 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimism, Expectation, or Sarcasm? Multi-Class Hope Speech Detection in Spanish and English
Apr 24, 2025
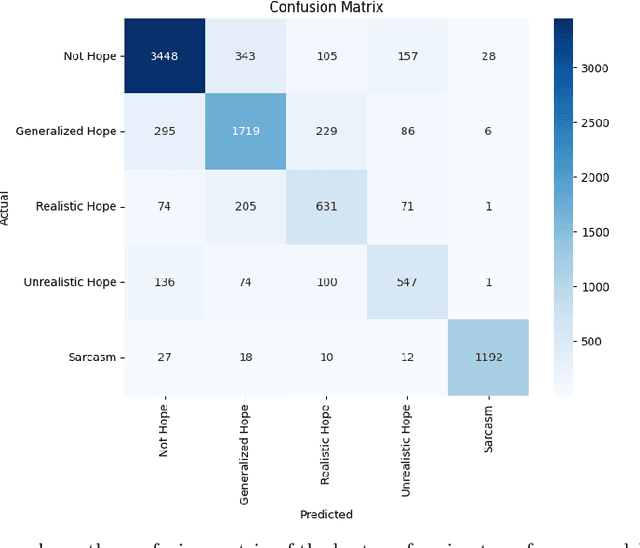
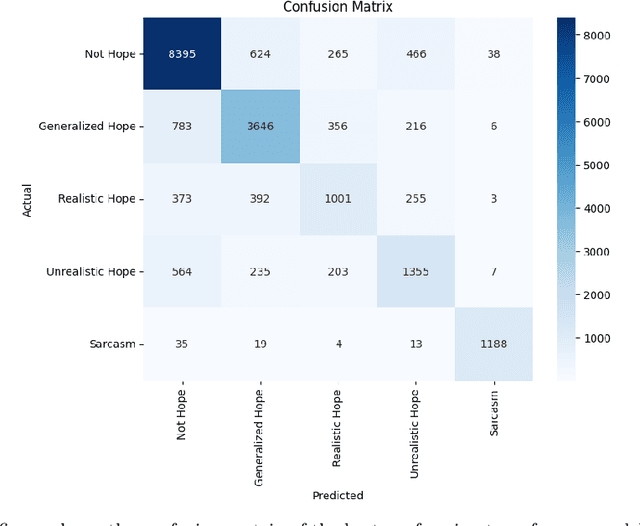
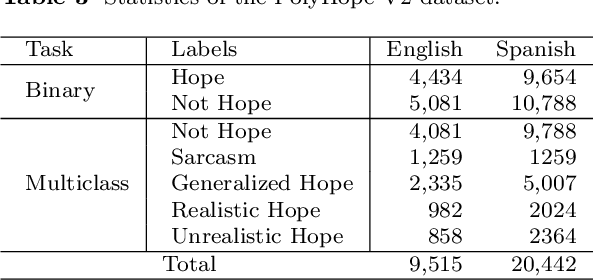
Hope is a complex and underexplored emotional state that plays a significant role in education, mental health, and social interaction. Unlike basic emotions, hope manifests in nuanced forms ranging from grounded optimism to exaggerated wishfulness or sarcasm, making it difficult for Natural Language Processing systems to detect accurately. This study introduces PolyHope V2, a multilingual, fine-grained hope speech dataset comprising over 30,000 annotated tweets in English and Spanish. This resource distinguishes between four hope subtypes Generalized, Realistic, Unrealistic, and Sarcastic and enhances existing datasets by explicitly labeling sarcastic instances. We benchmark multiple pretrained transformer models and compare them with large language models (LLMs) such as GPT 4 and Llama 3 under zero-shot and few-shot regimes. Our findings show that fine-tuned transformers outperform prompt-based LLMs, especially in distinguishing nuanced hope categories and sarcasm. Through qualitative analysis and confusion matrices, we highlight systematic challenges in separating closely related hope subtypes. The dataset and results provide a robust foundation for future emotion recognition tasks that demand greater semantic and contextual sensitivity across languages.
Tec-Habilidad: Skill Classification for Bridging Education and Employment
Mar 05, 2025
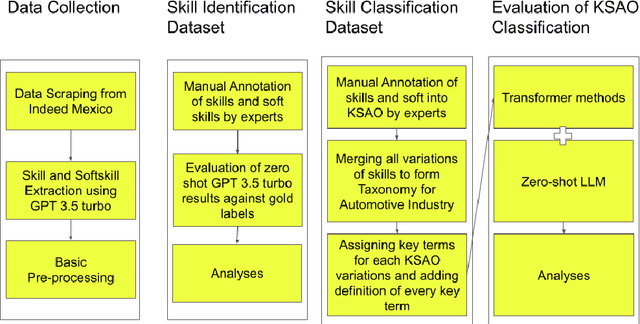

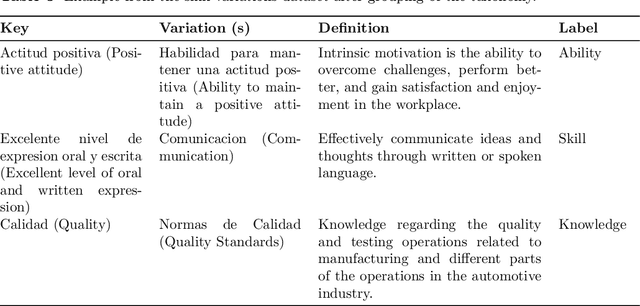
Job application and assessment processes have evolved significantly in recent years, largely due to advancements in technology and changes in the way companies operate. Skill extraction and classification remain an important component of the modern hiring process as it provides a more objective way to evaluate candidates and automatically align their skills with the job requirements. However, to effectively evaluate the skills, the skill extraction tools must recognize varied mentions of skills on resumes, including direct mentions, implications, synonyms, acronyms, phrases, and proficiency levels, and differentiate between hard and soft skills. While tools like LLMs (Large Model Models) help extract and categorize skills from job applications, there's a lack of comprehensive datasets for evaluating the effectiveness of these models in accurately identifying and classifying skills in Spanish-language job applications. This gap hinders our ability to assess the reliability and precision of the models, which is crucial for ensuring that the selected candidates truly possess the required skills for the job. In this paper, we develop a Spanish language dataset for skill extraction and classification, provide annotation methodology to distinguish between knowledge, skill, and abilities, and provide deep learning baselines to advance robust solutions for skill classification.