 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Query Adversarial Attack on Black-box Automatic Speech Recognition Systems
Jun 27, 2024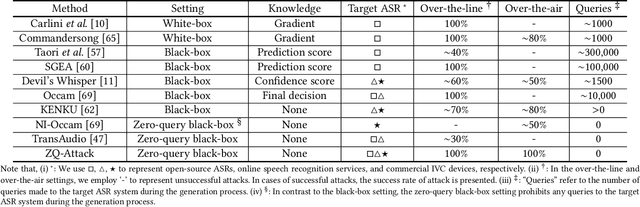


In recent years, extensive research has been conducted on the vulnerability of ASR systems, revealing that black-box adversarial example attacks pose significant threats to real-world ASR systems. However, most existing black-box attacks rely on queries to the target ASRs, which is impractical when queries are not permitted. In this paper, we propose ZQ-Attack, a transfer-based adversarial attack on ASR systems in the zero-query black-box setting. Through a comprehensive review and categorization of modern ASR technologies, we first meticulously select surrogate ASRs of diverse types to generate adversarial examples. Following this, ZQ-Attack initializes the adversarial perturbation with a scaled target command audio, rendering it relatively imperceptible while maintaining effectiveness. Subsequently, to achieve high transferability of adversarial perturbations, we propose a sequential ensemble optimization algorithm, which iteratively optimizes the adversarial perturbation on each surrogate model, leveraging collaborative information from other models. We conduct extensive experiments to evaluate ZQ-Attack. In the over-the-line setting, ZQ-Attack achieves a 100% success rate of attack (SRoA) with an average signal-to-noise ratio (SNR) of 21.91dB on 4 online speech recognition services, and attains an average SRoA of 100% and SNR of 19.67dB on 16 open-source ASRs. For commercial intelligent voice control devices, ZQ-Attack also achieves a 100% SRoA with an average SNR of 15.77dB in the over-the-air setting.
Black-box Adversarial Attacks on Commercial Speech Platforms with Minimal Information
Oct 19, 2021



Adversarial attacks against commercial black-box speech platforms, including cloud speech APIs and voice control devices, have received little attention until recent years. The current "black-box" attacks all heavily rely on the knowledge of prediction/confidence scores to craft effective adversarial examples, which can be intuitively defended by service providers without returning these messages. In this paper, we propose two novel adversarial attacks in more practical and rigorous scenarios. For commercial cloud speech APIs, we propose Occam, a decision-only black-box adversarial attack, where only final decisions are available to the adversary. In Occam, we formulate the decision-only AE generation as a discontinuous large-scale global optimization problem, and solve it by adaptively decomposing this complicated problem into a set of sub-problems and cooperatively optimizing each one. Our Occam is a one-size-fits-all approach, which achieves 100% success rates of attacks with an average SNR of 14.23dB, on a wide range of popular speech and speaker recognition APIs, including Google, Alibaba, Microsoft, Tencent, iFlytek, and Jingdong, outperforming the state-of-the-art black-box attacks. For commercial voice control devices, we propose NI-Occam, the first non-interactive physical adversarial attack, where the adversary does not need to query the oracle and has no access to its internal information and training data. We combine adversarial attacks with model inversion attacks, and thus generate the physically-effective audio AEs with high transferability without any interaction with target devices. Our experimental results show that NI-Occam can successfully fool Apple Siri, Microsoft Cortana, Google Assistant, iFlytek and Amazon Echo with an average SRoA of 52% and SNR of 9.65dB, shedding light on non-interactive physical attacks against voice control devices.