 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeyword and Keyphrase Extraction Using Centrality Measures on Collocation Networks
Paper and Code
Jan 25, 2014
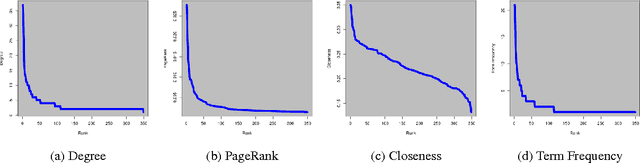
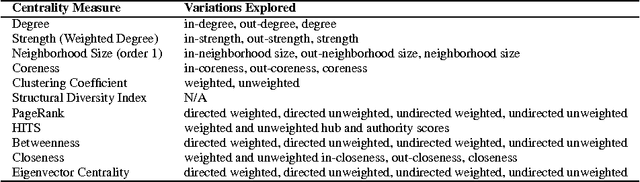
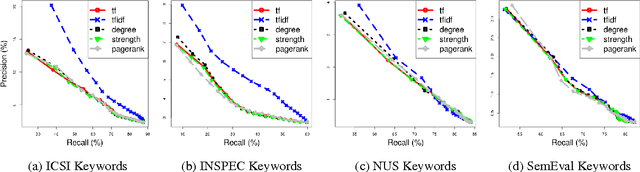
Keyword and keyphrase extraction is an important problem in natural language processing, with applications ranging from summarization to semantic search to document clustering. Graph-based approaches to keyword and keyphrase extraction avoid the problem of acquiring a large in-domain training corpus by applying variants of PageRank algorithm on a network of words. Although graph-based approaches are knowledge-lean and easily adoptable in online systems, it remains largely open whether they can benefit from centrality measures other than PageRank. In this paper, we experiment with an array of centrality measures on word and noun phrase collocation networks, and analyze their performance on four benchmark datasets. Not only are there centrality measures that perform as well as or better than PageRank, but they are much simpler (e.g., degree, strength, and neighborhood size). Furthermore, centrality-based methods give results that are competitive with and, in some cases, better than two strong unsupervised baselines.