 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBudget-Aware Anytime Reasoning with LLM-Synthesized Preference Data
Jan 16, 2026We study the reasoning behavior of large language models (LLMs) under limited computation budgets. In such settings, producing useful partial solutions quickly is often more practical than exhaustive reasoning, which incurs high inference costs. Many real-world tasks, such as trip planning, require models to deliver the best possible output within a fixed reasoning budget. We introduce an anytime reasoning framework and the Anytime Index, a metric that quantifies how effectively solution quality improves as reasoning tokens increase. To further enhance efficiency, we propose an inference-time self-improvement method using LLM-synthesized preference data, where models learn from their own reasoning comparisons to produce better intermediate solutions. Experiments on NaturalPlan (Trip), AIME, and GPQA datasets show consistent gains across Grok-3, GPT-oss, GPT-4.1/4o, and LLaMA models, improving both reasoning quality and efficiency under budget constraints.
Large-Scale Video Classification with Feature Space Augmentation coupled with Learned Label Relations and Ensembling
Sep 21, 2018
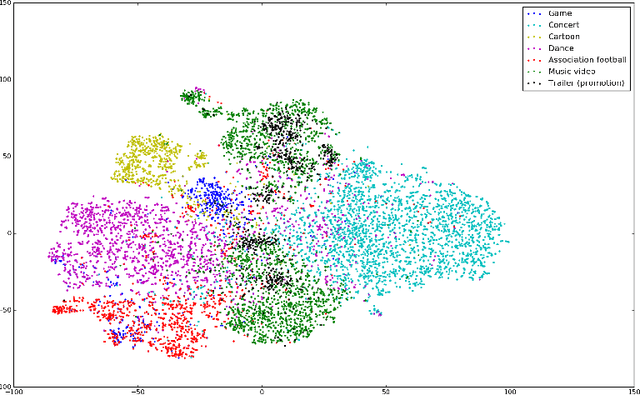
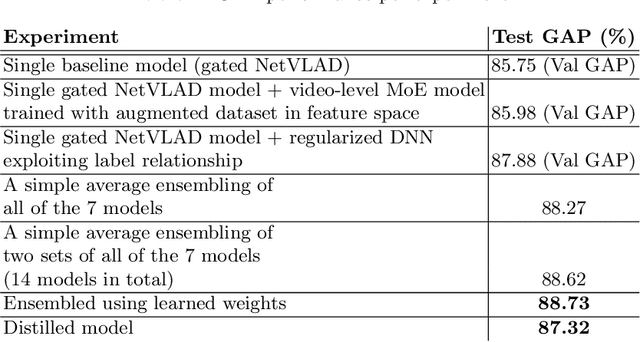
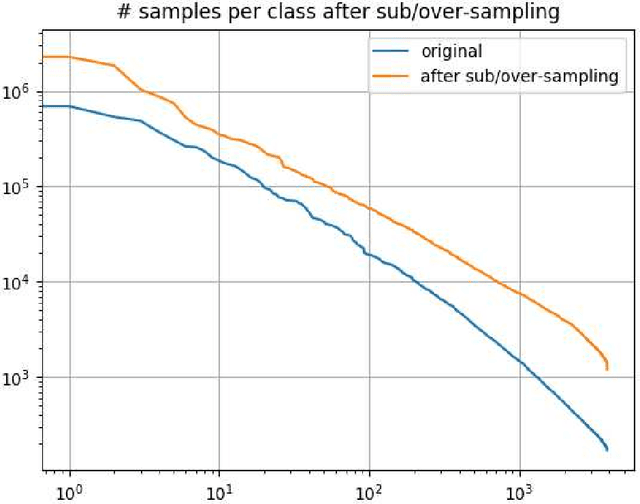
This paper presents the Axon AI's solution to the 2nd YouTube-8M Video Understanding Challenge, achieving the final global average precision (GAP) of 88.733% on the private test set (ranked 3rd among 394 teams, not considering the model size constraint), and 87.287% using a model that meets size requirement. Two sets of 7 individual models belonging to 3 different families were trained separately. Then, the inference results on a training data were aggregated from these multiple models and fed to train a compact model that meets the model size requirement. In order to further improve performance we explored and employed data over/sub-sampling in feature space, an additional regularization term during training exploiting label relationship, and learned weights for ensembling different individual models.