 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQUINKY! A Corpus of Sentence-level Formality, Informativeness, and Implicature
Paper and Code
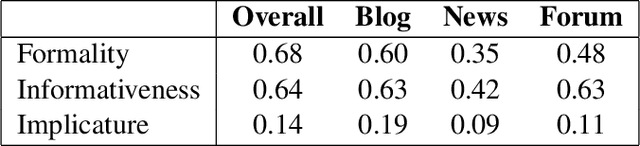
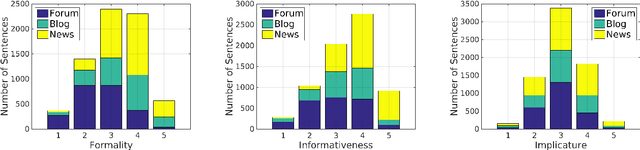

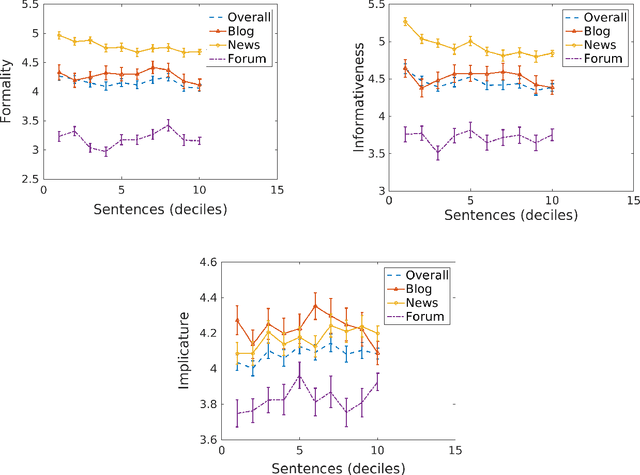
We introduce a corpus of 7,032 sentences rated by human annotators for formality, informativeness, and implicature on a 1-7 scale. The corpus was annotated using Amazon Mechanical Turk. Reliability in the obtained judgments was examined by comparing mean ratings across two MTurk experiments, and correlation with pilot annotations (on sentence formality) conducted in a more controlled setting. Despite the subjectivity and inherent difficulty of the annotation task, correlations between mean ratings were quite encouraging, especially on formality and informativeness. We further explored correlation between the three linguistic variables, genre-wise variation of ratings and correlations within genres, compatibility with automatic stylistic scoring, and sentential make-up of a document in terms of style. To date, our corpus is the largest sentence-level annotated corpus released for formality, informativeness, and implicature.