Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuthorship Attribution Using Word Network Features
Paper and Code
Nov 12, 2013
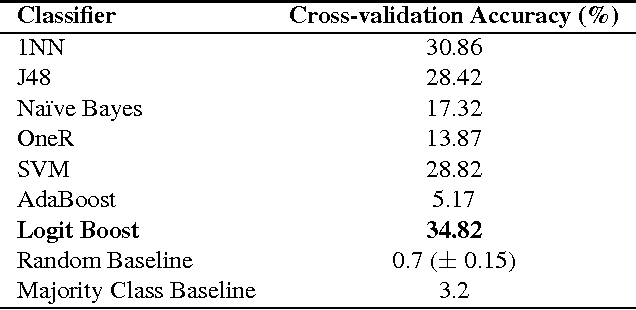
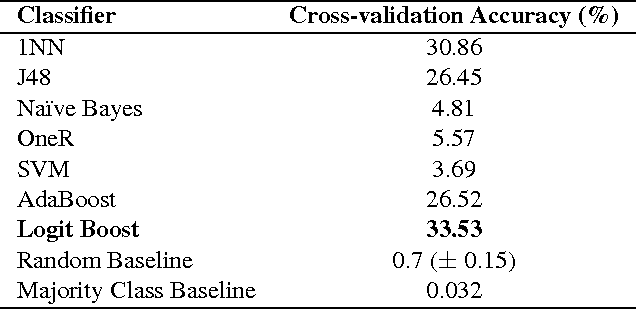

In this paper, we explore a set of novel features for authorship attribution of documents. These features are derived from a word network representation of natural language text. As has been noted in previous studies, natural language tends to show complex network structure at word level, with low degrees of separation and scale-free (power law) degree distribution. There has also been work on authorship attribution that incorporates ideas from complex networks. The goal of our paper is to explore properties of these complex networks that are suitable as features for machine-learning-based authorship attribution of documents. We performed experiments on three different datasets, and obtained promising results.
View paper on