 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of Abusive and Threatening Language Detection in Urdu at FIRE 2021
Jul 14, 2022



With the growth of social media platform influence, the effect of their misuse becomes more and more impactful. The importance of automatic detection of threatening and abusive language can not be overestimated. However, most of the existing studies and state-of-the-art methods focus on English as the target language, with limited work on low- and medium-resource languages. In this paper, we present two shared tasks of abusive and threatening language detection for the Urdu language which has more than 170 million speakers worldwide. Both are posed as binary classification tasks where participating systems are required to classify tweets in Urdu into two classes, namely: (i) Abusive and Non-Abusive for the first task, and (ii) Threatening and Non-Threatening for the second. We present two manually annotated datasets containing tweets labelled as (i) Abusive and Non-Abusive, and (ii) Threatening and Non-Threatening. The abusive dataset contains 2400 annotated tweets in the train part and 1100 annotated tweets in the test part. The threatening dataset contains 6000 annotated tweets in the train part and 3950 annotated tweets in the test part. We also provide logistic regression and BERT-based baseline classifiers for both tasks. In this shared task, 21 teams from six countries registered for participation (India, Pakistan, China, Malaysia, United Arab Emirates, and Taiwan), 10 teams submitted their runs for Subtask A, which is Abusive Language Detection and 9 teams submitted their runs for Subtask B, which is Threatening Language detection, and seven teams submitted their technical reports. The best performing system achieved an F1-score value of 0.880 for Subtask A and 0.545 for Subtask B. For both subtasks, m-Bert based transformer model showed the best performance.
UrduFake@FIRE2021: Shared Track on Fake News Identification in Urdu
Jul 11, 2022
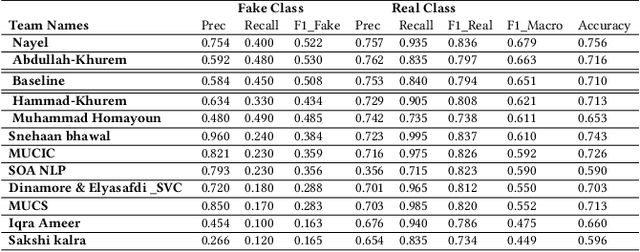

This study reports the second shared task named as UrduFake@FIRE2021 on identifying fake news detection in Urdu language. This is a binary classification problem in which the task is to classify a given news article into two classes: (i) real news, or (ii) fake news. In this shared task, 34 teams from 7 different countries (China, Egypt, Israel, India, Mexico, Pakistan, and UAE) registered to participate in the shared task, 18 teams submitted their experimental results and 11 teams submitted their technical reports. The proposed systems were based on various count-based features and used different classifiers as well as neural network architectures. The stochastic gradient descent (SGD) algorithm outperformed other classifiers and achieved 0.679 F-score.
Overview of the Shared Task on Fake News Detection in Urdu at FIRE 2021
Jul 11, 2022
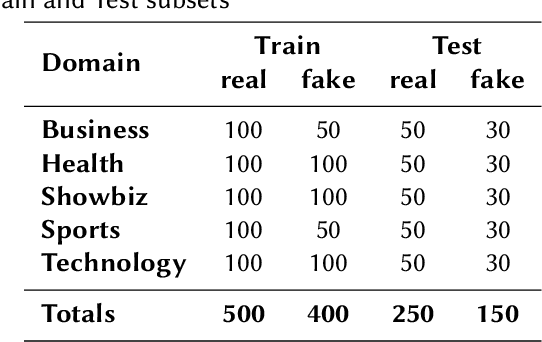


Automatic detection of fake news is a highly important task in the contemporary world. This study reports the 2nd shared task called UrduFake@FIRE2021 on identifying fake news detection in Urdu. The goal of the shared task is to motivate the community to come up with efficient methods for solving this vital problem, particularly for the Urdu language. The task is posed as a binary classification problem to label a given news article as a real or a fake news article. The organizers provide a dataset comprising news in five domains: (i) Health, (ii) Sports, (iii) Showbiz, (iv) Technology, and (v) Business, split into training and testing sets. The training set contains 1300 annotated news articles -- 750 real news, 550 fake news, while the testing set contains 300 news articles -- 200 real, 100 fake news. 34 teams from 7 different countries (China, Egypt, Israel, India, Mexico, Pakistan, and UAE) registered to participate in the UrduFake@FIRE2021 shared task. Out of those, 18 teams submitted their experimental results, and 11 of those submitted their technical reports, which is substantially higher compared to the UrduFake shared task in 2020 when only 6 teams submitted their technical reports. The technical reports submitted by the participants demonstrated different data representation techniques ranging from count-based BoW features to word vector embeddings as well as the use of numerous machine learning algorithms ranging from traditional SVM to various neural network architectures including Transformers such as BERT and RoBERTa. In this year's competition, the best performing system obtained an F1-macro score of 0.679, which is lower than the past year's best result of 0.907 F1-macro. Admittedly, while training sets from the past and the current years overlap to a large extent, the testing set provided this year is completely different.