 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse to Dense Motion Transfer for Face Image Animation
Paper and Code
Sep 03, 2021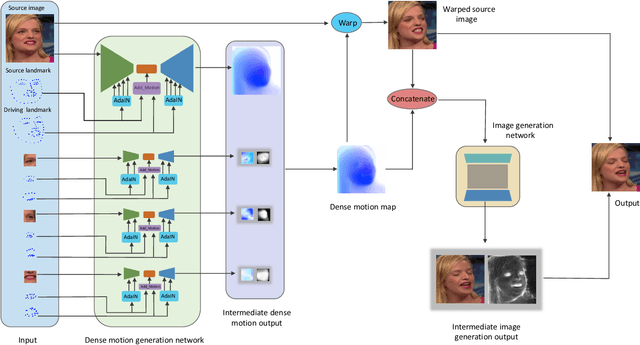


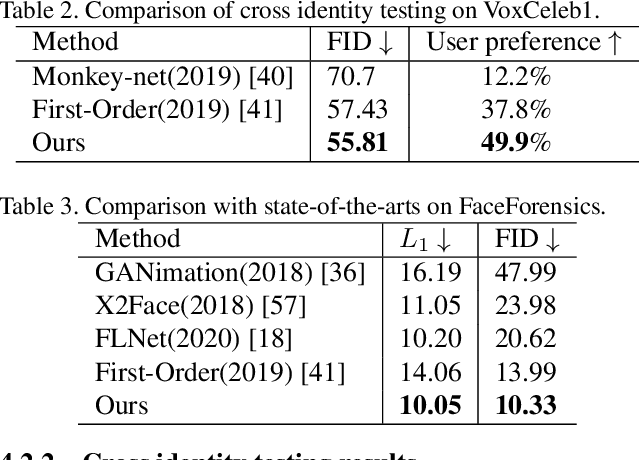
Face image animation from a single image has achieved remarkable progress. However, it remains challenging when only sparse landmarks are available as the driving signal. Given a source face image and a sequence of sparse face landmarks, our goal is to generate a video of the face imitating the motion of landmarks. We develop an efficient and effective method for motion transfer from sparse landmarks to the face image. We then combine global and local motion estimation in a unified model to faithfully transfer the motion. The model can learn to segment the moving foreground from the background and generate not only global motion, such as rotation and translation of the face, but also subtle local motion such as the gaze change. We further improve face landmark detection on videos. With temporally better aligned landmark sequences for training, our method can generate temporally coherent videos with higher visual quality. Experiments suggest we achieve results comparable to the state-of-the-art image driven method on the same identity testing and better results on cross identity testing.