 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Network Training with Data Tiering
Nov 10, 2021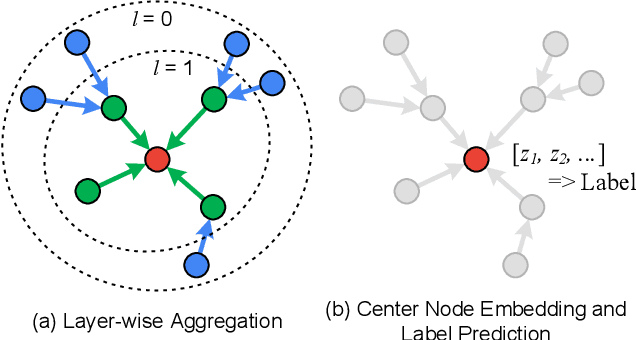
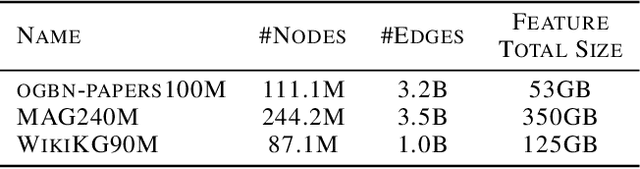
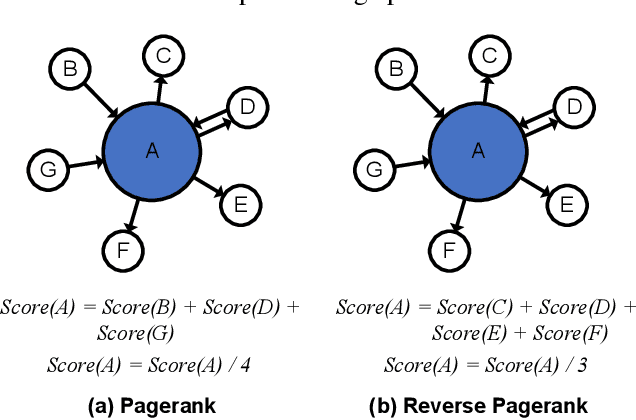
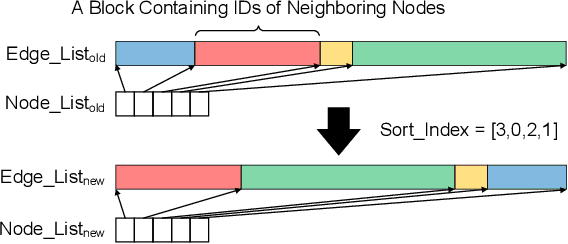
Graph Neural Networks (GNNs) have shown success in learning from graph-structured data, with applications to fraud detection, recommendation, and knowledge graph reasoning. However, training GNN efficiently is challenging because: 1) GPU memory capacity is limited and can be insufficient for large datasets, and 2) the graph-based data structure causes irregular data access patterns. In this work, we provide a method to statistical analyze and identify more frequently accessed data ahead of GNN training. Our data tiering method not only utilizes the structure of input graph, but also an insight gained from actual GNN training process to achieve a higher prediction result. With our data tiering method, we additionally provide a new data placement and access strategy to further minimize the CPU-GPU communication overhead. We also take into account of multi-GPU GNN training as well and we demonstrate the effectiveness of our strategy in a multi-GPU system. The evaluation results show that our work reduces CPU-GPU traffic by 87-95% and improves the training speed of GNN over the existing solutions by 1.6-2.1x on graphs with hundreds of millions of nodes and billions of edges.
Large Graph Convolutional Network Training with GPU-Oriented Data Communication Architecture
Mar 04, 2021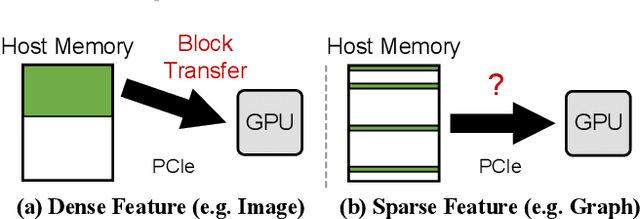


Graph Convolutional Networks (GCNs) are increasingly adopted in large-scale graph-based recommender systems. Training GCN requires the minibatch generator traversing graphs and sampling the sparsely located neighboring nodes to obtain their features. Since real-world graphs often exceed the capacity of GPU memory, current GCN training systems keep the feature table in host memory and rely on the CPU to collect sparse features before sending them to the GPUs. This approach, however, puts tremendous pressure on host memory bandwidth and the CPU. This is because the CPU needs to (1) read sparse features from memory, (2) write features into memory as a dense format, and (3) transfer the features from memory to the GPUs. In this work, we propose a novel GPU-oriented data communication approach for GCN training, where GPU threads directly access sparse features in host memory through zero-copy accesses without much CPU help. By removing the CPU gathering stage, our method significantly reduces the consumption of the host resources and data access latency. We further present two important techniques to achieve high host memory access efficiency by the GPU: (1) automatic data access address alignment to maximize PCIe packet efficiency, and (2) asynchronous zero-copy access and kernel execution to fully overlap data transfer with training. We incorporate our method into PyTorch and evaluate its effectiveness using several graphs with sizes up to 111 million nodes and 1.6 billion edges. In a multi-GPU training setup, our method is 65-92% faster than the conventional data transfer method, and can even match the performance of all-in-GPU-memory training for some graphs that fit in GPU memory.
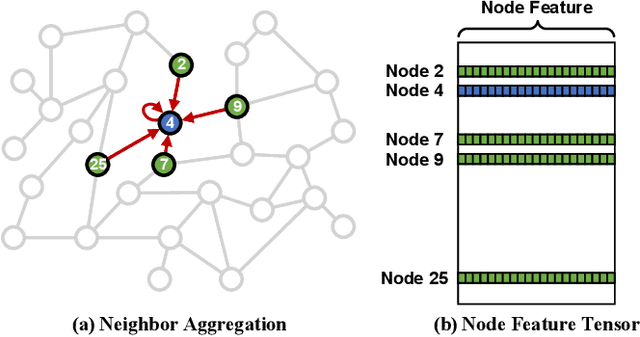
PyTorch-Direct: Enabling GPU Centric Data Access for Very Large Graph Neural Network Training with Irregular Accesses
Jan 20, 2021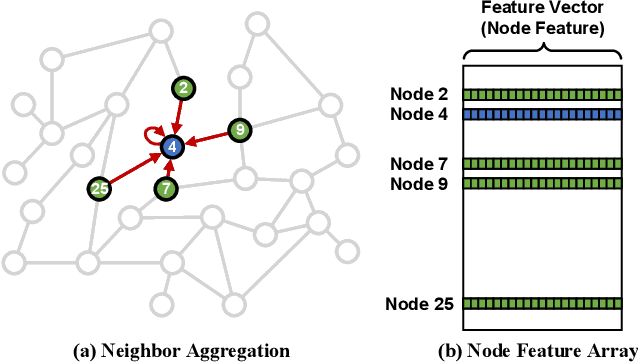

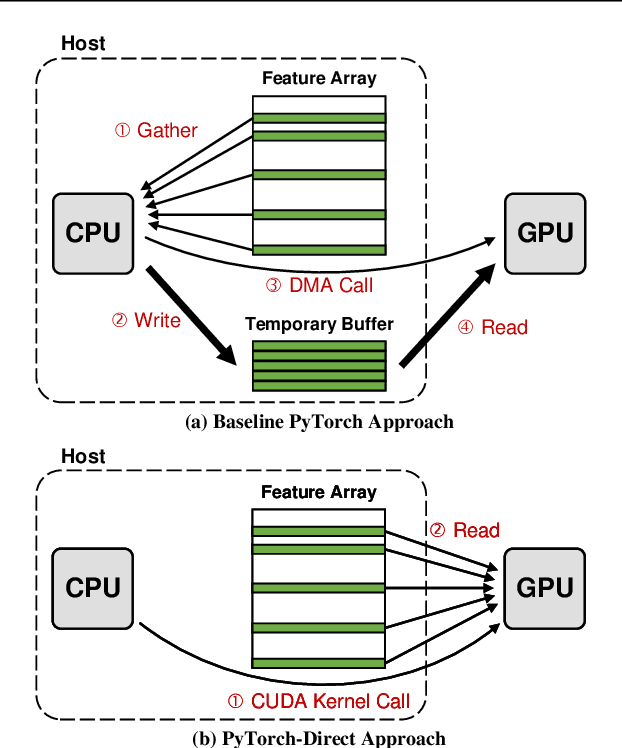

With the increasing adoption of graph neural networks (GNNs) in the machine learning community, GPUs have become an essential tool to accelerate GNN training. However, training GNNs on very large graphs that do not fit in GPU memory is still a challenging task. Unlike conventional neural networks, mini-batching input samples in GNNs requires complicated tasks such as traversing neighboring nodes and gathering their feature values. While this process accounts for a significant portion of the training time, we find existing GNN implementations using popular deep neural network (DNN) libraries such as PyTorch are limited to a CPU-centric approach for the entire data preparation step. This "all-in-CPU" approach has negative impact on the overall GNN training performance as it over-utilizes CPU resources and hinders GPU acceleration of GNN training. To overcome such limitations, we introduce PyTorch-Direct, which enables a GPU-centric data accessing paradigm for GNN training. In PyTorch-Direct, GPUs are capable of efficiently accessing complicated data structures in host memory directly without CPU intervention. Our microbenchmark and end-to-end GNN training results show that PyTorch-Direct reduces data transfer time by 47.1% on average and speeds up GNN training by up to 1.6x. Furthermore, by reducing CPU utilization, PyTorch-Direct also saves system power by 12.4% to 17.5% during training. To minimize programmer effort, we introduce a new "unified tensor" type along with necessary changes to the PyTorch memory allocator, dispatch logic, and placement rules. As a result, users need to change at most two lines of their PyTorch GNN training code for each tensor object to take advantage of PyTorch-Direct.