 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustered Monotone Transforms for Rating Factorization
Oct 31, 2018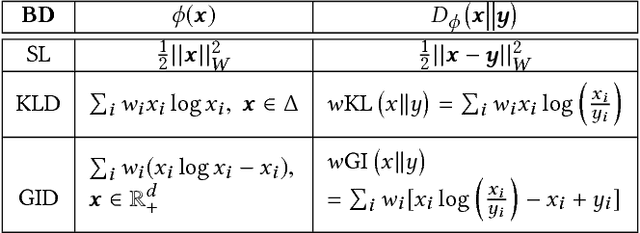
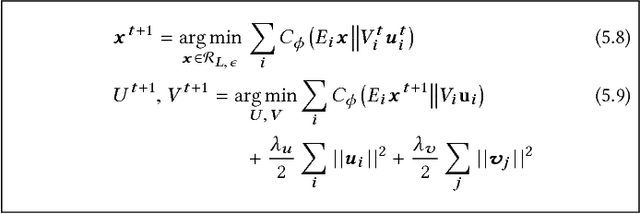
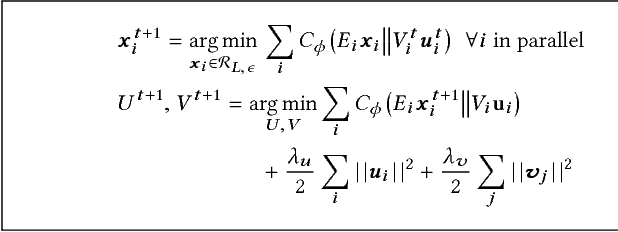
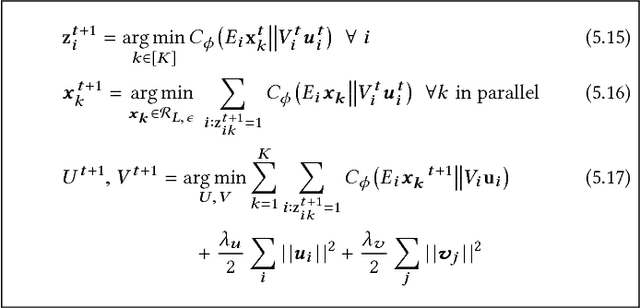
Exploiting low-rank structure of the user-item rating matrix has been the crux of many recommendation engines. However, existing recommendation engines force raters with heterogeneous behavior profiles to map their intrinsic rating scales to a common rating scale (e.g. 1-5). This non-linear transformation of the rating scale shatters the low-rank structure of the rating matrix, therefore resulting in a poor fit and consequentially, poor recommendations. In this paper, we propose Clustered Monotone Transforms for Rating Factorization (CMTRF), a novel approach to perform regression up to unknown monotonic transforms over unknown population segments. Essentially, for recommendation systems, the technique searches for monotonic transformations of the rating scales resulting in a better fit. This is combined with an underlying matrix factorization regression model that couples the user-wise ratings to exploit shared low dimensional structure. The rating scale transformations can be generated for each user, for a cluster of users, or for all the users at once, forming the basis of three simple and efficient algorithms proposed in this paper, all of which alternate between transformation of the rating scales and matrix factorization regression. Despite the non-convexity, CMTRF is theoretically shown to recover a unique solution under mild conditions. Experimental results on two synthetic and seven real-world datasets show that CMTRF outperforms other state-of-the-art baselines.
A case study of Empirical Bayes in User-Movie Recommendation system
Jul 07, 2017


In this article we provide a formulation of empirical bayes described by Atchade (2011) to tune the hyperparameters of priors used in bayesian set up of collaborative filter. We implement the same in MovieLens small dataset. We see that it can be used to get a good initial choice for the parameters. It can also be used to guess an initial choice for hyper-parameters in grid search procedure even for the datasets where MCMC oscillates around the true value or takes long time to converge.
Learning to Rank With Bregman Divergences and Monotone Retargeting
Oct 16, 2012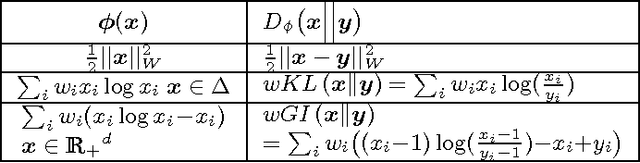
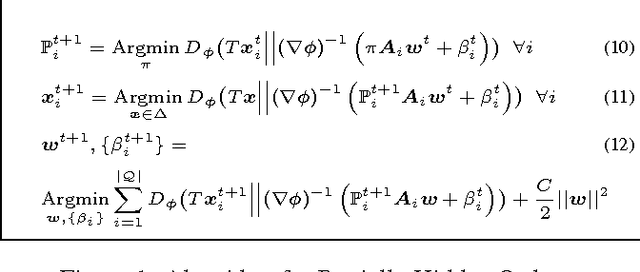


This paper introduces a novel approach for learning to rank (LETOR) based on the notion of monotone retargeting. It involves minimizing a divergence between all monotonic increasing transformations of the training scores and a parameterized prediction function. The minimization is both over the transformations as well as over the parameters. It is applied to Bregman divergences, a large class of "distance like" functions that were recently shown to be the unique class that is statistically consistent with the normalized discounted gain (NDCG) criterion [19]. The algorithm uses alternating projection style updates, in which one set of simultaneous projections can be computed independent of the Bregman divergence and the other reduces to parameter estimation of a generalized linear model. This results in easily implemented, efficiently parallelizable algorithm for the LETOR task that enjoys global optimum guarantees under mild conditions. We present empirical results on benchmark datasets showing that this approach can outperform the state of the art NDCG consistent techniques.
An Optimization Framework for Semi-Supervised and Transfer Learning using Multiple Classifiers and Clusterers
Apr 20, 2012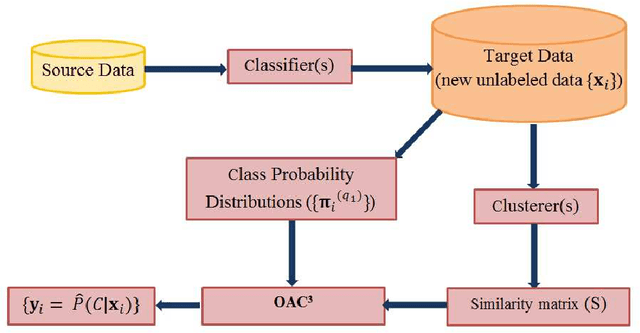

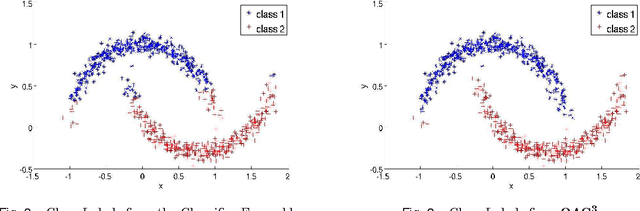
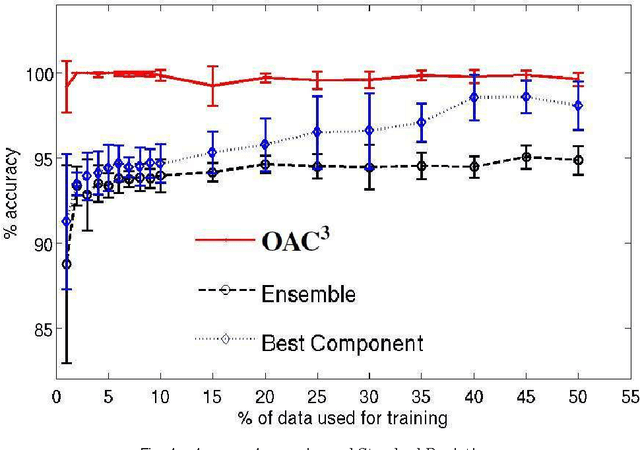
Unsupervised models can provide supplementary soft constraints to help classify new, "target" data since similar instances in the target set are more likely to share the same class label. Such models can also help detect possible differences between training and target distributions, which is useful in applications where concept drift may take place, as in transfer learning settings. This paper describes a general optimization framework that takes as input class membership estimates from existing classifiers learnt on previously encountered "source" data, as well as a similarity matrix from a cluster ensemble operating solely on the target data to be classified, and yields a consensus labeling of the target data. This framework admits a wide range of loss functions and classification/clustering methods. It exploits properties of Bregman divergences in conjunction with Legendre duality to yield a principled and scalable approach. A variety of experiments show that the proposed framework can yield results substantially superior to those provided by popular transductive learning techniques or by naively applying classifiers learnt on the original task to the target data.