 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tutorial on Non-Terrestrial Networks: Towards Global and Ubiquitous 6G Connectivity
Dec 21, 2024



The International Mobile Telecommunications (IMT)-2030 framework recently adopted by the International Telecommunication Union Radiocommunication Sector (ITU-R) envisions 6G networks to deliver intelligent, seamless connectivity that supports reliable, sustainable, and resilient communications. Recent developments in the 3rd Generation Partnership Project (3GPP) Releases 17-19, particularly within the Radio Access Network (RAN)4 working group addressing satellite and cellular spectrum sharing and RAN2 enhancing New Radio (NR)/IoT for NTN, highlight the critical role NTN is set to play in the evolution of 6G standards. The integration of advanced signal processing, edge and cloud computing, and Deep Reinforcement Learning (DRL) for Low Earth Orbit (LEO) satellites and aerial platforms, such as Uncrewed Aerial Vehicles (UAV) and high-, medium-, and low-altitude platform stations, has revolutionized the convergence of space, aerial, and Terrestrial Networks (TN). Artificial Intelligence (AI)-powered deployments for NTN and NTN-IoT, combined with Next Generation Multiple Access (NGMA) technologies, have dramatically reshaped global connectivity. This tutorial paper provides a comprehensive exploration of emerging NTN-based 6G wireless networks, covering vision, alignment with 5G-Advanced and 6G standards, key principles, trends, challenges, real-world applications, and novel problem solving frameworks. It examines essential enabling technologies like AI for NTN (LEO satellites and aerial platforms), DRL, edge computing for NTN, AI for NTN trajectory optimization, Reconfigurable Intelligent Surfaces (RIS)-enhanced NTN, and robust Multiple-Input-Multiple-Output (MIMO) beamforming. Furthermore, it addresses interference management through NGMA, including Rate-Splitting Multiple Access (RSMA) for NTN, and the use of aerial platforms for access, relay, and fronthaul/backhaul connectivity.
Emotions Beyond Words: Non-Speech Audio Emotion Recognition With Edge Computing
May 01, 2023Non-speech emotion recognition has a wide range of applications including healthcare, crime control and rescue, and entertainment, to name a few. Providing these applications using edge computing has great potential, however, recent studies are focused on speech-emotion recognition using complex architectures. In this paper, a non-speech-based emotion recognition system is proposed, which can rely on edge computing to analyse emotions conveyed through non-speech expressions like screaming and crying. In particular, we explore knowledge distillation to design a computationally efficient system that can be deployed on edge devices with limited resources without degrading the performance significantly. We comprehensively evaluate our proposed framework using two publicly available datasets and highlight its effectiveness by comparing the results with the well-known MobileNet model. Our results demonstrate the feasibility and effectiveness of using edge computing for non-speech emotion detection, which can potentially improve applications that rely on emotion detection in communication networks. To the best of our knowledge, this is the first work on an edge-computing-based framework for detecting emotions in non-speech audio, offering promising directions for future research.
Deep Learning for Lip Reading using Audio-Visual Information for Urdu Language
Feb 15, 2018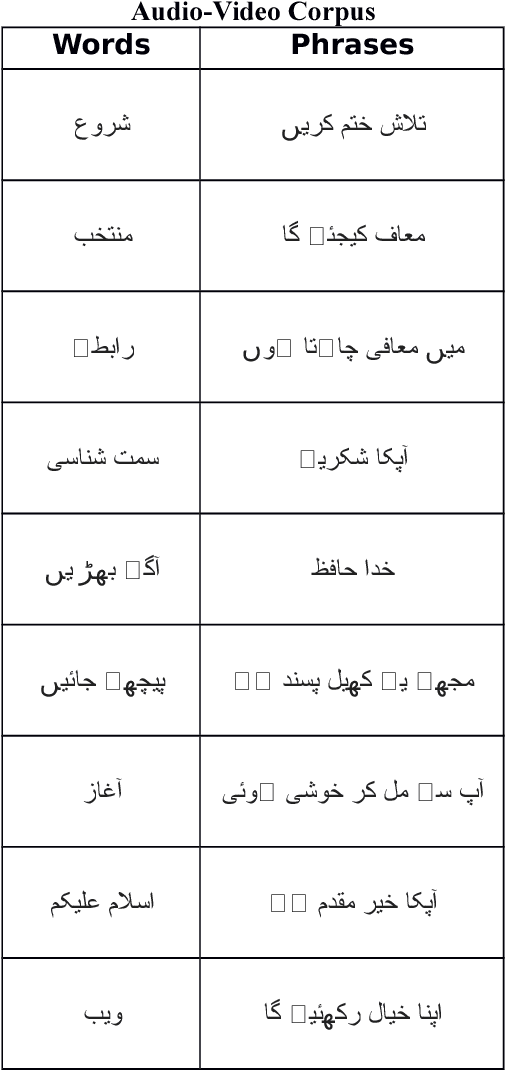



Human lip-reading is a challenging task. It requires not only knowledge of underlying language but also visual clues to predict spoken words. Experts need certain level of experience and understanding of visual expressions learning to decode spoken words. Now-a-days, with the help of deep learning it is possible to translate lip sequences into meaningful words. The speech recognition in the noisy environments can be increased with the visual information [1]. To demonstrate this, in this project, we have tried to train two different deep-learning models for lip-reading: first one for video sequences using spatiotemporal convolution neural network, Bi-gated recurrent neural network and Connectionist Temporal Classification Loss, and second for audio that inputs the MFCC features to a layer of LSTM cells and output the sequence. We have also collected a small audio-visual dataset to train and test our model. Our target is to integrate our both models to improve the speech recognition in the noisy environment