 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Representation of Causal Background Knowledge and its Applications in Causal Inference
Jul 10, 2022

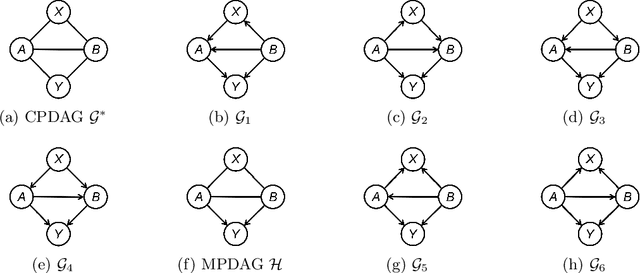

Causal background knowledge about the existence or the absence of causal edges and paths is frequently encountered in observational studies. The shared directed edges and links of a subclass of Markov equivalent DAGs refined due to background knowledge can be represented by a causal maximally partially directed acyclic graph (MPDAG). In this paper, we first provide a sound and complete graphical characterization of causal MPDAGs and give a minimal representation of a causal MPDAG. Then, we introduce a novel representation called direct causal clause (DCC) to represent all types of causal background knowledge in a unified form. Using DCCs, we study the consistency and equivalency of causal background knowledge and show that any causal background knowledge set can be equivalently decomposed into a causal MPDAG plus a minimal residual set of DCCs. Polynomial-time algorithms are also provided for checking the consistency, equivalency, and finding the decomposed MPDAG and residual DCCs. Finally, with causal background knowledge, we prove a sufficient and necessary condition to identify causal effects and surprisingly find that the identifiability of causal effects only depends on the decomposed MPDAG. We also develop a local IDA-type algorithm to estimate the possible values of an unidentifiable effect. Simulations suggest that causal background knowledge can significantly improve the identifiability of causal effects.
Sparse to Dense Motion Transfer for Face Image Animation
Sep 03, 2021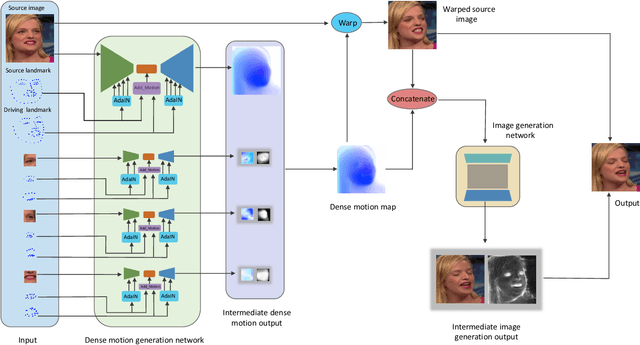


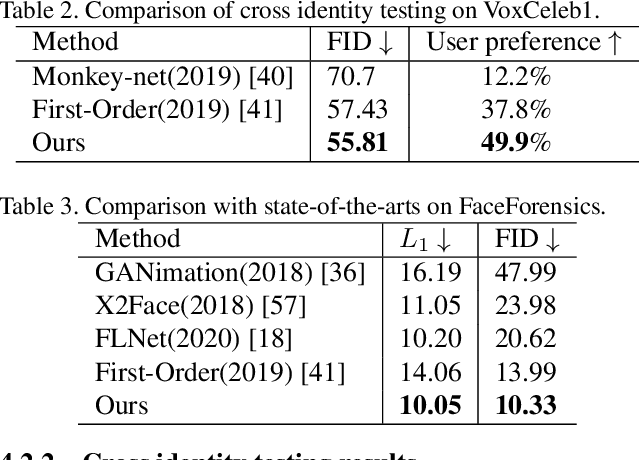
Face image animation from a single image has achieved remarkable progress. However, it remains challenging when only sparse landmarks are available as the driving signal. Given a source face image and a sequence of sparse face landmarks, our goal is to generate a video of the face imitating the motion of landmarks. We develop an efficient and effective method for motion transfer from sparse landmarks to the face image. We then combine global and local motion estimation in a unified model to faithfully transfer the motion. The model can learn to segment the moving foreground from the background and generate not only global motion, such as rotation and translation of the face, but also subtle local motion such as the gaze change. We further improve face landmark detection on videos. With temporally better aligned landmark sequences for training, our method can generate temporally coherent videos with higher visual quality. Experiments suggest we achieve results comparable to the state-of-the-art image driven method on the same identity testing and better results on cross identity testing.
A Simple, Fast and Highly-Accurate Algorithm to Recover 3D Shape from 2D Landmarks on a Single Image
Sep 28, 2016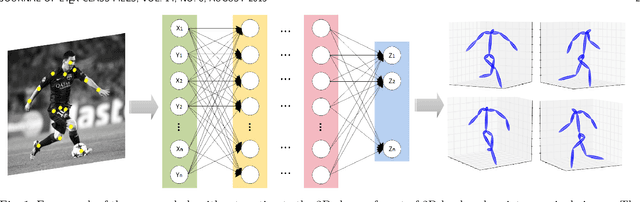

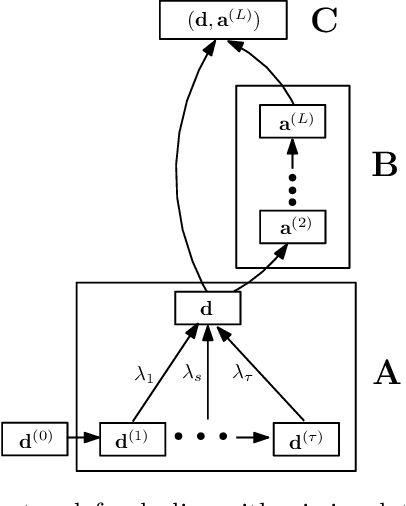
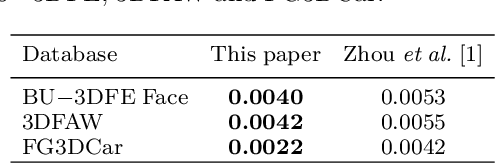
Three-dimensional shape reconstruction of 2D landmark points on a single image is a hallmark of human vision, but is a task that has been proven difficult for computer vision algorithms. We define a feed-forward deep neural network algorithm that can reconstruct 3D shapes from 2D landmark points almost perfectly (i.e., with extremely small reconstruction errors), even when these 2D landmarks are from a single image. Our experimental results show an improvement of up to two-fold over state-of-the-art computer vision algorithms; 3D shape reconstruction of human faces is given at a reconstruction error < .004, cars at .0022, human bodies at .022, and highly-deformable flags at an error of .0004. Our algorithm was also a top performer at the 2016 3D Face Alignment in the Wild Challenge competition (done in conjunction with the European Conference on Computer Vision, ECCV) that required the reconstruction of 3D face shape from a single image. The derived algorithm can be trained in a couple hours and testing runs at more than 1, 000 frames/s on an i7 desktop. We also present an innovative data augmentation approach that allows us to train the system efficiently with small number of samples. And the system is robust to noise (e.g., imprecise landmark points) and missing data (e.g., occluded or undetected landmark points).