 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal-and-local attention networks for visual recognition
Paper and Code
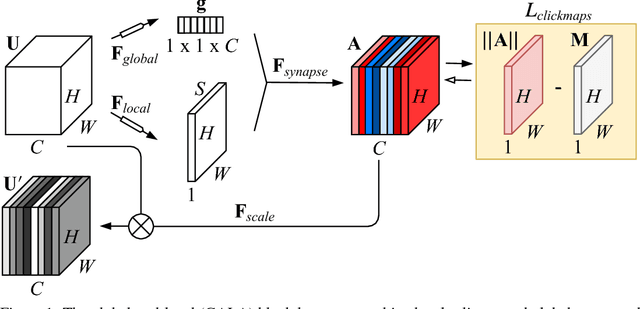
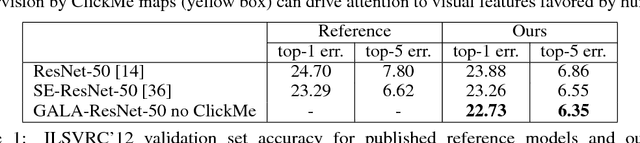
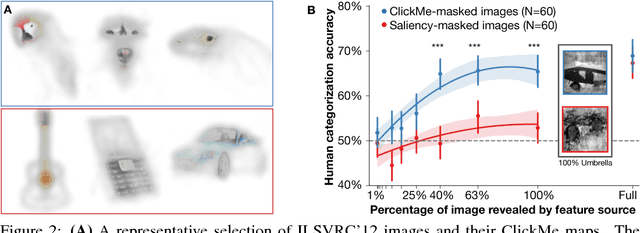

State-of-the-art deep convolutional networks (DCNs) such as squeeze-and- excitation (SE) residual networks implement a form of attention, also known as contextual guidance, which is derived from global image features. Here, we explore a complementary form of attention, known as visual saliency, which is derived from local image features. We extend the SE module with a novel global-and-local attention (GALA) module which combines both forms of attention -- resulting in state-of-the-art accuracy on ILSVRC. We further describe ClickMe.ai, a large-scale online experiment designed for human participants to identify diagnostic image regions to co-train a GALA network. Adding humans-in-the-loop is shown to significantly improve network accuracy, while also yielding visual features that are more interpretable and more similar to those used by human observers.