 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Combination of Classifier and Cluster Ensembles for Non-transductive Learning
Nov 10, 2012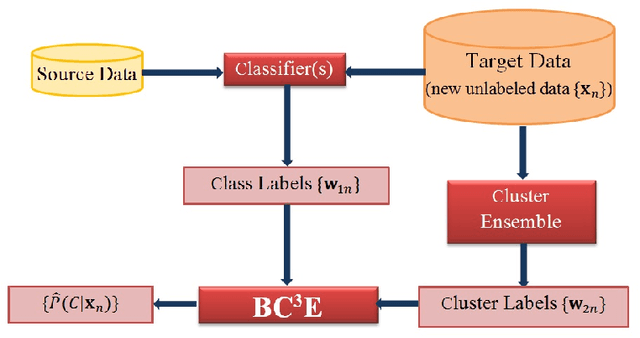

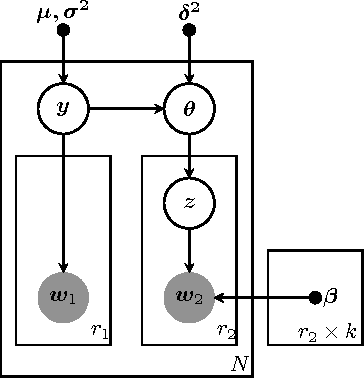
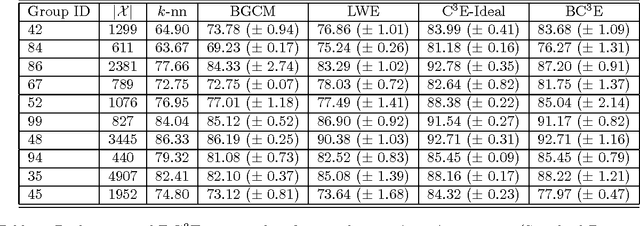
Unsupervised models can provide supplementary soft constraints to help classify new target data under the assumption that similar objects in the target set are more likely to share the same class label. Such models can also help detect possible differences between training and target distributions, which is useful in applications where concept drift may take place. This paper describes a Bayesian framework that takes as input class labels from existing classifiers (designed based on labeled data from the source domain), as well as cluster labels from a cluster ensemble operating solely on the target data to be classified, and yields a consensus labeling of the target data. This framework is particularly useful when the statistics of the target data drift or change from those of the training data. We also show that the proposed framework is privacy-aware and allows performing distributed learning when data/models have sharing restrictions. Experiments show that our framework can yield superior results to those provided by applying classifier ensembles only.
A Privacy-Aware Bayesian Approach for Combining Classifier and Cluster Ensembles
Apr 20, 2012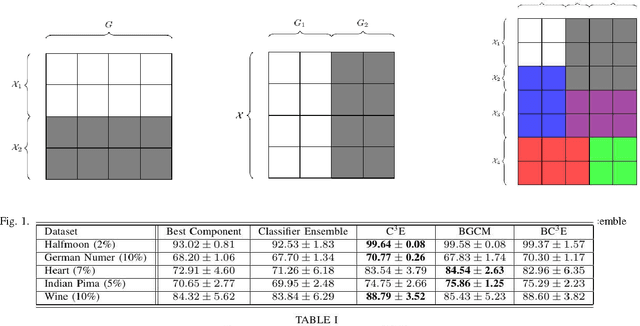
This paper introduces a privacy-aware Bayesian approach that combines ensembles of classifiers and clusterers to perform semi-supervised and transductive learning. We consider scenarios where instances and their classification/clustering results are distributed across different data sites and have sharing restrictions. As a special case, the privacy aware computation of the model when instances of the target data are distributed across different data sites, is also discussed. Experimental results show that the proposed approach can provide good classification accuracies while adhering to the data/model sharing constraints.
An Optimization Framework for Semi-Supervised and Transfer Learning using Multiple Classifiers and Clusterers
Apr 20, 2012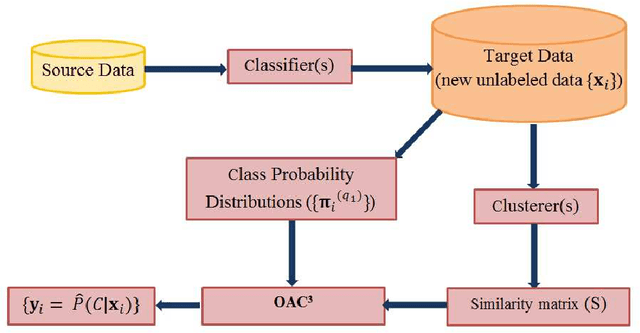

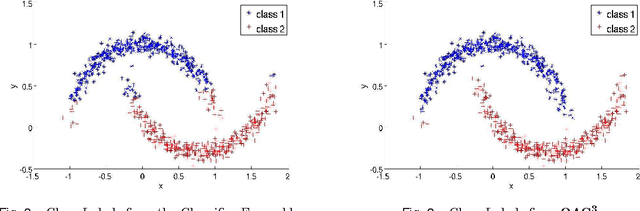
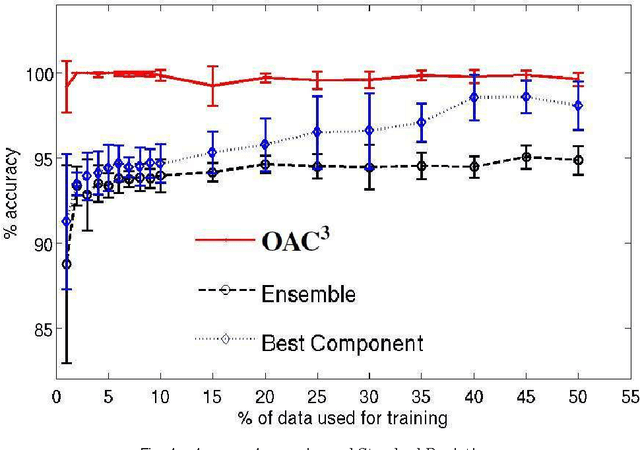
Unsupervised models can provide supplementary soft constraints to help classify new, "target" data since similar instances in the target set are more likely to share the same class label. Such models can also help detect possible differences between training and target distributions, which is useful in applications where concept drift may take place, as in transfer learning settings. This paper describes a general optimization framework that takes as input class membership estimates from existing classifiers learnt on previously encountered "source" data, as well as a similarity matrix from a cluster ensemble operating solely on the target data to be classified, and yields a consensus labeling of the target data. This framework admits a wide range of loss functions and classification/clustering methods. It exploits properties of Bregman divergences in conjunction with Legendre duality to yield a principled and scalable approach. A variety of experiments show that the proposed framework can yield results substantially superior to those provided by popular transductive learning techniques or by naively applying classifiers learnt on the original task to the target data.