 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDACFL: Dynamic Average Consensus Based Federated Learning in Decentralized Topology
Nov 10, 2021


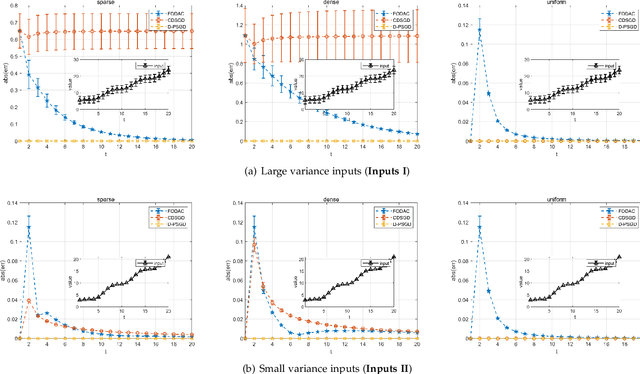
Federated learning (FL) is a burgeoning distributed machine learning framework where a central parameter server (PS) coordinates many local users to train a globally consistent model. Conventional federated learning inevitably relies on a centralized topology with a PS. As a result, it will paralyze once the PS fails. To alleviate such a single point failure, especially on the PS, some existing work has provided decentralized FL (DFL) implementations like CDSGD and D-PSGD to facilitate FL in a decentralized topology. However, there are still some problems with these methods, e.g., significant divergence between users' final models in CDSGD and a network-wide model average necessity in D-PSGD. In order to solve these deficiency, this paper devises a new DFL implementation coined as DACFL, where each user trains its model using its own training data and exchanges the intermediate models with its neighbors through a symmetric and doubly stochastic matrix. The DACFL treats the progress of each user's local training as a discrete-time process and employs a first order dynamic average consensus (FODAC) method to track the \textit{average model} in the absence of the PS. In this paper, we also provide a theoretical convergence analysis of DACFL on the premise of i.i.d data to strengthen its rationality. The experimental results on MNIST, Fashion-MNIST and CIFAR-10 validate the feasibility of our solution in both time-invariant and time-varying network topologies, and declare that DACFL outperforms D-PSGD and CDSGD in most cases.
Semi-Federated Learning
Mar 28, 2020
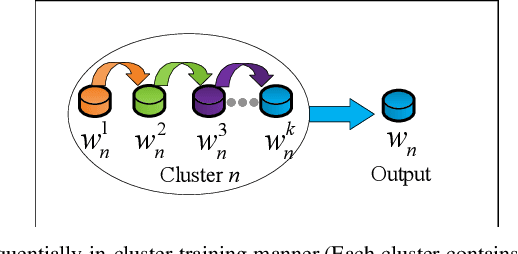
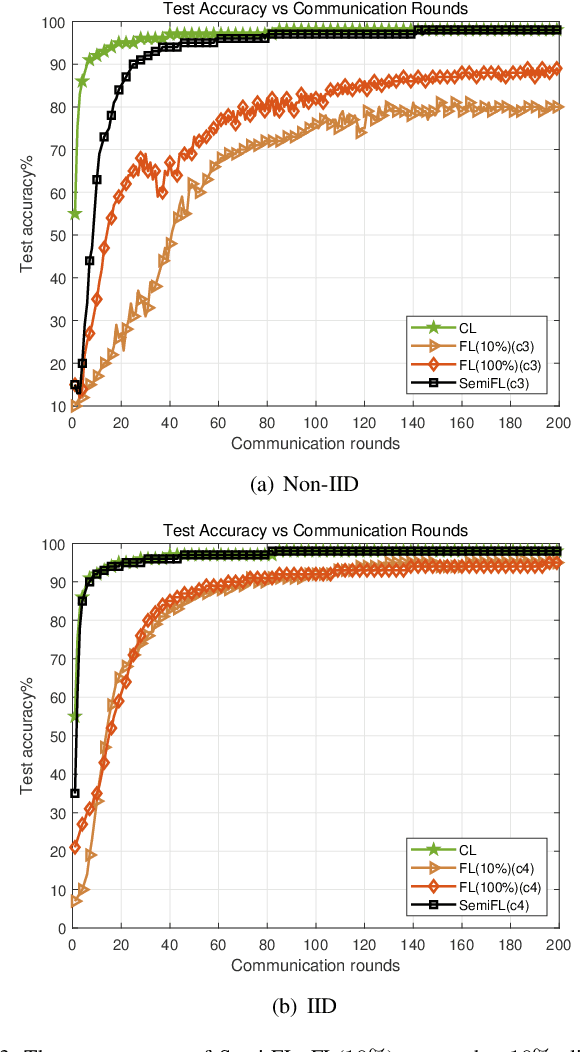

Federated learning (FL) enables massive distributed Information and Communication Technology (ICT) devices to learn a global consensus model without any participants revealing their own data to the central server. However, the practicality, communication expense and non-independent and identical distribution (Non-IID) data challenges in FL still need to be concerned. In this work, we propose the Semi-Federated Learning (Semi-FL) which differs from the FL in two aspects, local clients clustering and in-cluster training. A sequential training manner is designed for our in-cluster training in this paper which enables the neighboring clients to share their learning models. The proposed Semi-FL can be easily applied to future mobile communication networks and require less up-link transmission bandwidth. Numerical experiments validate the feasibility, learning performance and the robustness to Non-IID data of the proposed Semi-FL. The Semi-FL extends the existing potentials of FL.