 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Lip Reading using Audio-Visual Information for Urdu Language
Paper and Code
Feb 15, 2018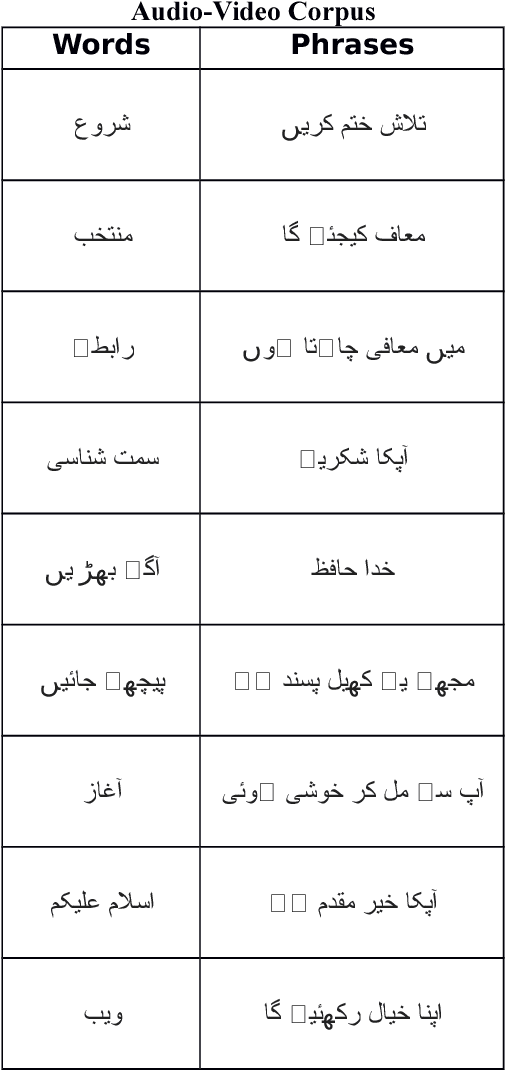



Human lip-reading is a challenging task. It requires not only knowledge of underlying language but also visual clues to predict spoken words. Experts need certain level of experience and understanding of visual expressions learning to decode spoken words. Now-a-days, with the help of deep learning it is possible to translate lip sequences into meaningful words. The speech recognition in the noisy environments can be increased with the visual information [1]. To demonstrate this, in this project, we have tried to train two different deep-learning models for lip-reading: first one for video sequences using spatiotemporal convolution neural network, Bi-gated recurrent neural network and Connectionist Temporal Classification Loss, and second for audio that inputs the MFCC features to a layer of LSTM cells and output the sequence. We have also collected a small audio-visual dataset to train and test our model. Our target is to integrate our both models to improve the speech recognition in the noisy environment