 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation and Comparison of Visual Language Models for Transportation Engineering Problems
Sep 03, 2024



Recent developments in vision language models (VLM) have shown great potential for diverse applications related to image understanding. In this study, we have explored state-of-the-art VLM models for vision-based transportation engineering tasks such as image classification and object detection. The image classification task involves congestion detection and crack identification, whereas, for object detection, helmet violations were identified. We have applied open-source models such as CLIP, BLIP, OWL-ViT, Llava-Next, and closed-source GPT-4o to evaluate the performance of these state-of-the-art VLM models to harness the capabilities of language understanding for vision-based transportation tasks. These tasks were performed by applying zero-shot prompting to the VLM models, as zero-shot prompting involves performing tasks without any training on those tasks. It eliminates the need for annotated datasets or fine-tuning for specific tasks. Though these models gave comparative results with benchmark Convolutional Neural Networks (CNN) models in the image classification tasks, for object localization tasks, it still needs improvement. Therefore, this study provides a comprehensive evaluation of the state-of-the-art VLM models highlighting the advantages and limitations of the models, which can be taken as the baseline for future improvement and wide-scale implementation.
The 8th AI City Challenge
Apr 15, 2024
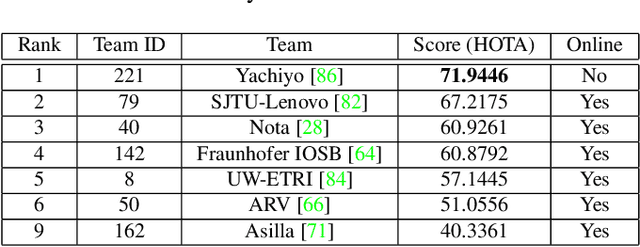

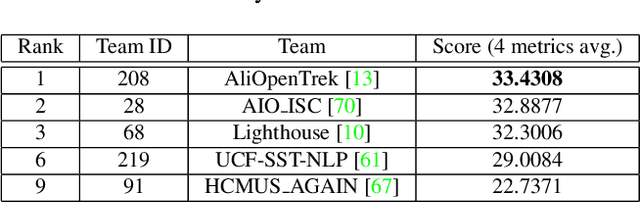
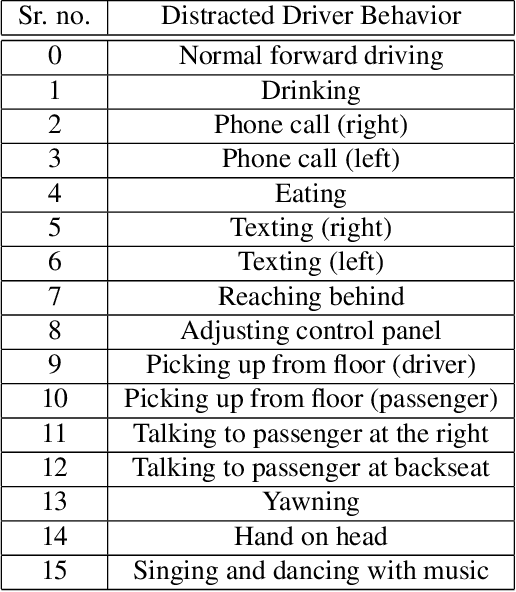
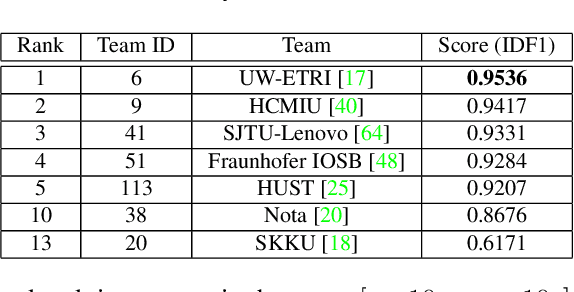
The eighth AI City Challenge highlighted the convergence of computer vision and artificial intelligence in areas like retail, warehouse settings, and Intelligent Traffic Systems (ITS), presenting significant research opportunities. The 2024 edition featured five tracks, attracting unprecedented interest from 726 teams in 47 countries and regions. Track 1 dealt with multi-target multi-camera (MTMC) people tracking, highlighting significant enhancements in camera count, character number, 3D annotation, and camera matrices, alongside new rules for 3D tracking and online tracking algorithm encouragement. Track 2 introduced dense video captioning for traffic safety, focusing on pedestrian accidents using multi-camera feeds to improve insights for insurance and prevention. Track 3 required teams to classify driver actions in a naturalistic driving analysis. Track 4 explored fish-eye camera analytics using the FishEye8K dataset. Track 5 focused on motorcycle helmet rule violation detection. The challenge utilized two leaderboards to showcase methods, with participants setting new benchmarks, some surpassing existing state-of-the-art achievements.
The 7th AI City Challenge
Apr 15, 2023

The AI City Challenge's seventh edition emphasizes two domains at the intersection of computer vision and artificial intelligence - retail business and Intelligent Traffic Systems (ITS) - that have considerable untapped potential. The 2023 challenge had five tracks, which drew a record-breaking number of participation requests from 508 teams across 46 countries. Track 1 was a brand new track that focused on multi-target multi-camera (MTMC) people tracking, where teams trained and evaluated using both real and highly realistic synthetic data. Track 2 centered around natural-language-based vehicle track retrieval. Track 3 required teams to classify driver actions in naturalistic driving analysis. Track 4 aimed to develop an automated checkout system for retail stores using a single view camera. Track 5, another new addition, tasked teams with detecting violations of the helmet rule for motorcyclists. Two leader boards were released for submissions based on different methods: a public leader board for the contest where external private data wasn't allowed and a general leader board for all results submitted. The participating teams' top performances established strong baselines and even outperformed the state-of-the-art in the proposed challenge tracks.