 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplication of the Keyword Extraction part of the paper "'Without the Clutter of Unimportant Words': Descriptive Keyphrases for Text Visualization"
Aug 15, 2019
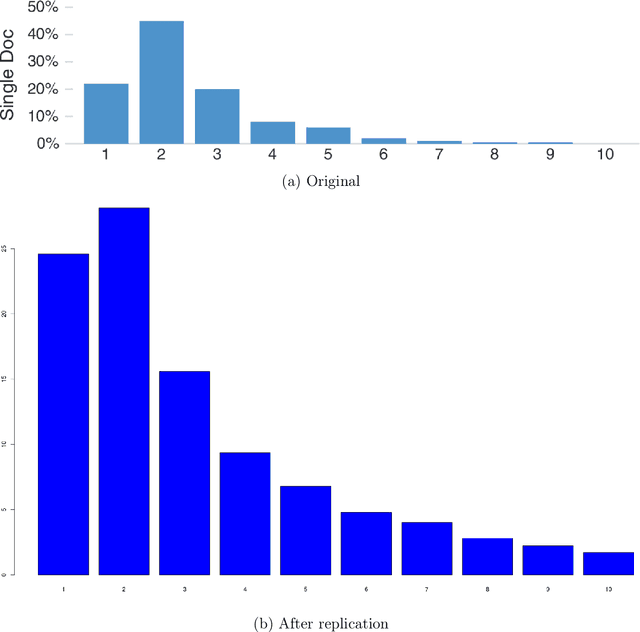

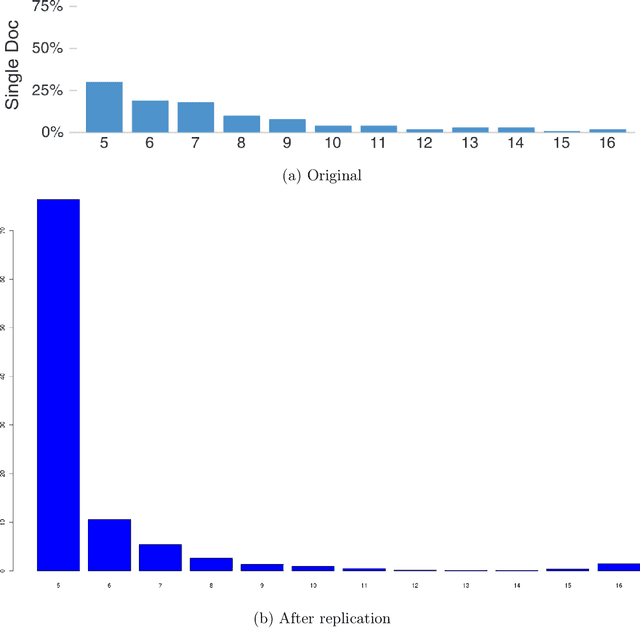
"Keyword Extraction" refers to the task of automatically identifying the most relevant and informative phrases in natural language text. As we are deluged with large amounts of text data in many different forms and content - emails, blogs, tweets, Facebook posts, academic papers, news articles - the task of "making sense" of all this text by somehow summarizing them into a coherent structure assumes paramount importance. Keyword extraction - a well-established problem in Natural Language Processing - can help us here. In this report, we construct and test three different hypotheses (all related to the task of keyword extraction) that take us one step closer to understanding how to meaningfully identify and extract "descriptive" keyphrases. The work reported here was done as part of replicating the study by Chuang et al. [3].
A New Bengali Readability Score
Mar 14, 2017In this paper we have proposed methods to analyze the readability of Bengali language texts. We have got some exceptionally good results out of the experiments.
SQUINKY! A Corpus of Sentence-level Formality, Informativeness, and Implicature
Sep 27, 2016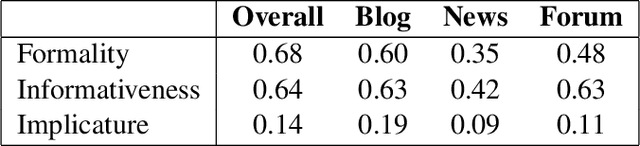
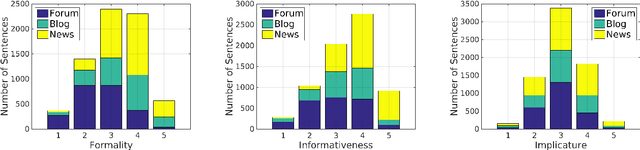

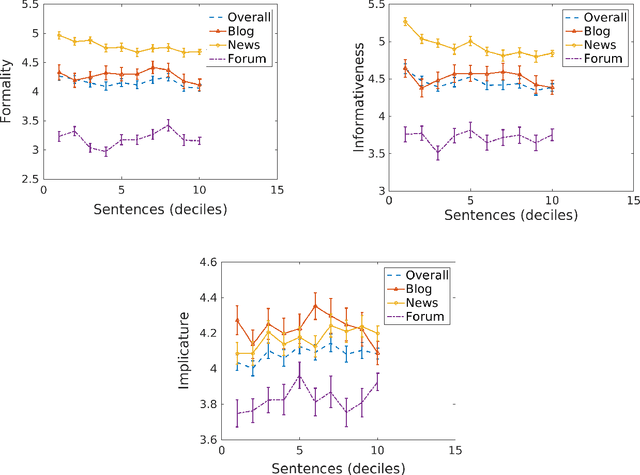
We introduce a corpus of 7,032 sentences rated by human annotators for formality, informativeness, and implicature on a 1-7 scale. The corpus was annotated using Amazon Mechanical Turk. Reliability in the obtained judgments was examined by comparing mean ratings across two MTurk experiments, and correlation with pilot annotations (on sentence formality) conducted in a more controlled setting. Despite the subjectivity and inherent difficulty of the annotation task, correlations between mean ratings were quite encouraging, especially on formality and informativeness. We further explored correlation between the three linguistic variables, genre-wise variation of ratings and correlations within genres, compatibility with automatic stylistic scoring, and sentential make-up of a document in terms of style. To date, our corpus is the largest sentence-level annotated corpus released for formality, informativeness, and implicature.
A Supervised Authorship Attribution Framework for Bengali Language
Sep 07, 2016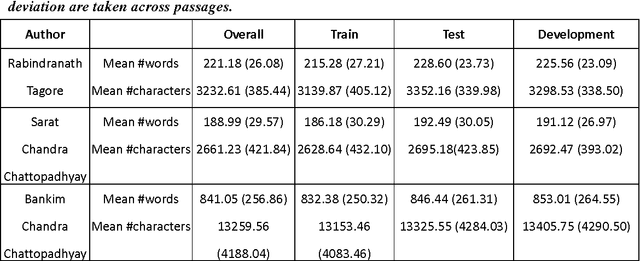
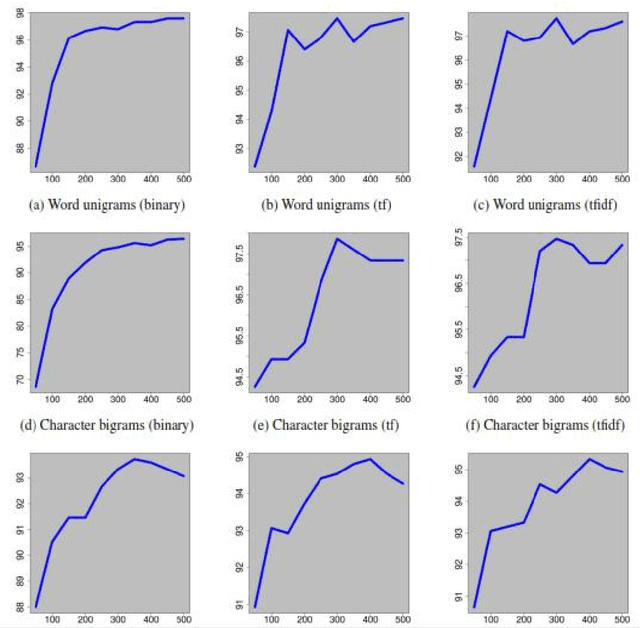
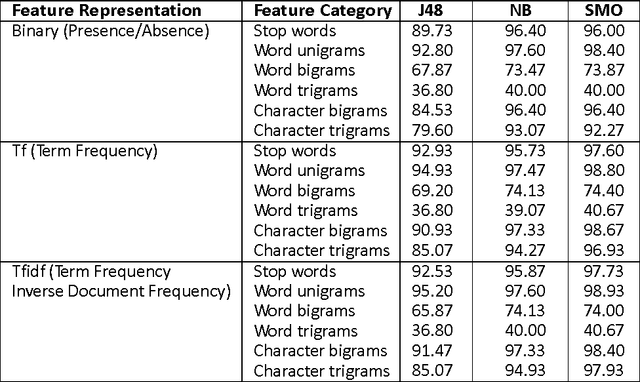
Authorship Attribution is a long-standing problem in Natural Language Processing. Several statistical and computational methods have been used to find a solution to this problem. In this paper, we have proposed methods to deal with the authorship attribution problem in Bengali.
PerSum: Novel Systems for Document Summarization in Persian
Jun 09, 2016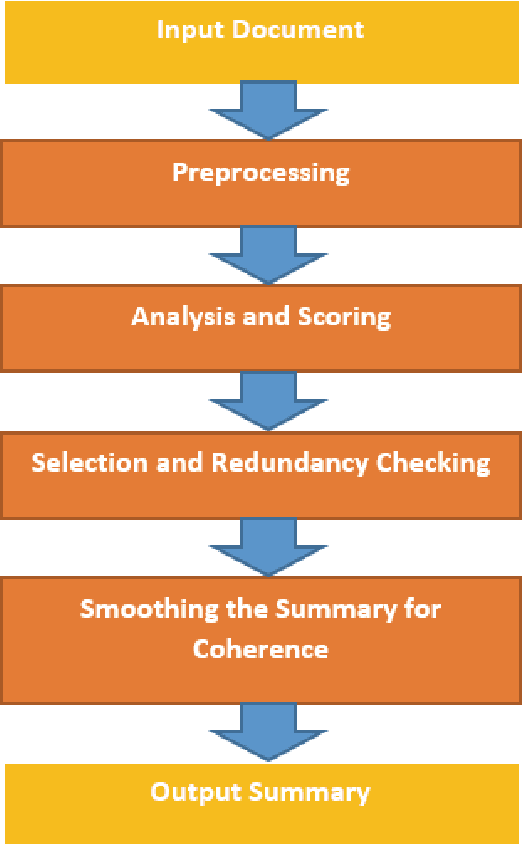
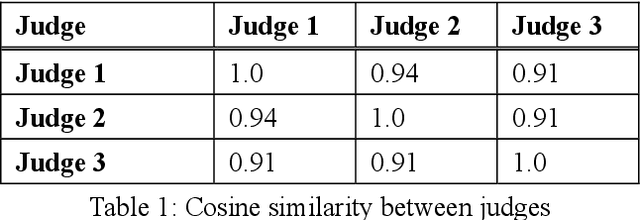
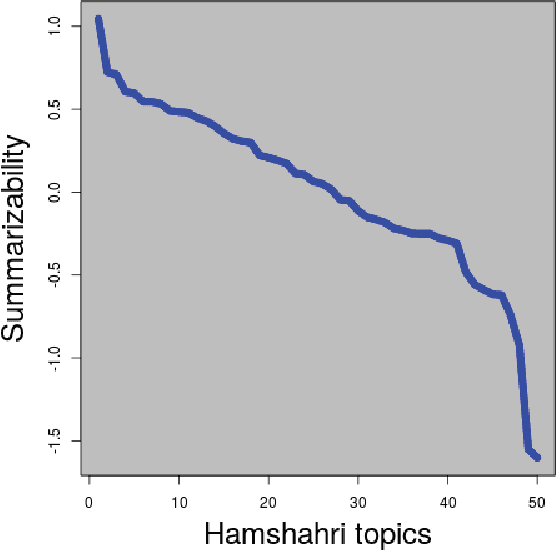
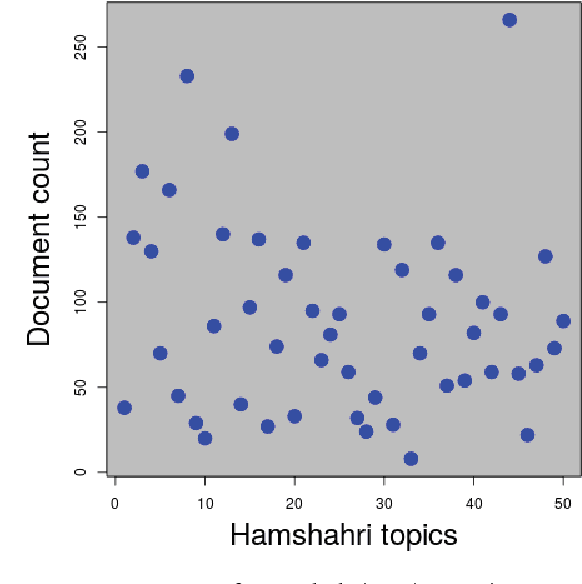
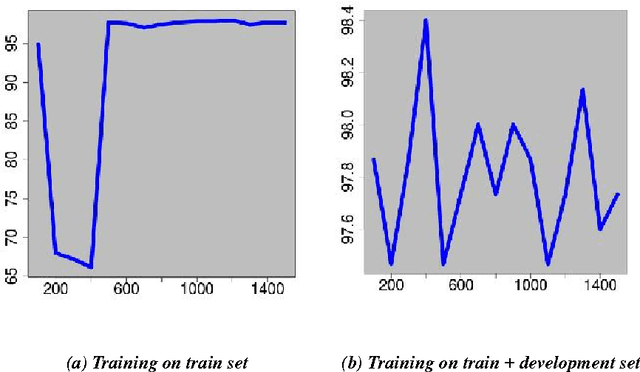
In this paper we explore the problem of document summarization in Persian language from two distinct angles. In our first approach, we modify a popular and widely cited Persian document summarization framework to see how it works on a realistic corpus of news articles. Human evaluation on generated summaries shows that graph-based methods perform better than the modified systems. We carry this intuition forward in our second approach, and probe deeper into the nature of graph-based systems by designing several summarizers based on centrality measures. Ad hoc evaluation using ROUGE score on these summarizers suggests that there is a small class of centrality measures that perform better than three strong unsupervised baselines.
Inter-Rater Agreement Study on Readability Assessment in Bengali
Jul 08, 2014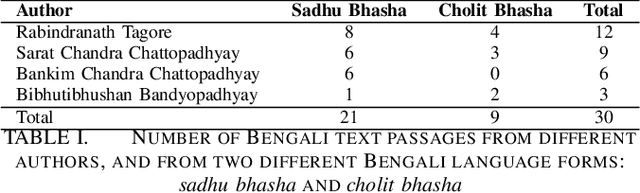


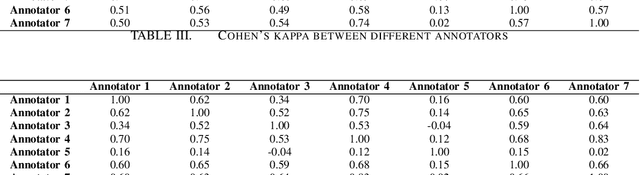
An inter-rater agreement study is performed for readability assessment in Bengali. A 1-7 rating scale was used to indicate different levels of readability. We obtained moderate to fair agreement among seven independent annotators on 30 text passages written by four eminent Bengali authors. As a by product of our study, we obtained a readability-annotated ground truth dataset in Bengali. .
* 6 pages, 4 tables, Accepted in ICCONAC, 2014
Inter-rater Agreement on Sentence Formality
Apr 20, 2014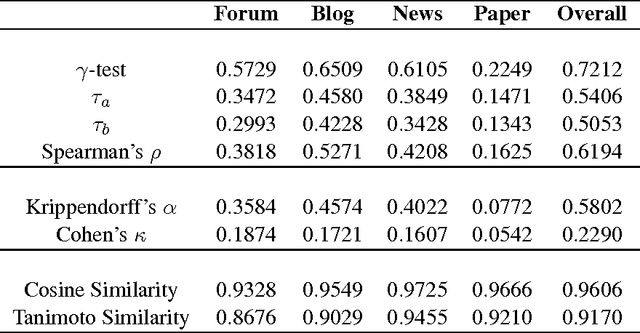
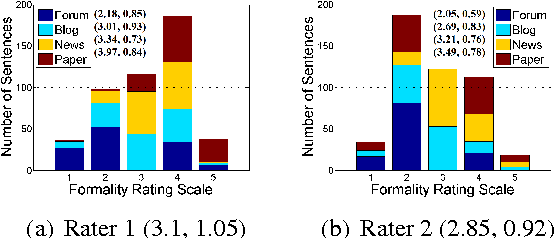
Formality is one of the most important dimensions of writing style variation. In this study we conducted an inter-rater reliability experiment for assessing sentence formality on a five-point Likert scale, and obtained good agreement results as well as different rating distributions for different sentence categories. We also performed a difficulty analysis to identify the bottlenecks of our rating procedure. Our main objective is to design an automatic scoring mechanism for sentence-level formality, and this study is important for that purpose.
Keyword and Keyphrase Extraction Using Centrality Measures on Collocation Networks
Jan 25, 2014
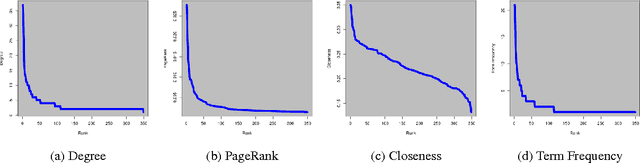
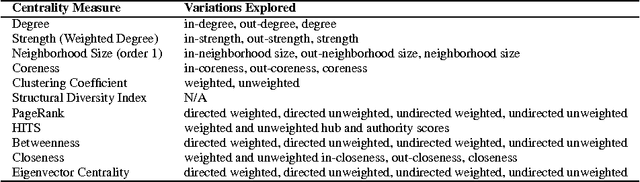
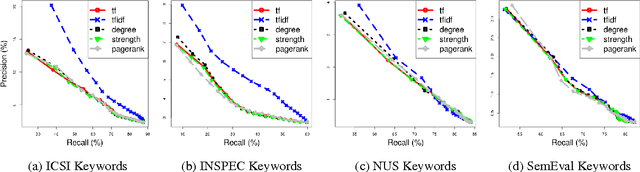
Keyword and keyphrase extraction is an important problem in natural language processing, with applications ranging from summarization to semantic search to document clustering. Graph-based approaches to keyword and keyphrase extraction avoid the problem of acquiring a large in-domain training corpus by applying variants of PageRank algorithm on a network of words. Although graph-based approaches are knowledge-lean and easily adoptable in online systems, it remains largely open whether they can benefit from centrality measures other than PageRank. In this paper, we experiment with an array of centrality measures on word and noun phrase collocation networks, and analyze their performance on four benchmark datasets. Not only are there centrality measures that perform as well as or better than PageRank, but they are much simpler (e.g., degree, strength, and neighborhood size). Furthermore, centrality-based methods give results that are competitive with and, in some cases, better than two strong unsupervised baselines.
Authorship Attribution Using Word Network Features
Nov 12, 2013
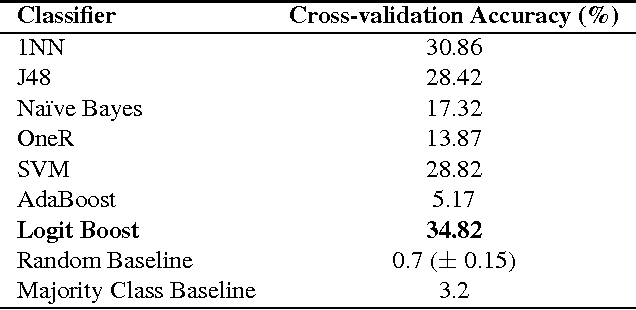
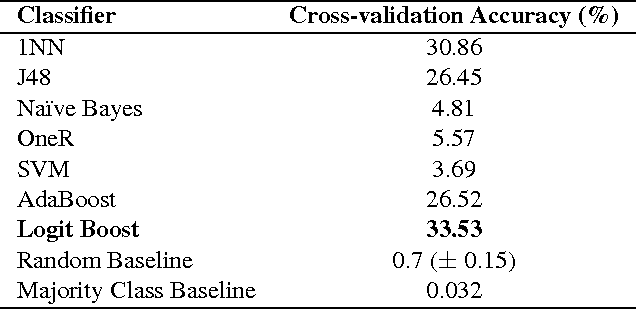

In this paper, we explore a set of novel features for authorship attribution of documents. These features are derived from a word network representation of natural language text. As has been noted in previous studies, natural language tends to show complex network structure at word level, with low degrees of separation and scale-free (power law) degree distribution. There has also been work on authorship attribution that incorporates ideas from complex networks. The goal of our paper is to explore properties of these complex networks that are suitable as features for machine-learning-based authorship attribution of documents. We performed experiments on three different datasets, and obtained promising results.