 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Character-Level Neural Machine Translation
Paper and Code


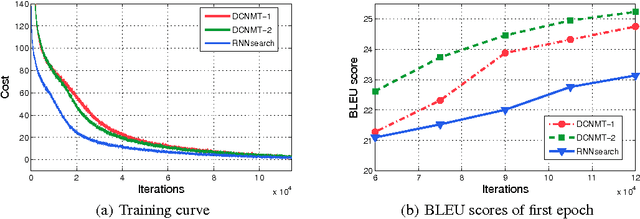
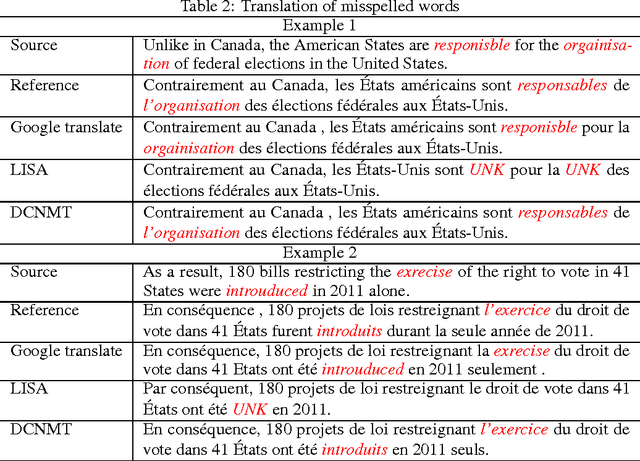
Neural machine translation aims at building a single large neural network that can be trained to maximize translation performance. The encoder-decoder architecture with an attention mechanism achieves a translation performance comparable to the existing state-of-the-art phrase-based systems on the task of English-to-French translation. However, the use of large vocabulary becomes the bottleneck in both training and improving the performance. In this paper, we propose an efficient architecture to train a deep character-level neural machine translation by introducing a decimator and an interpolator. The decimator is used to sample the source sequence before encoding while the interpolator is used to resample after decoding. Such a deep model has two major advantages. It avoids the large vocabulary issue radically; at the same time, it is much faster and more memory-efficient in training than conventional character-based models. More interestingly, our model is able to translate the misspelled word like human beings.