 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDACFL: Dynamic Average Consensus Based Federated Learning in Decentralized Topology
Nov 10, 2021


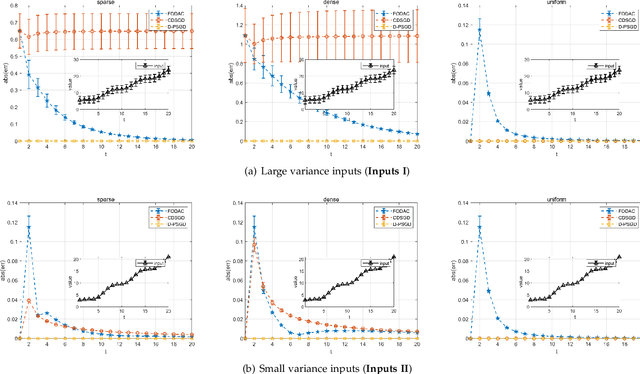
Federated learning (FL) is a burgeoning distributed machine learning framework where a central parameter server (PS) coordinates many local users to train a globally consistent model. Conventional federated learning inevitably relies on a centralized topology with a PS. As a result, it will paralyze once the PS fails. To alleviate such a single point failure, especially on the PS, some existing work has provided decentralized FL (DFL) implementations like CDSGD and D-PSGD to facilitate FL in a decentralized topology. However, there are still some problems with these methods, e.g., significant divergence between users' final models in CDSGD and a network-wide model average necessity in D-PSGD. In order to solve these deficiency, this paper devises a new DFL implementation coined as DACFL, where each user trains its model using its own training data and exchanges the intermediate models with its neighbors through a symmetric and doubly stochastic matrix. The DACFL treats the progress of each user's local training as a discrete-time process and employs a first order dynamic average consensus (FODAC) method to track the \textit{average model} in the absence of the PS. In this paper, we also provide a theoretical convergence analysis of DACFL on the premise of i.i.d data to strengthen its rationality. The experimental results on MNIST, Fashion-MNIST and CIFAR-10 validate the feasibility of our solution in both time-invariant and time-varying network topologies, and declare that DACFL outperforms D-PSGD and CDSGD in most cases.
Resonant Beam Communications with Echo Interference Elimination
Jun 25, 2021



Resonant beam communications (RBCom) is capable of providing wide bandwidth when using light as the carrier. Besides, the RBCom system possesses the characteristics of mobility, high signal-to-noise ratio (SNR), and multiplexing. Nevertheless, the channel of the RBCom system is distinct from other light communication technologies due to the echo interference issue. In this paper, we reveal the mechanism of the echo interference and propose the method to eliminate the interference. Moreover, we present an exemplary design based on frequency shifting and optical filtering, along with its mathematic model and performance analysis. The numerical evaluation shows that the channel capacity is greater than 15 bit/s/Hz.
Knowledge-Driven Machine Learning: Concept, Model and Case Study on Channel Estimation
Dec 21, 2020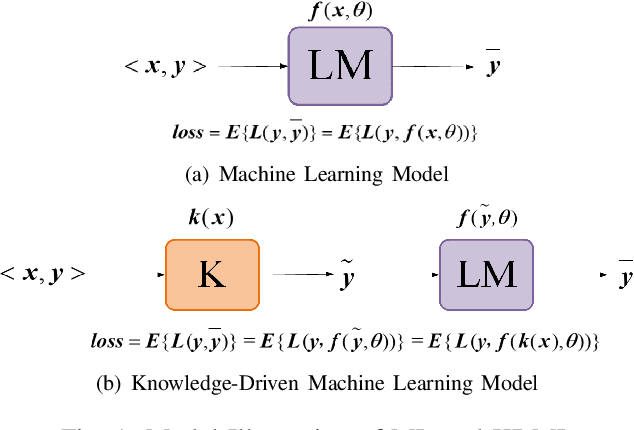

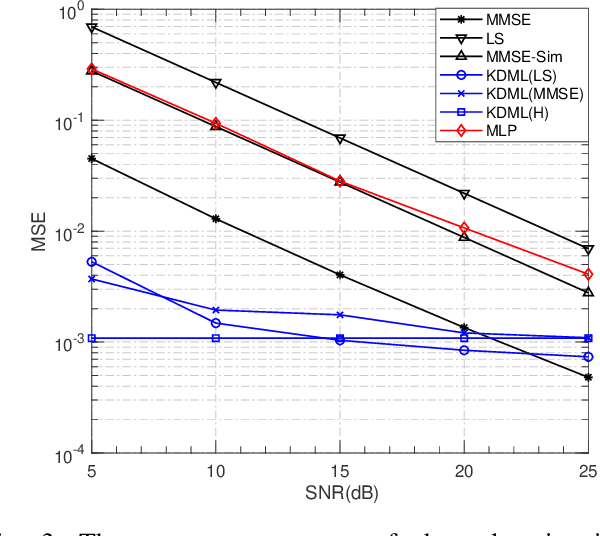
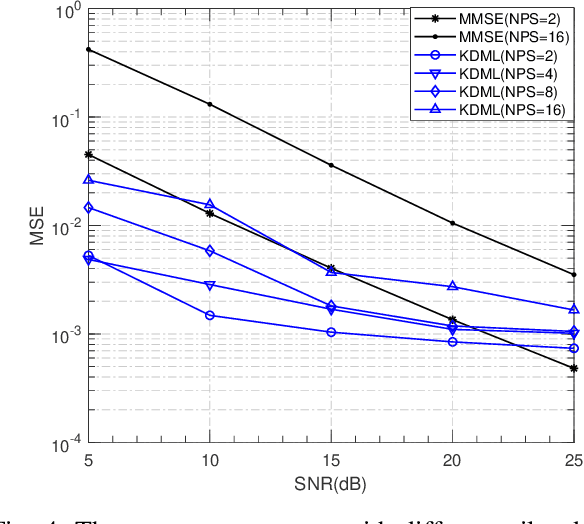
The power of big data and machine learning has been drastically demonstrated in many fields during the past twenty years which somehow leads to the vague even false understanding that the huge amount of precious human knowledge accumulated to date no longer seems to matter. In this paper, we are pioneering to propose the knowledge-driven machine learning(KDML) model to exhibit that knowledge can play an important role in machine learning tasks. KDML takes advantage of domain knowledge to processes the input data by space transforming without any training which enable the space of input and the output data of the neural networks to be identical, so that we can simplify the machine learning network structure and reduce training costs significantly. Channel estimation problems considering the time selective and frequency selective fading in wireless communications are taken as a case study, where we choose least square(LS) and minimum meansquare error(MMSE) as knowledge module and Long Short Term Memory(LSTM) as learning module. The performance obtained by KDML channel estimator obviously outperforms that of knowledge processing or conventional machine learning, respectively. Our work sheds light on the new area of machine learning and knowledge processing.
Semi-Federated Learning
Mar 28, 2020
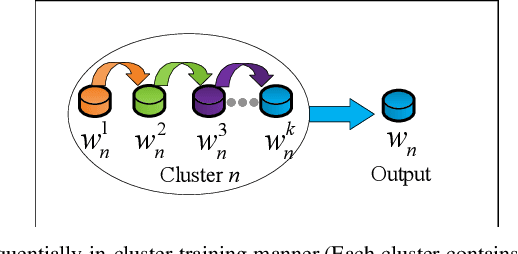
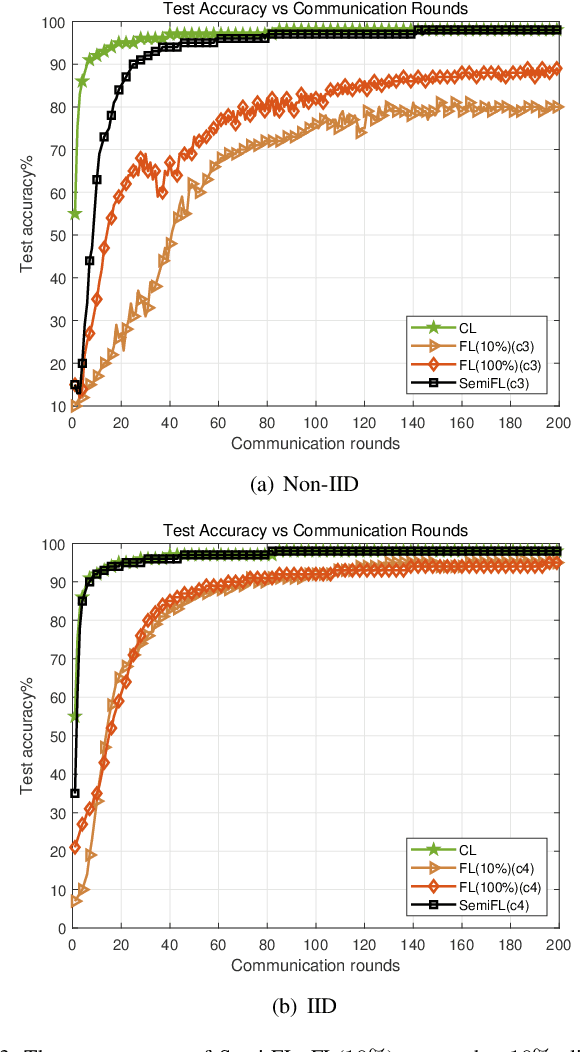

Federated learning (FL) enables massive distributed Information and Communication Technology (ICT) devices to learn a global consensus model without any participants revealing their own data to the central server. However, the practicality, communication expense and non-independent and identical distribution (Non-IID) data challenges in FL still need to be concerned. In this work, we propose the Semi-Federated Learning (Semi-FL) which differs from the FL in two aspects, local clients clustering and in-cluster training. A sequential training manner is designed for our in-cluster training in this paper which enables the neighboring clients to share their learning models. The proposed Semi-FL can be easily applied to future mobile communication networks and require less up-link transmission bandwidth. Numerical experiments validate the feasibility, learning performance and the robustness to Non-IID data of the proposed Semi-FL. The Semi-FL extends the existing potentials of FL.