 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixing Gaussian Mixture VAEs for Interpretable Text Generation
Paper and Code

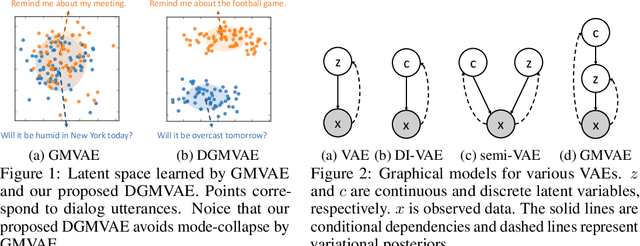


Variational auto-encoder (VAE) with Gaussian priors is effective in text generation. To improve the controllability and interpretability, we propose to use Gaussian mixture distribution as the prior for VAE (GMVAE), since it includes an extra discrete latent variable in addition to the continuous one. Unfortunately, training GMVAE using standard variational approximation often leads to the mode-collapse problem. We theoretically analyze the root cause --- maximizing the evidence lower bound of GMVAE implicitly aggregates the means of multiple Gaussian priors. We propose Dispersed-GMVAE (DGMVAE), an improved model for text generation. It introduces two extra terms to alleviate mode-collapse and to induce a better structured latent space. Experimental results show that DGMVAE outperforms strong baselines in several language modeling and text generation benchmarks.