 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixing Gaussian Mixture VAEs for Interpretable Text Generation
Jun 16, 2019
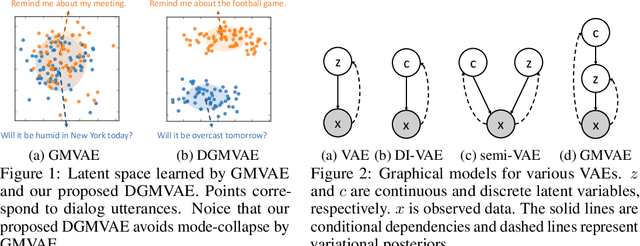


Variational auto-encoder (VAE) with Gaussian priors is effective in text generation. To improve the controllability and interpretability, we propose to use Gaussian mixture distribution as the prior for VAE (GMVAE), since it includes an extra discrete latent variable in addition to the continuous one. Unfortunately, training GMVAE using standard variational approximation often leads to the mode-collapse problem. We theoretically analyze the root cause --- maximizing the evidence lower bound of GMVAE implicitly aggregates the means of multiple Gaussian priors. We propose Dispersed-GMVAE (DGMVAE), an improved model for text generation. It introduces two extra terms to alleviate mode-collapse and to induce a better structured latent space. Experimental results show that DGMVAE outperforms strong baselines in several language modeling and text generation benchmarks.
An Efficient Character-Level Neural Machine Translation
Aug 19, 2016

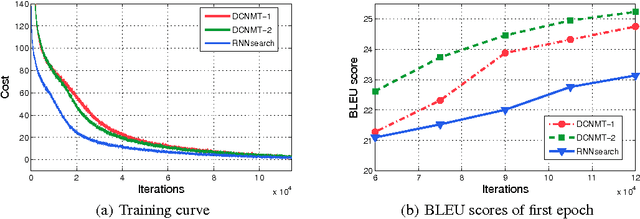
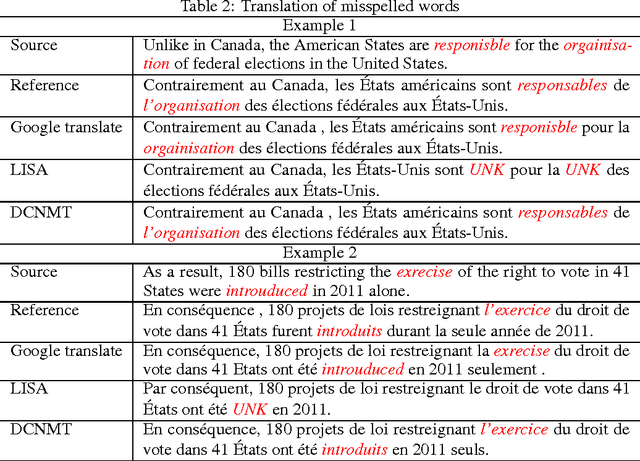
Neural machine translation aims at building a single large neural network that can be trained to maximize translation performance. The encoder-decoder architecture with an attention mechanism achieves a translation performance comparable to the existing state-of-the-art phrase-based systems on the task of English-to-French translation. However, the use of large vocabulary becomes the bottleneck in both training and improving the performance. In this paper, we propose an efficient architecture to train a deep character-level neural machine translation by introducing a decimator and an interpolator. The decimator is used to sample the source sequence before encoding while the interpolator is used to resample after decoding. Such a deep model has two major advantages. It avoids the large vocabulary issue radically; at the same time, it is much faster and more memory-efficient in training than conventional character-based models. More interestingly, our model is able to translate the misspelled word like human beings.
A Scalable and Extensible Framework for Superposition-Structured Models
Mar 08, 2016

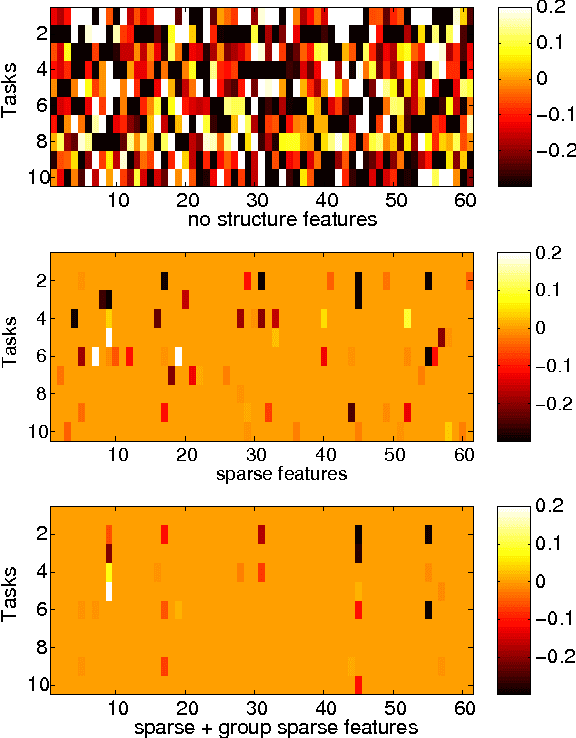

In many learning tasks, structural models usually lead to better interpretability and higher generalization performance. In recent years, however, the simple structural models such as lasso are frequently proved to be insufficient. Accordingly, there has been a lot of work on "superposition-structured" models where multiple structural constraints are imposed. To efficiently solve these "superposition-structured" statistical models, we develop a framework based on a proximal Newton-type method. Employing the smoothed conic dual approach with the LBFGS updating formula, we propose a scalable and extensible proximal quasi-Newton (SEP-QN) framework. Empirical analysis on various datasets shows that our framework is potentially powerful, and achieves super-linear convergence rate for optimizing some popular "superposition-structured" statistical models such as the fused sparse group lasso.