 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat are the visual features underlying human versus machine vision?
Paper and Code
Nov 07, 2017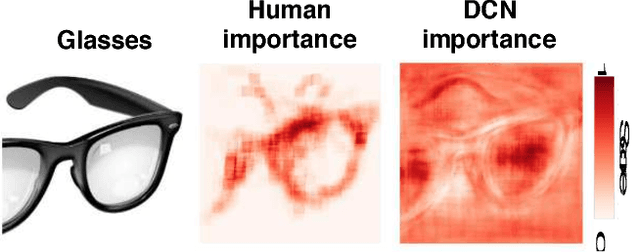

Although Deep Convolutional Networks (DCNs) are approaching the accuracy of human observers at object recognition, it is unknown whether they leverage similar visual representations to achieve this performance. To address this, we introduce Clicktionary, a web-based game for identifying visual features used by human observers during object recognition. Importance maps derived from the game are consistent across participants and uncorrelated with image saliency measures. These results suggest that Clicktionary identifies image regions that are meaningful and diagnostic for object recognition but different than those driving eye movements. Surprisingly, Clicktionary importance maps are only weakly correlated with relevance maps derived from DCNs trained for object recognition. Our study demonstrates that the narrowing gap between the object recognition accuracy of human observers and DCNs obscures distinct visual strategies used by each to achieve this performance.