 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Video Classification with Feature Space Augmentation coupled with Learned Label Relations and Ensembling
Paper and Code
Sep 21, 2018
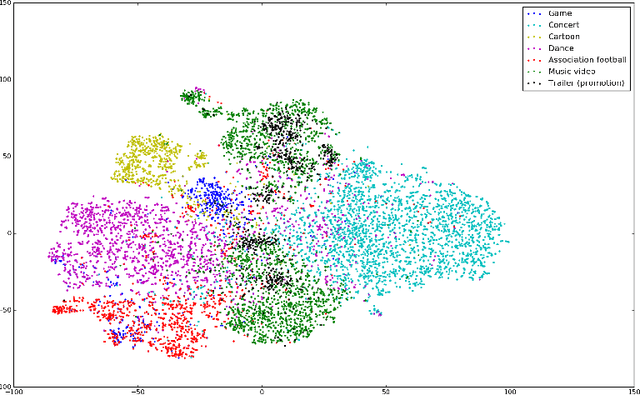
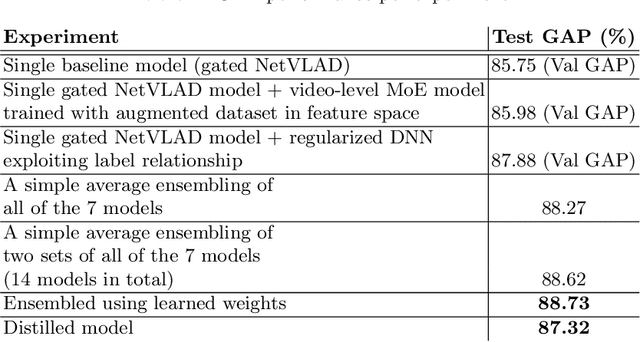
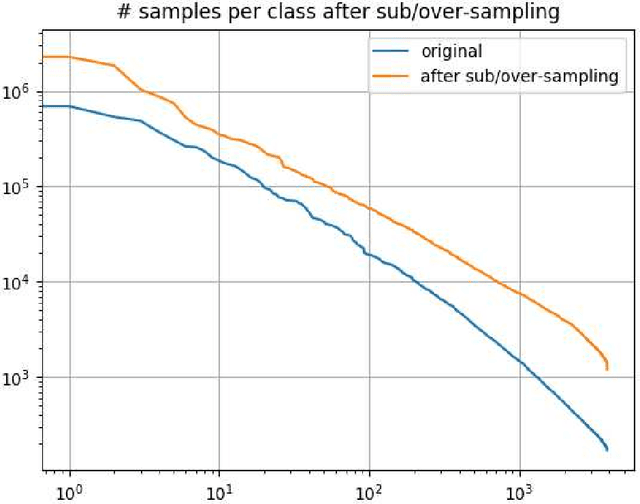
This paper presents the Axon AI's solution to the 2nd YouTube-8M Video Understanding Challenge, achieving the final global average precision (GAP) of 88.733% on the private test set (ranked 3rd among 394 teams, not considering the model size constraint), and 87.287% using a model that meets size requirement. Two sets of 7 individual models belonging to 3 different families were trained separately. Then, the inference results on a training data were aggregated from these multiple models and fed to train a compact model that meets the model size requirement. In order to further improve performance we explored and employed data over/sub-sampling in feature space, an additional regularization term during training exploiting label relationship, and learned weights for ensembling different individual models.