 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning based supervised semantic segmentation of Electron Cryo-Subtomograms
Feb 12, 2018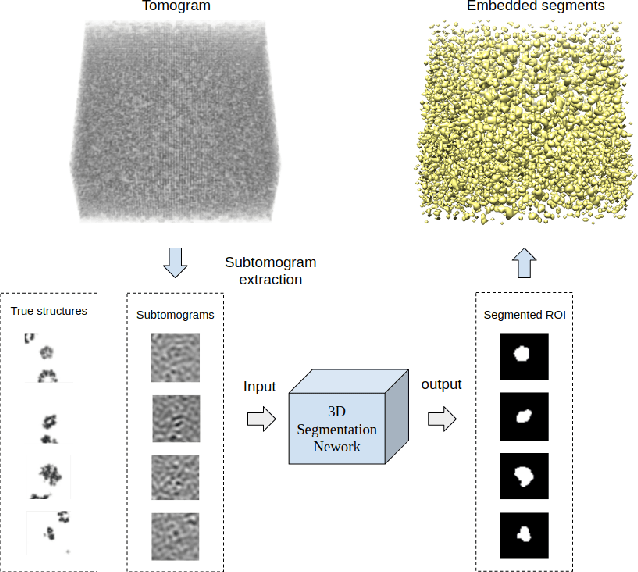
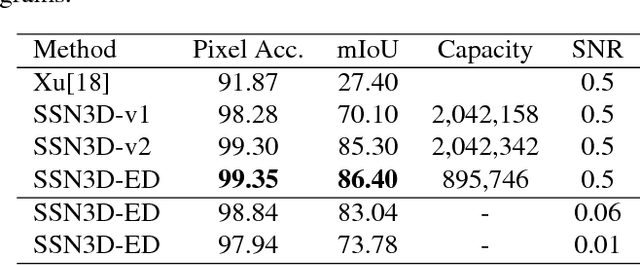
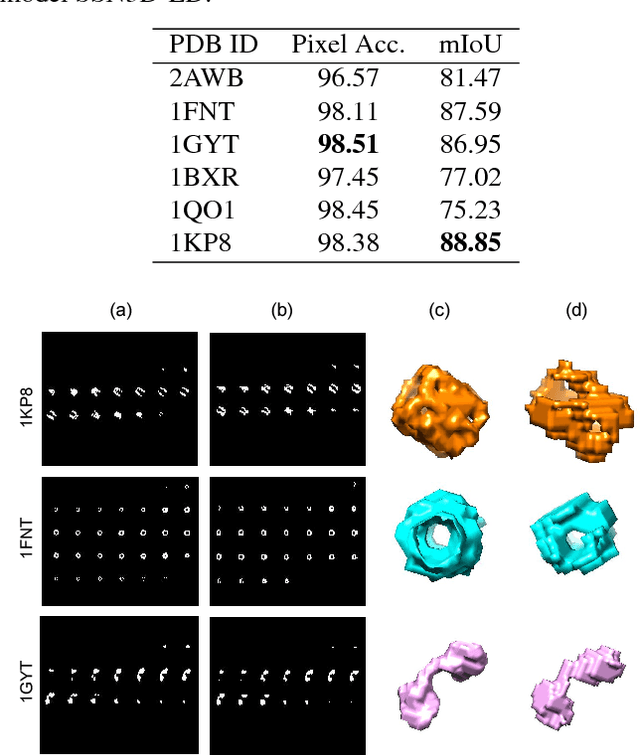
Cellular Electron Cryo-Tomography (CECT) is a powerful imaging technique for the 3D visualization of cellular structure and organization at submolecular resolution. It enables analyzing the native structures of macromolecular complexes and their spatial organization inside single cells. However, due to the high degree of structural complexity and practical imaging limitations, systematic macromolecular structural recovery inside CECT images remains challenging. Particularly, the recovery of a macromolecule is likely to be biased by its neighbor structures due to the high molecular crowding. To reduce the bias, here we introduce a novel 3D convolutional neural network inspired by Fully Convolutional Network and Encoder-Decoder Architecture for the supervised segmentation of macromolecules of interest in subtomograms. The tests of our models on realistically simulated CECT data demonstrate that our new approach has significantly improved segmentation performance compared to our baseline approach. Also, we demonstrate that the proposed model has generalization ability to segment new structures that do not exist in training data.
* 9 pages
Correlated and Individual Multi-Modal Deep Learning for RGB-D Object Recognition
Dec 09, 2016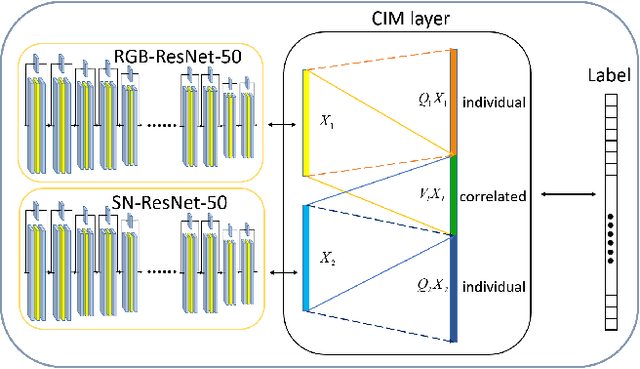



In this paper, we propose a new correlated and individual multi-modal deep learning (CIMDL) method for RGB-D object recognition. Unlike most conventional RGB-D object recognition methods which extract features from the RGB and depth channels individually, our CIMDL jointly learns feature representations from raw RGB-D data with a pair of deep neural networks, so that the sharable and modal-specific information can be simultaneously exploited. Specifically, we construct a pair of deep convolutional neural networks (CNNs) for the RGB and depth data, and concatenate them at the top layer of the network with a loss function which learns a new feature space where both correlated part and the individual part of the RGB-D information are well modelled. The parameters of the whole networks are updated by using the back-propagation criterion. Experimental results on two widely used RGB-D object image benchmark datasets clearly show that our method outperforms state-of-the-arts.