 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiD-FL: Towards List-Decodable Federated Learning
Aug 09, 2024Federated learning is often used in environments with many unverified participants. Therefore, federated learning under adversarial attacks receives significant attention. This paper proposes an algorithmic framework for list-decodable federated learning, where a central server maintains a list of models, with at least one guaranteed to perform well. The framework has no strict restriction on the fraction of honest workers, extending the applicability of Byzantine federated learning to the scenario with more than half adversaries. Under proper assumptions on the loss function, we prove a convergence theorem for our method. Experimental results, including image classification tasks with both convex and non-convex losses, demonstrate that the proposed algorithm can withstand the malicious majority under various attacks.
Near-Optimal Resilient Aggregation Rules for Distributed Learning Using 1-Center and 1-Mean Clustering with Outliers
Dec 20, 2023Byzantine machine learning has garnered considerable attention in light of the unpredictable faults that can occur in large-scale distributed learning systems. The key to secure resilience against Byzantine machines in distributed learning is resilient aggregation mechanisms. Although abundant resilient aggregation rules have been proposed, they are designed in ad-hoc manners, imposing extra barriers on comparing, analyzing, and improving the rules across performance criteria. This paper studies near-optimal aggregation rules using clustering in the presence of outliers. Our outlier-robust clustering approach utilizes geometric properties of the update vectors provided by workers. Our analysis show that constant approximations to the 1-center and 1-mean clustering problems with outliers provide near-optimal resilient aggregators for metric-based criteria, which have been proven to be crucial in the homogeneous and heterogeneous cases respectively. In addition, we discuss two contradicting types of attacks under which no single aggregation rule is guaranteed to improve upon the naive average. Based on the discussion, we propose a two-phase resilient aggregation framework. We run experiments for image classification using a non-convex loss function. The proposed algorithms outperform previously known aggregation rules by a large margin with both homogeneous and heterogeneous data distributions among non-faulty workers. Code and appendix are available at https://github.com/jerry907/AAAI24-RASHB.
AttentionXML: Extreme Multi-Label Text Classification with Multi-Label Attention Based Recurrent Neural Networks
Nov 01, 2018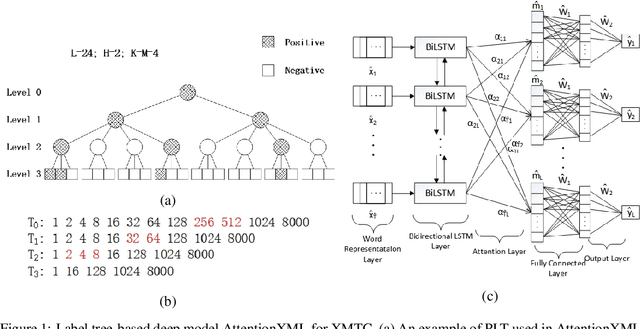
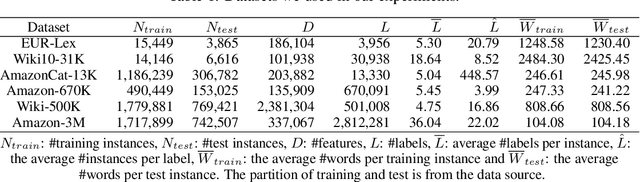
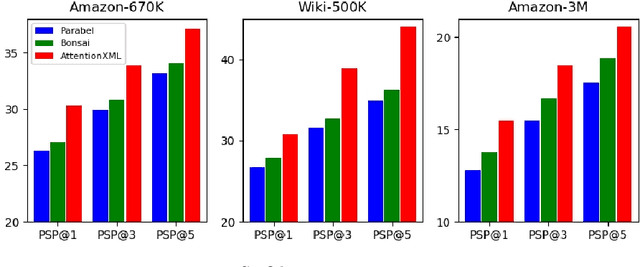
Extreme multi-label text classification (XMTC) is a task for tagging each given text with the most relevant multiple labels from an extremely large-scale label set. This task can be found in many applications, such as product categorization,web page tagging, news annotation and so on. Many methods have been proposed so far for solving XMTC, while most of the existing methods use traditional bag-of-words (BOW) representation, ignoring word context as well as deep semantic information. XML-CNN, a state-of-the-art deep learning-based method, uses convolutional neural network (CNN) with dynamic pooling to process the text, going beyond the BOW-based appraoches but failing to capture 1) the long-distance dependency among words and 2) different levels of importance of a word for each label. We propose a new deep learning-based method, AttentionXML, which uses bidirectional long short-term memory (LSTM) and a multi-label attention mechanism for solving the above 1st and 2nd problems, respectively. We empirically compared AttentionXML with other six state-of-the-art methods over five benchmark datasets. AttentionXML outperformed all competing methods under all experimental settings except only a couple of cases. In addition, a consensus ensemble of AttentionXML with the second best method, Parabel, could further improve the performance over all five benchmark datasets.