 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommon and Rare Fundus Diseases Identification Using Vision-Language Foundation Model with Knowledge of Over 400 Diseases
Jun 13, 2024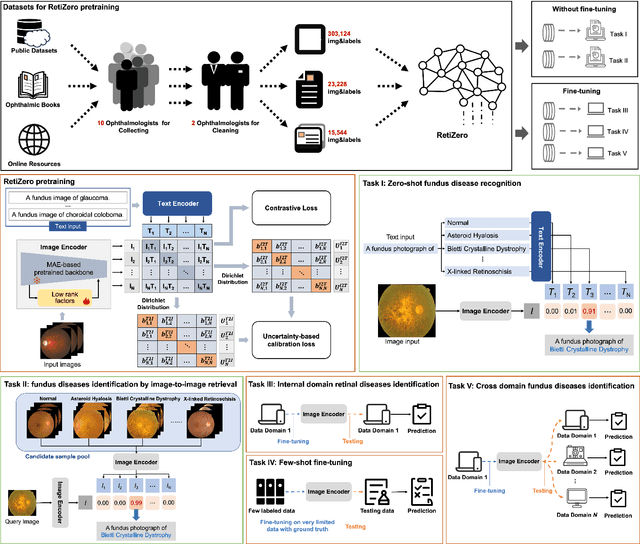
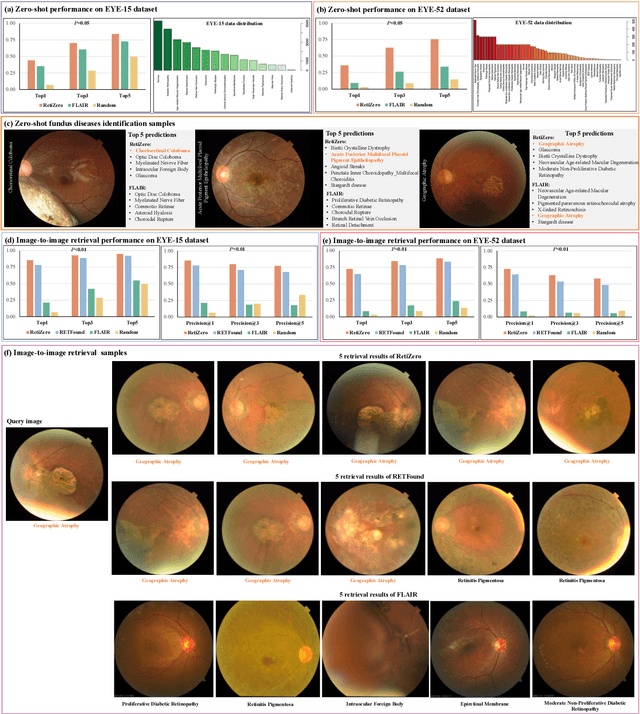
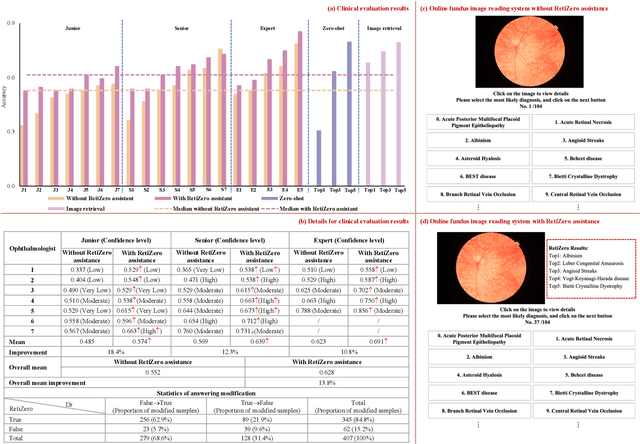
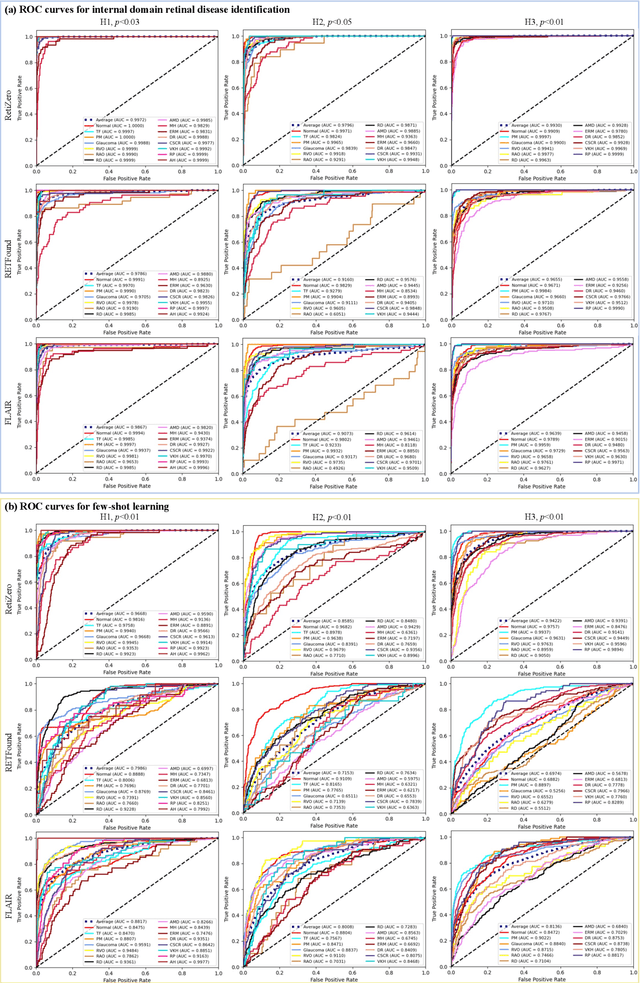
The current retinal artificial intelligence models were trained using data with a limited category of diseases and limited knowledge. In this paper, we present a retinal vision-language foundation model (RetiZero) with knowledge of over 400 fundus diseases. Specifically, we collected 341,896 fundus images paired with text descriptions from 29 publicly available datasets, 180 ophthalmic books, and online resources, encompassing over 400 fundus diseases across multiple countries and ethnicities. RetiZero achieved outstanding performance across various downstream tasks, including zero-shot retinal disease recognition, image-to-image retrieval, internal domain and cross-domain retinal disease classification, and few-shot fine-tuning. Specially, in the zero-shot scenario, RetiZero achieved a Top5 score of 0.8430 and 0.7561 on 15 and 52 fundus diseases respectively. In the image-retrieval task, RetiZero achieved a Top5 score of 0.9500 and 0.8860 on 15 and 52 retinal diseases respectively. Furthermore, clinical evaluations by ophthalmology experts from different countries demonstrate that RetiZero can achieve performance comparable to experienced ophthalmologists using zero-shot and image retrieval methods without requiring model retraining. These capabilities of retinal disease identification strengthen our RetiZero foundation model in clinical implementation.
Extraction of Text from Optic Nerve Optical Coherence Tomography Reports
Aug 21, 2023
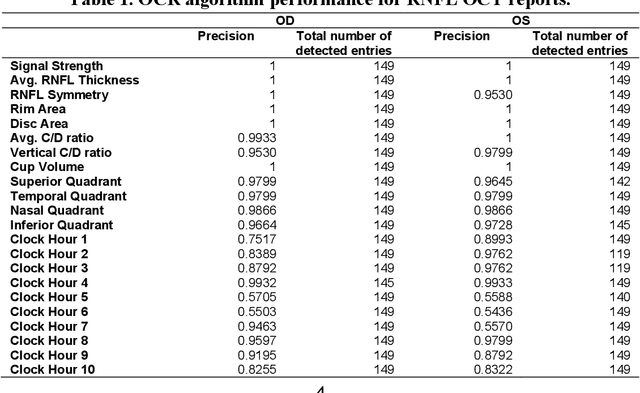
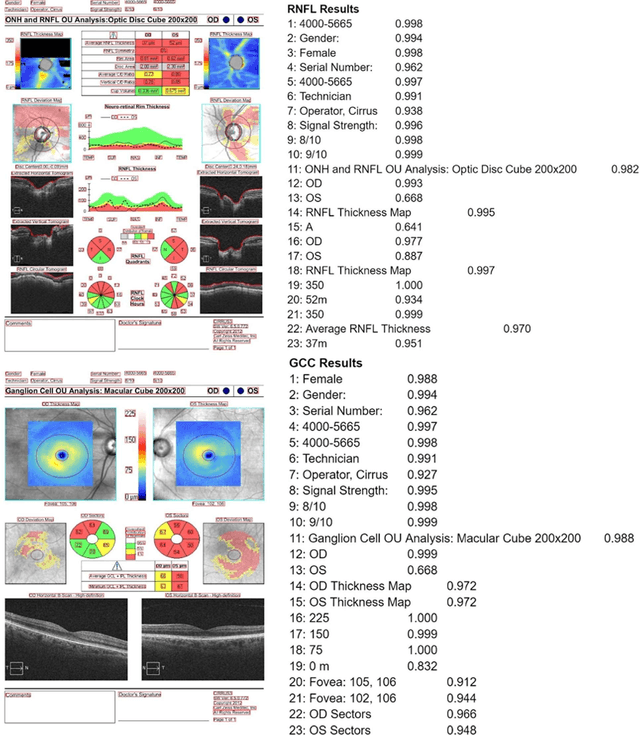

Purpose: The purpose of this study was to develop and evaluate rule-based algorithms to enhance the extraction of text data, including retinal nerve fiber layer (RNFL) values and other ganglion cell count (GCC) data, from Zeiss Cirrus optical coherence tomography (OCT) scan reports. Methods: DICOM files that contained encapsulated PDF reports with RNFL or Ganglion Cell in their document titles were identified from a clinical imaging repository at a single academic ophthalmic center. PDF reports were then converted into image files and processed using the PaddleOCR Python package for optical character recognition. Rule-based algorithms were designed and iteratively optimized for improved performance in extracting RNFL and GCC data. Evaluation of the algorithms was conducted through manual review of a set of RNFL and GCC reports. Results: The developed algorithms demonstrated high precision in extracting data from both RNFL and GCC scans. Precision was slightly better for the right eye in RNFL extraction (OD: 0.9803 vs. OS: 0.9046), and for the left eye in GCC extraction (OD: 0.9567 vs. OS: 0.9677). Some values presented more challenges in extraction, particularly clock hours 5 and 6 for RNFL thickness, and signal strength for GCC. Conclusions: A customized optical character recognition algorithm can identify numeric results from optical coherence scan reports with high precision. Automated processing of PDF reports can greatly reduce the time to extract OCT results on a large scale.