 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedHorizon: Towards Long-context Medical Video Understanding in the Wild
May 07, 2026Medical multimodal large language models (MLLMs) have advanced image understanding and short-video analysis, but real clinical review often requires full-procedure video understanding. Unlike general long videos, medical procedures contain highly redundant anatomical views, while decisive evidence is temporally sparse, spatially subtle, and context dependent. Existing benchmarks often assume this evidence has already been localized through images, short clips, or pre-segmented videos, leaving the retrieval-before-reasoning problem under-tested. We introduce MedHorizon, an in-the-wild benchmark for long-context medical video understanding. MedHorizon preserves 759 hours of full-length clinical procedures and provides 1,253 evidence-grounded multiple-choice questionsthat jointly evaluate sparse evidence understanding and multi-hop clinical reasoning. Its evidence is extremely sparse, with only 0.166% evidence frames on average, requiring models to search noisy procedural streams before interpreting and aggregating findings. We evaluate representative general-domain, medical-domain, and long-video MLLMs. The best model reaches only 41.1% accuracy, showing that current systems remain far from robust full-procedure understanding. Further analysis yields four key findings: performance does not scale reliably with more frames, evidence retrieval and clinical interpretation remain primary bottlenecks; these bottlenecks are rooted in weak procedural reasoning and attention drift under redundancy, and generic sampling methods only partially balances local detail with global coverage. MedHorizon provides a rigorous testbed for MLLMs that retrieve sparse evidence and reason over complete clinical workflows.
AdamO: A Collapse-Suppressed Optimizer for Offline RL
May 03, 2026Offline reinforcement learning (RL) can fail spectacularly when bootstrapped temporal-difference (TD) updates amplify their own errors, driving the critic toward extreme and unusable Q-values. A key counterintuitive insight of this work is that collapse is not only a property of the backup rule or network architecture: optimizer dynamics themselves can directly trigger or suppress instability. From a control-theoretic viewpoint, we model offline TD learning as a feedback system and analyze Adam-based critic updates. This yields a necessary and sufficient condition for stability of the induced local update dynamics: within the regime we analyze, these dynamics are stable if and only if the spectral radius of the corresponding update operator is strictly below one. Further analysis suggests that standard Adam updates can inadvertently distort the parameter geometry, motivating explicit orthogonality constraints to prevent TD error amplification. To this end, we propose AdamO, an Adam-based optimizer with a decoupled orthogonality correction regulated by a strict task-alignment budget. We prove that this design theoretically guarantees worst-case task safety and preserves Adam's continuous-time dissipative dynamics. Empirically, AdamO is broadly compatible with diverse offline RL baselines, improving stability and returns across a broad suite of benchmarks.
See Further, Think Deeper: Advancing VLM's Reasoning Ability with Low-level Visual Cues and Reflection
Apr 27, 2026Recent advances in Vision-Language Models (VLMs) have benefited from Reinforcement Learning (RL) for enhanced reasoning. However, existing methods still face critical limitations, including the lack of low-level visual information and effective visual feedback. To address these problems, this paper proposes a unified multimodal interleaved reasoning framework \textbf{ForeSight}, which enables VLMs to \textbf{See Further} with low-level visual cues and \textbf{Think Deeper} with effective visual feedback. First, it introduces a set of low-level visual tools to integrate essential visual information into the reasoning chain, mitigating the neglect of fine-grained visual features. Second, a mask-based visual feedback mechanism is elaborated to incorporate visual reflection into the thinking process, enabling the model to dynamically re-examine and update its answers. Driven by RL, ForeSight learns to autonomously decide on tool invocation and answer verification, with the final answer accuracy as the reward signal. To evaluate the performance of the proposed framework, we construct a new dataset, Character and Grounding SalBench (CG-SalBench), based on the SalBench dataset. Experimental results demonstrate that the ForeSight-7B model significantly outperforms other models with the same parameter scale, and even surpasses the current SOTA closed-source models on certain metrics.
Cloud-Edge Collaborative Large Models for Robust Photovoltaic Power Forecasting
Mar 25, 2026Photovoltaic (PV) power forecasting in edge-enabled grids requires balancing forecasting accuracy, robustness under weather-driven distribution shifts, and strict latency constraints. Existing models work well under normal conditions but often struggle with rare ramp events and unexpected weather changes. Relying solely on cloud-based large models often leads to significant communication delays, which can hinder timely and efficient forecasting in practical grid environments. To address these issues, we propose a condition-adaptive cloud-edge collaborative framework *CAPE* for PV forecasting. *CAPE* consists of three main modules: a site-specific expert model for routine predictions, a lightweight edge-side model for enhanced local inference, and a cloud-based large retrieval model that provides relevant historical cases when needed. These modules are coordinated by a screening module that evaluates uncertainty, out-of-distribution risk, weather mutations, and model disagreement. Furthermore, we employ a Lyapunov-guided routing strategy to dynamically determine when to escalate inference to more powerful models under long-term system constraints. The final forecast is produced through adaptive fusion of the selected model outputs. Experiments on two real-world PV datasets demonstrate that *CAPE* achieves superior performance in terms of forecasting accuracy, robustness, routing quality, and system efficiency.
ELLA: Generative AI-Powered Social Robots for Early Language Development at Home
Mar 12, 2026Early language development shapes children's later literacy and learning, yet many families have limited access to scalable, high-quality support at home. Recent advances in generative AI make it possible for social robots to move beyond scripted interactions and engage children in adaptive, conversational activities, but it remains unclear how to design such systems for pre-schoolers and how children engage with them over time in the home. We present ELLA (Early Language Learning Agent), an autonomous, generative AI-powered social robot that supports early language development through interactive storytelling, parent-selected language targets, and scaffolded dialogue. Using a multi-phased, human-centered process, we interviewed parents (n=7) and educators (n=5) and iteratively refined ELLA through twelve in-home design workshops. We then deployed ELLA with ten children for eight days. We report design insights from in-home workshops, characterize children's engagement and behaviors during deployment, and distill design implications for generative AI-powered social robots supporting early language learning at home.
Less is More: Clustered Cross-Covariance Control for Offline RL
Jan 28, 2026A fundamental challenge in offline reinforcement learning is distributional shift. Scarce data or datasets dominated by out-of-distribution (OOD) areas exacerbate this issue. Our theoretical analysis and experiments show that the standard squared error objective induces a harmful TD cross covariance. This effect amplifies in OOD areas, biasing optimization and degrading policy learning. To counteract this mechanism, we develop two complementary strategies: partitioned buffer sampling that restricts updates to localized replay partitions, attenuates irregular covariance effects, and aligns update directions, yielding a scheme that is easy to integrate with existing implementations, namely Clustered Cross-Covariance Control for TD (C^4). We also introduce an explicit gradient-based corrective penalty that cancels the covariance induced bias within each update. We prove that buffer partitioning preserves the lower bound property of the maximization objective, and that these constraints mitigate excessive conservatism in extreme OOD areas without altering the core behavior of policy constrained offline reinforcement learning. Empirically, our method showcases higher stability and up to 30% improvement in returns over prior methods, especially with small datasets and splits that emphasize OOD areas.
Subgraph Aggregation for Out-of-Distribution Generalization on Graphs
Oct 29, 2024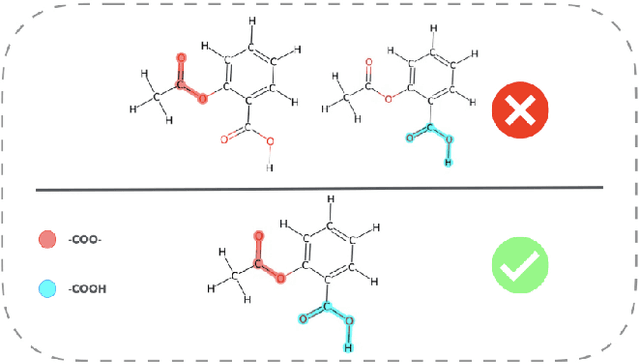
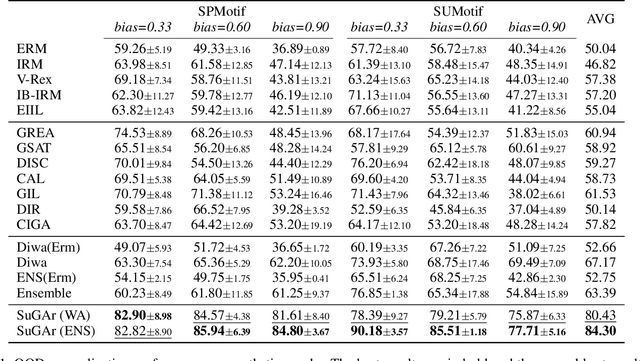
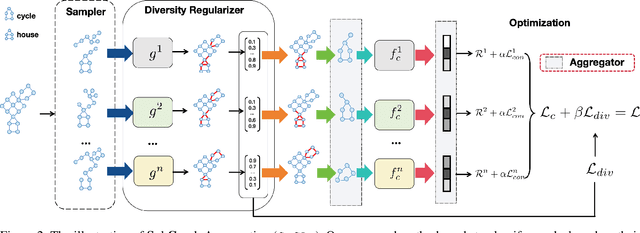
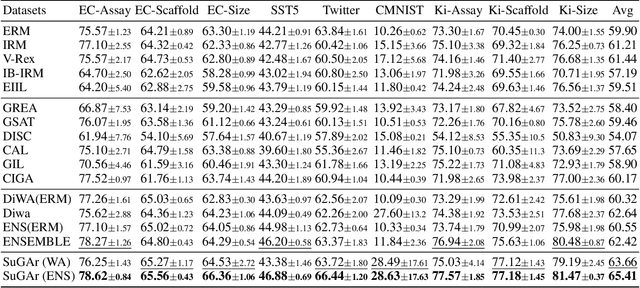
Out-of-distribution (OOD) generalization in Graph Neural Networks (GNNs) has gained significant attention due to its critical importance in graph-based predictions in real-world scenarios. Existing methods primarily focus on extracting a single causal subgraph from the input graph to achieve generalizable predictions. However, relying on a single subgraph can lead to susceptibility to spurious correlations and is insufficient for learning invariant patterns behind graph data. Moreover, in many real-world applications, such as molecular property prediction, multiple critical subgraphs may influence the target label property. To address these challenges, we propose a novel framework, SubGraph Aggregation (SuGAr), designed to learn a diverse set of subgraphs that are crucial for OOD generalization on graphs. Specifically, SuGAr employs a tailored subgraph sampler and diversity regularizer to extract a diverse set of invariant subgraphs. These invariant subgraphs are then aggregated by averaging their representations, which enriches the subgraph signals and enhances coverage of the underlying causal structures, thereby improving OOD generalization. Extensive experiments on both synthetic and real-world datasets demonstrate that \ours outperforms state-of-the-art methods, achieving up to a 24% improvement in OOD generalization on graphs. To the best of our knowledge, this is the first work to study graph OOD generalization by learning multiple invariant subgraphs.
Piecewise Linear Neural Networks and Deep Learning
Jun 18, 2022As a powerful modelling method, PieceWise Linear Neural Networks (PWLNNs) have proven successful in various fields, most recently in deep learning. To apply PWLNN methods, both the representation and the learning have long been studied. In 1977, the canonical representation pioneered the works of shallow PWLNNs learned by incremental designs, but the applications to large-scale data were prohibited. In 2010, the Rectified Linear Unit (ReLU) advocated the prevalence of PWLNNs in deep learning. Ever since, PWLNNs have been successfully applied to extensive tasks and achieved advantageous performances. In this Primer, we systematically introduce the methodology of PWLNNs by grouping the works into shallow and deep networks. Firstly, different PWLNN representation models are constructed with elaborated examples. With PWLNNs, the evolution of learning algorithms for data is presented and fundamental theoretical analysis follows up for in-depth understandings. Then, representative applications are introduced together with discussions and outlooks.
Efficient hinging hyperplanes neural network and its application in nonlinear system identification
May 15, 2019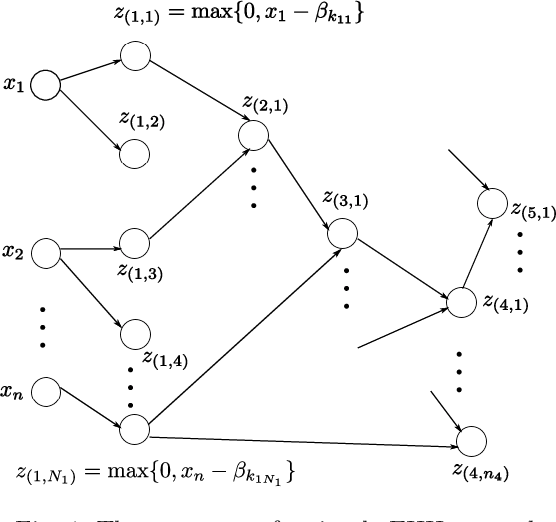
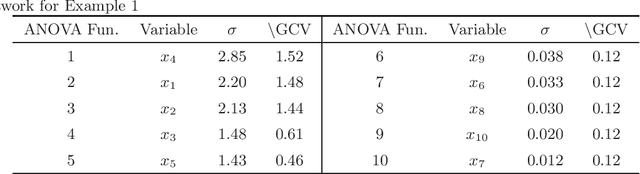
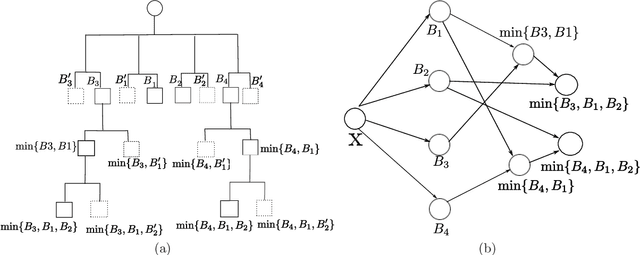
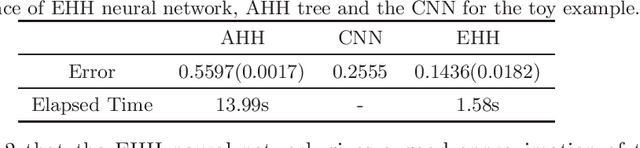
In this paper, the efficient hinging hyperplanes (EHH) neural network is proposed based on the model of hinging hyperplanes (HH). The EHH neural network is a distributed representation, the training of which involves solving several convex optimization problems and is fast. It is proved that for every EHH neural network, there is an equivalent adaptive hinging hyperplanes (AHH) tree, which was also proposed based on the model of HH and find good applications in system identification. The construction of the EHH neural network includes 2 stages. First the initial structure of the EHH neural network is randomly determined and the Lasso regression is used to choose the appropriate network. To alleviate the impact of randomness, secondly, the stacking strategy is employed to formulate a more general network structure. Different from other neural networks, the EHH neural network has interpretability ability, which can be easily obtained through its ANOVA decomposition (or interaction matrix). The interpretability can then be used as a suggestion for input variable selection. The EHH neural network is applied in nonlinear system identification, the simulation results show that the regression vector selected is reasonable and the identification speed is fast, while at the same time, the simulation accuracy is satisfactory.