 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple, Fast and Highly-Accurate Algorithm to Recover 3D Shape from 2D Landmarks on a Single Image
Paper and Code
Sep 28, 2016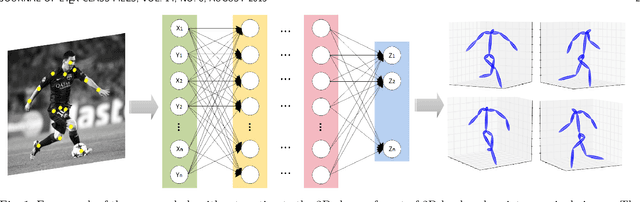

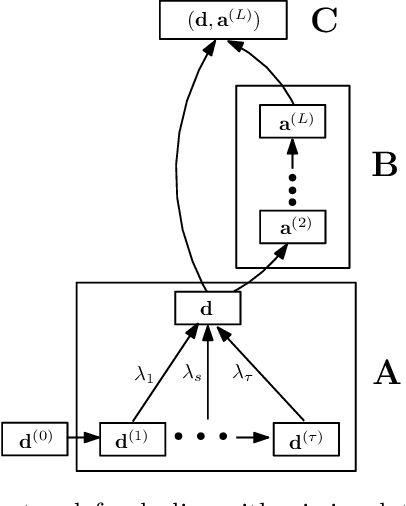
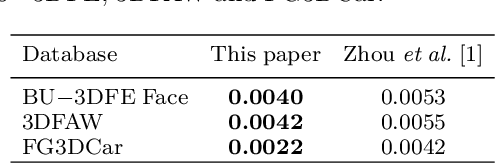
Three-dimensional shape reconstruction of 2D landmark points on a single image is a hallmark of human vision, but is a task that has been proven difficult for computer vision algorithms. We define a feed-forward deep neural network algorithm that can reconstruct 3D shapes from 2D landmark points almost perfectly (i.e., with extremely small reconstruction errors), even when these 2D landmarks are from a single image. Our experimental results show an improvement of up to two-fold over state-of-the-art computer vision algorithms; 3D shape reconstruction of human faces is given at a reconstruction error < .004, cars at .0022, human bodies at .022, and highly-deformable flags at an error of .0004. Our algorithm was also a top performer at the 2016 3D Face Alignment in the Wild Challenge competition (done in conjunction with the European Conference on Computer Vision, ECCV) that required the reconstruction of 3D face shape from a single image. The derived algorithm can be trained in a couple hours and testing runs at more than 1, 000 frames/s on an i7 desktop. We also present an innovative data augmentation approach that allows us to train the system efficiently with small number of samples. And the system is robust to noise (e.g., imprecise landmark points) and missing data (e.g., occluded or undetected landmark points).