 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimism, Expectation, or Sarcasm? Multi-Class Hope Speech Detection in Spanish and English
Apr 24, 2025
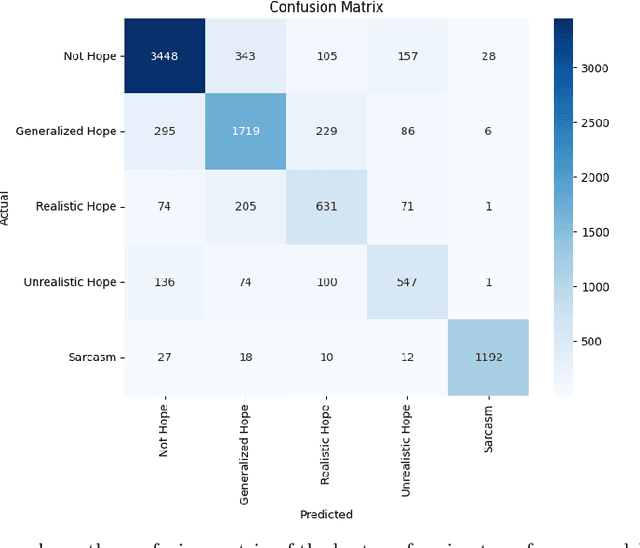
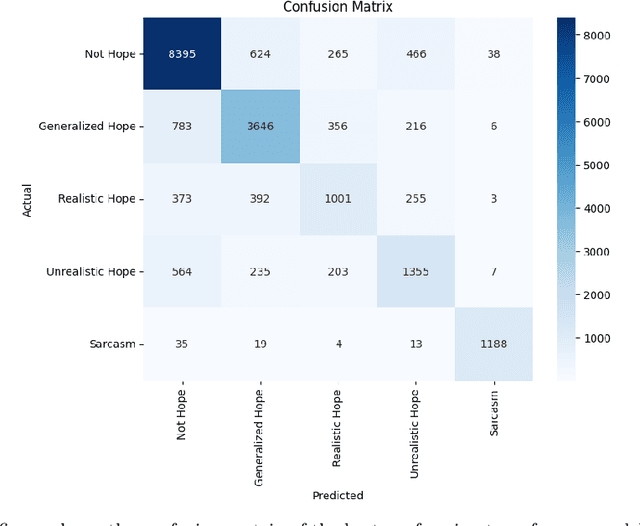
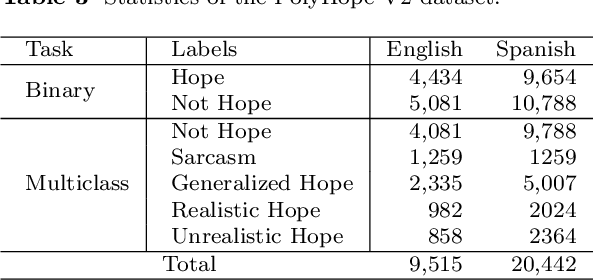
Hope is a complex and underexplored emotional state that plays a significant role in education, mental health, and social interaction. Unlike basic emotions, hope manifests in nuanced forms ranging from grounded optimism to exaggerated wishfulness or sarcasm, making it difficult for Natural Language Processing systems to detect accurately. This study introduces PolyHope V2, a multilingual, fine-grained hope speech dataset comprising over 30,000 annotated tweets in English and Spanish. This resource distinguishes between four hope subtypes Generalized, Realistic, Unrealistic, and Sarcastic and enhances existing datasets by explicitly labeling sarcastic instances. We benchmark multiple pretrained transformer models and compare them with large language models (LLMs) such as GPT 4 and Llama 3 under zero-shot and few-shot regimes. Our findings show that fine-tuned transformers outperform prompt-based LLMs, especially in distinguishing nuanced hope categories and sarcasm. Through qualitative analysis and confusion matrices, we highlight systematic challenges in separating closely related hope subtypes. The dataset and results provide a robust foundation for future emotion recognition tasks that demand greater semantic and contextual sensitivity across languages.
Tec-Habilidad: Skill Classification for Bridging Education and Employment
Mar 05, 2025
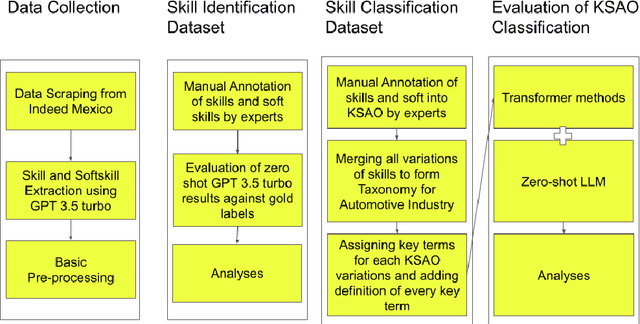

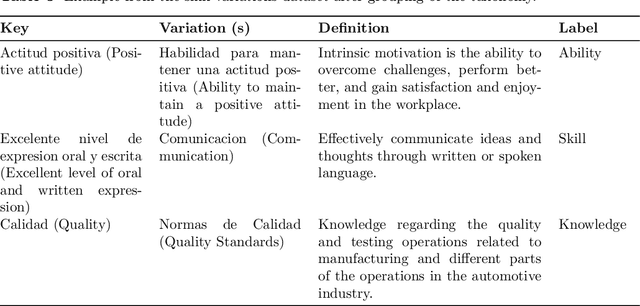
Job application and assessment processes have evolved significantly in recent years, largely due to advancements in technology and changes in the way companies operate. Skill extraction and classification remain an important component of the modern hiring process as it provides a more objective way to evaluate candidates and automatically align their skills with the job requirements. However, to effectively evaluate the skills, the skill extraction tools must recognize varied mentions of skills on resumes, including direct mentions, implications, synonyms, acronyms, phrases, and proficiency levels, and differentiate between hard and soft skills. While tools like LLMs (Large Model Models) help extract and categorize skills from job applications, there's a lack of comprehensive datasets for evaluating the effectiveness of these models in accurately identifying and classifying skills in Spanish-language job applications. This gap hinders our ability to assess the reliability and precision of the models, which is crucial for ensuring that the selected candidates truly possess the required skills for the job. In this paper, we develop a Spanish language dataset for skill extraction and classification, provide annotation methodology to distinguish between knowledge, skill, and abilities, and provide deep learning baselines to advance robust solutions for skill classification.
NLP Progress in Indigenous Latin American Languages
Apr 08, 2024



The paper focuses on the marginalization of indigenous language communities in the face of rapid technological advancements. We highlight the cultural richness of these languages and the risk they face of being overlooked in the realm of Natural Language Processing (NLP). We aim to bridge the gap between these communities and researchers, emphasizing the need for inclusive technological advancements that respect indigenous community perspectives. We show the NLP progress of indigenous Latin American languages and the survey that covers the status of indigenous languages in Latin America, their representation in NLP, and the challenges and innovations required for their preservation and development. The paper contributes to the current literature in understanding the need and progress of NLP for indigenous communities of Latin America, specifically low-resource and indigenous communities in general.
GuReT: Distinguishing Guilt and Regret related Text
Jan 29, 2024The intricate relationship between human decision-making and emotions, particularly guilt and regret, has significant implications on behavior and well-being. Yet, these emotions subtle distinctions and interplay are often overlooked in computational models. This paper introduces a dataset tailored to dissect the relationship between guilt and regret and their unique textual markers, filling a notable gap in affective computing research. Our approach treats guilt and regret recognition as a binary classification task and employs three machine learning and six transformer-based deep learning techniques to benchmark the newly created dataset. The study further implements innovative reasoning methods like chain-of-thought and tree-of-thought to assess the models interpretive logic. The results indicate a clear performance edge for transformer-based models, achieving a 90.4% macro F1 score compared to the 85.3% scored by the best machine learning classifier, demonstrating their superior capability in distinguishing complex emotional states.
Multi-class Regret Detection in Hindi Devanagari Script
Jan 29, 2024The number of Hindi speakers on social media has increased dramatically in recent years. Regret is a common emotional experience in our everyday life. Many speakers on social media, share their regretful experiences and opinions regularly. It might cause a re-evaluation of one's choices and a desire to make a different option if given the chance. As a result, knowing the source of regret is critical for investigating its impact on behavior and decision-making. This study focuses on regret and how it is expressed, specifically in Hindi, on various social media platforms. In our study, we present a novel dataset from three different sources, where each sentence has been manually classified into one of three classes "Regret by action", "Regret by inaction", and "No regret". Next, we use this dataset to investigate the linguistic expressions of regret in Hindi text and also identify the textual domains that are most frequently associated with regret. Our findings indicate that individuals on social media platforms frequently express regret for both past inactions and actions, particularly within the domain of interpersonal relationships. We use a pre-trained BERT model to generate word embeddings for the Hindi dataset and also compare deep learning models with conventional machine learning models in order to demonstrate accuracy. Our results show that BERT embedding with CNN consistently surpassed other models. This described the effectiveness of BERT for conveying the context and meaning of words in the regret domain.
ReDDIT: Regret Detection and Domain Identification from Text
Dec 14, 2022In this paper, we present a study of regret and its expression on social media platforms. Specifically, we present a novel dataset of Reddit texts that have been classified into three classes: Regret by Action, Regret by Inaction, and No Regret. We then use this dataset to investigate the language used to express regret on Reddit and to identify the domains of text that are most commonly associated with regret. Our findings show that Reddit users are most likely to express regret for past actions, particularly in the domain of relationships. We also found that deep learning models using GloVe embedding outperformed other models in all experiments, indicating the effectiveness of GloVe for representing the meaning and context of words in the domain of regret. Overall, our study provides valuable insights into the nature and prevalence of regret on social media, as well as the potential of deep learning and word embeddings for analyzing and understanding emotional language in online text. These findings have implications for the development of natural language processing algorithms and the design of social media platforms that support emotional expression and communication.
UrduFake@FIRE2021: Shared Track on Fake News Identification in Urdu
Jul 11, 2022
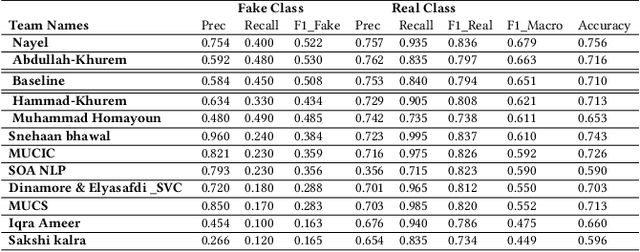

This study reports the second shared task named as UrduFake@FIRE2021 on identifying fake news detection in Urdu language. This is a binary classification problem in which the task is to classify a given news article into two classes: (i) real news, or (ii) fake news. In this shared task, 34 teams from 7 different countries (China, Egypt, Israel, India, Mexico, Pakistan, and UAE) registered to participate in the shared task, 18 teams submitted their experimental results and 11 teams submitted their technical reports. The proposed systems were based on various count-based features and used different classifiers as well as neural network architectures. The stochastic gradient descent (SGD) algorithm outperformed other classifiers and achieved 0.679 F-score.
Overview of the Shared Task on Fake News Detection in Urdu at FIRE 2021
Jul 11, 2022
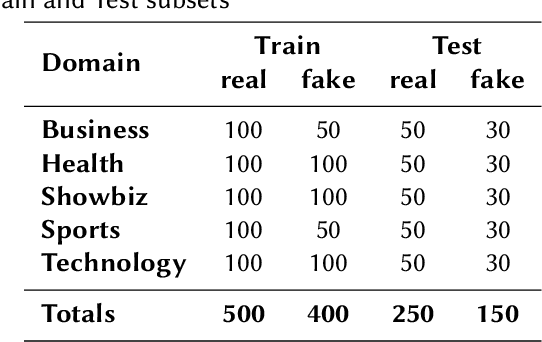


Automatic detection of fake news is a highly important task in the contemporary world. This study reports the 2nd shared task called UrduFake@FIRE2021 on identifying fake news detection in Urdu. The goal of the shared task is to motivate the community to come up with efficient methods for solving this vital problem, particularly for the Urdu language. The task is posed as a binary classification problem to label a given news article as a real or a fake news article. The organizers provide a dataset comprising news in five domains: (i) Health, (ii) Sports, (iii) Showbiz, (iv) Technology, and (v) Business, split into training and testing sets. The training set contains 1300 annotated news articles -- 750 real news, 550 fake news, while the testing set contains 300 news articles -- 200 real, 100 fake news. 34 teams from 7 different countries (China, Egypt, Israel, India, Mexico, Pakistan, and UAE) registered to participate in the UrduFake@FIRE2021 shared task. Out of those, 18 teams submitted their experimental results, and 11 of those submitted their technical reports, which is substantially higher compared to the UrduFake shared task in 2020 when only 6 teams submitted their technical reports. The technical reports submitted by the participants demonstrated different data representation techniques ranging from count-based BoW features to word vector embeddings as well as the use of numerous machine learning algorithms ranging from traditional SVM to various neural network architectures including Transformers such as BERT and RoBERTa. In this year's competition, the best performing system obtained an F1-macro score of 0.679, which is lower than the past year's best result of 0.907 F1-macro. Admittedly, while training sets from the past and the current years overlap to a large extent, the testing set provided this year is completely different.