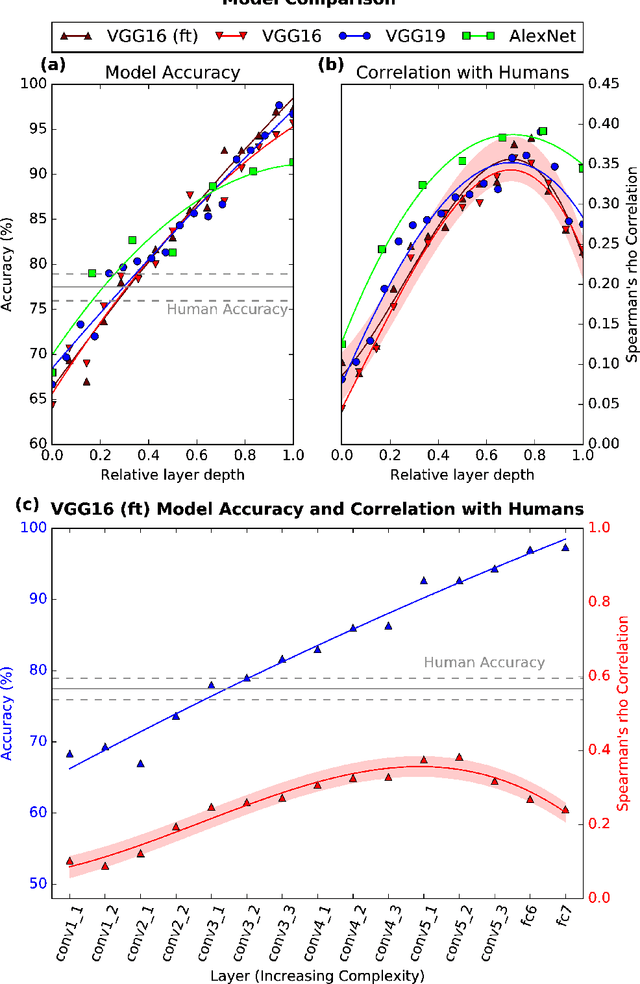

Rapid categorization paradigms have a long history in experimental psychology: Characterized by short presentation times and speedy behavioral responses, these tasks highlight the efficiency with which our visual system processes natural object categories. Previous studies have shown that feed-forward hierarchical models of the visual cortex provide a good fit to human visual decisions. At the same time, recent work in computer vision has demonstrated significant gains in object recognition accuracy with increasingly deep hierarchical architectures. But it is unclear how well these models account for human visual decisions and what they may reveal about the underlying brain processes. We have conducted a large-scale psychophysics study to assess the correlation between computational models and human participants on a rapid animal vs. non-animal categorization task. We considered visual representations of varying complexity by analyzing the output of different stages of processing in three state-of-the-art deep networks. We found that recognition accuracy increases with higher stages of visual processing (higher level stages indeed outperforming human participants on the same task) but that human decisions agree best with predictions from intermediate stages. Overall, these results suggest that human participants may rely on visual features of intermediate complexity and that the complexity of visual representations afforded by modern deep network models may exceed those used by human participants during rapid categorization.