 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEAD: Layer-wise Expert-aligned Decoding for Faithful Radiology Report Generation
Feb 04, 2026Radiology Report Generation (RRG) aims to produce accurate and coherent diagnostics from medical images. Although large vision language models (LVLM) improve report fluency and accuracy, they exhibit hallucinations, generating plausible yet image-ungrounded pathological details. Existing methods primarily rely on external knowledge guidance to facilitate the alignment between generated text and visual information. However, these approaches often ignore the inherent decoding priors and vision-language alignment biases in pretrained models and lack robustness due to reliance on constructed guidance. In this paper, we propose Layer-wise Expert-aligned Decoding (LEAD), a novel method to inherently modify the LVLM decoding trajectory. A multiple experts module is designed for extracting distinct pathological features which are integrated into each decoder layer via a gating mechanism. This layer-wise architecture enables the LLM to consult expert features at every inference step via a learned gating function, thereby dynamically rectifying decoding biases and steering the generation toward factual consistency. Experiments conducted on multiple public datasets demonstrate that the LEAD method yields effective improvements in clinical accuracy metrics and mitigates hallucinations while preserving high generation quality.
Optimization of Multi-Agent Flying Sidekick Traveling Salesman Problem over Road Networks
Aug 20, 2024The mixed truck-drone delivery systems have attracted increasing attention for last-mile logistics, but real-world complexities demand a shift from single-agent, fully connected graph models to multi-agent systems operating on actual road networks. We introduce the multi-agent flying sidekick traveling salesman problem (MA-FSTSP) on road networks, extending the single truck-drone model to multiple trucks, each carrying multiple drones while considering full road networks for truck restrictions and flexible drone routes. We propose a mixed-integer linear programming model and an efficient three-phase heuristic algorithm for this NP-hard problem. Our approach decomposes MA-FSTSP into manageable subproblems of one truck with multiple drones. Then, it computes the routes for trucks without drones in subproblems, which are used in the final phase as heuristics to help optimize drone and truck routes simultaneously. Extensive numerical experiments on Manhattan and Boston road networks demonstrate our algorithm's superior effectiveness and efficiency, significantly outperforming both column generation and variable neighborhood search baselines in solution quality and computation time. Notably, our approach scales to more than 300 customers within a 5-minute time limit, showcasing its potential for large-scale, real-world logistics applications.
Equipping Black-Box Policies with Model-Based Advice for Stable Nonlinear Control
Jun 02, 2022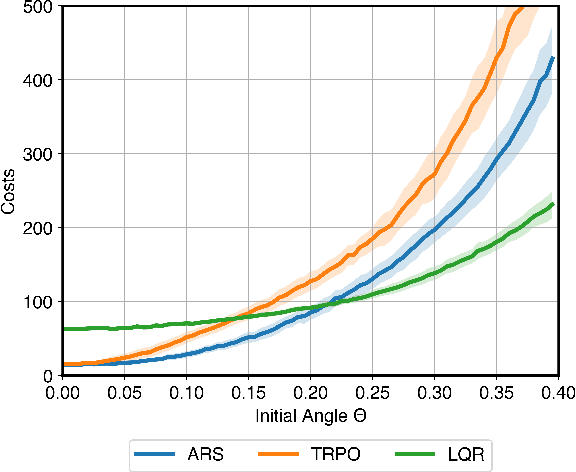

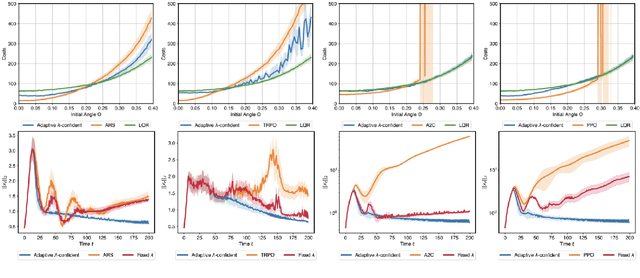
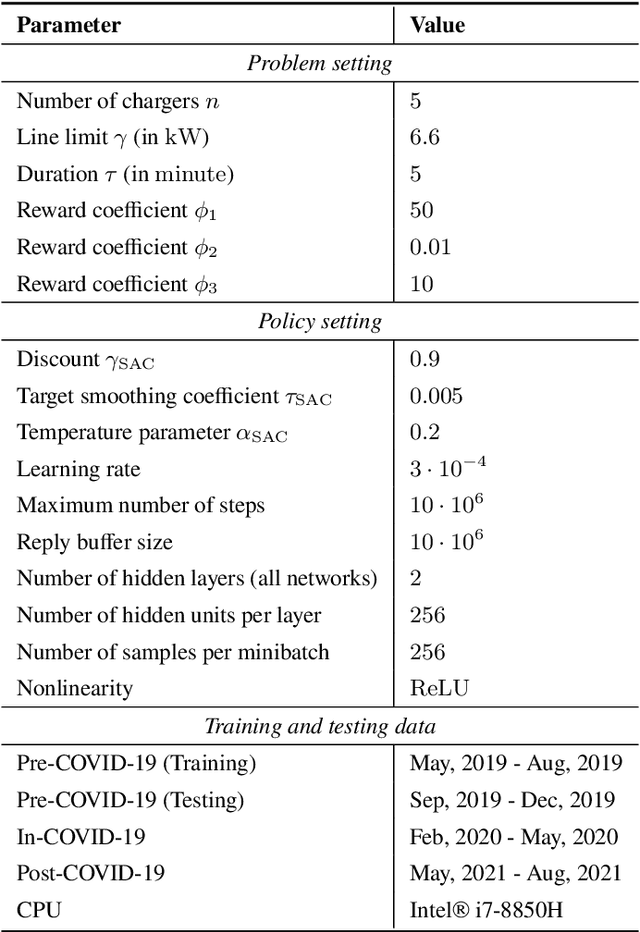
Machine-learned black-box policies are ubiquitous for nonlinear control problems. Meanwhile, crude model information is often available for these problems from, e.g., linear approximations of nonlinear dynamics. We study the problem of equipping a black-box control policy with model-based advice for nonlinear control on a single trajectory. We first show a general negative result that a naive convex combination of a black-box policy and a linear model-based policy can lead to instability, even if the two policies are both stabilizing. We then propose an adaptive $\lambda$-confident policy, with a coefficient $\lambda$ indicating the confidence in a black-box policy, and prove its stability. With bounded nonlinearity, in addition, we show that the adaptive $\lambda$-confident policy achieves a bounded competitive ratio when a black-box policy is near-optimal. Finally, we propose an online learning approach to implement the adaptive $\lambda$-confident policy and verify its efficacy in case studies about the CartPole problem and a real-world electric vehicle (EV) charging problem with data bias due to COVID-19.