 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCitiLink: Enhancing Municipal Transparency and Citizen Engagement through Searchable Meeting Minutes
Jan 26, 2026City council minutes are typically lengthy and formal documents with a bureaucratic writing style. Although publicly available, their structure often makes it difficult for citizens or journalists to efficiently find information. In this demo, we present CitiLink, a platform designed to transform unstructured municipal meeting minutes into structured and searchable data, demonstrating how NLP and IR can enhance the accessibility and transparency of local government. The system employs LLMs to extract metadata, discussed subjects, and voting outcomes, which are then indexed in a database to support full-text search with BM25 ranking and faceted filtering through a user-friendly interface. The developed system was built over a collection of 120 minutes made available by six Portuguese municipalities. To assess its usability, CitiLink was tested through guided sessions with municipal personnel, providing insights into how real users interact with the system. In addition, we evaluated Gemini's performance in extracting relevant information from the minutes, highlighting its effectiveness in data extraction.
FeatGeNN: Improving Model Performance for Tabular Data with Correlation-based Feature Extraction
Aug 15, 2023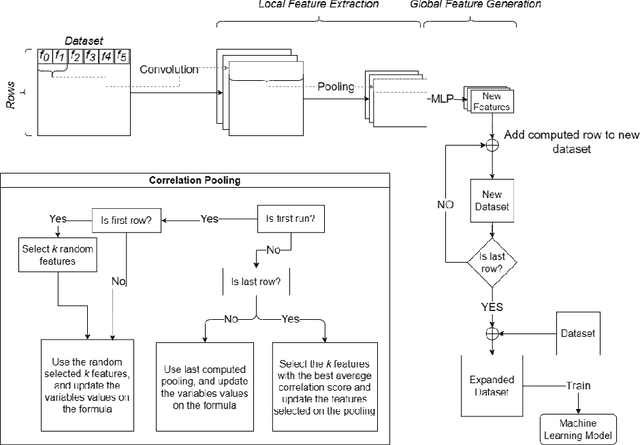
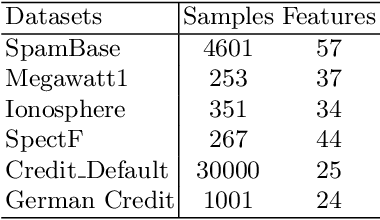
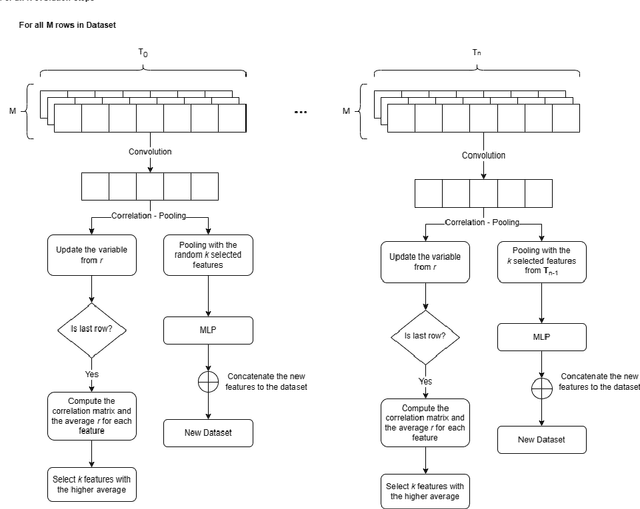
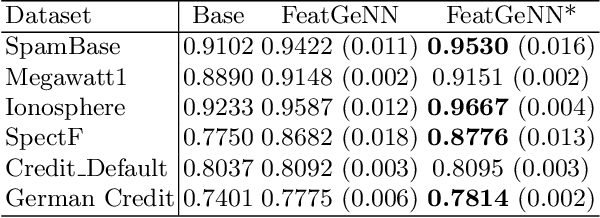
Automated Feature Engineering (AutoFE) has become an important task for any machine learning project, as it can help improve model performance and gain more information for statistical analysis. However, most current approaches for AutoFE rely on manual feature creation or use methods that can generate a large number of features, which can be computationally intensive and lead to overfitting. To address these challenges, we propose a novel convolutional method called FeatGeNN that extracts and creates new features using correlation as a pooling function. Unlike traditional pooling functions like max-pooling, correlation-based pooling considers the linear relationship between the features in the data matrix, making it more suitable for tabular data. We evaluate our method on various benchmark datasets and demonstrate that FeatGeNN outperforms existing AutoFE approaches regarding model performance. Our results suggest that correlation-based pooling can be a promising alternative to max-pooling for AutoFE in tabular data applications.
A Decidability-Based Loss Function
Sep 12, 2021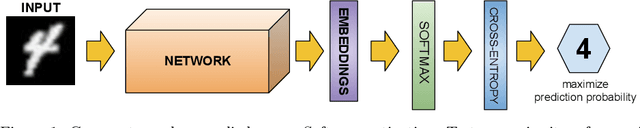
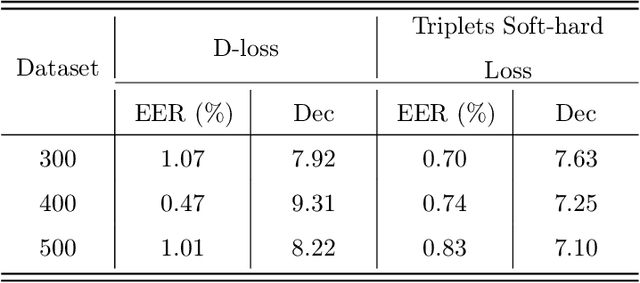
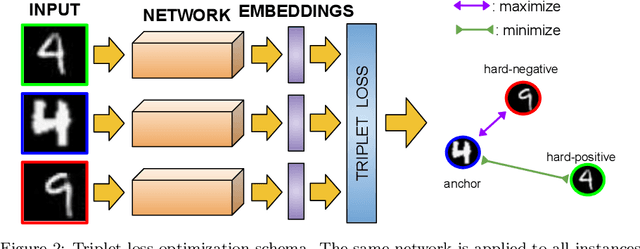

Nowadays, deep learning is the standard approach for a wide range of problems, including biometrics, such as face recognition and speech recognition, etc. Biometric problems often use deep learning models to extract features from images, also known as embeddings. Moreover, the loss function used during training strongly influences the quality of the generated embeddings. In this work, a loss function based on the decidability index is proposed to improve the quality of embeddings for the verification routine. Our proposal, the D-loss, avoids some Triplet-based loss disadvantages such as the use of hard samples and tricky parameter tuning, which can lead to slow convergence. The proposed approach is compared against the Softmax (cross-entropy), Triplets Soft-Hard, and the Multi Similarity losses in four different benchmarks: MNIST, Fashion-MNIST, CIFAR10 and CASIA-IrisV4. The achieved results show the efficacy of the proposal when compared to other popular metrics in the literature. The D-loss computation, besides being simple, non-parametric and easy to implement, favors both the inter-class and intra-class scenarios.
Applying Genetic Programming to Improve Interpretability in Machine Learning Models
May 18, 2020
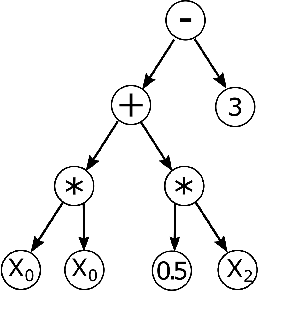
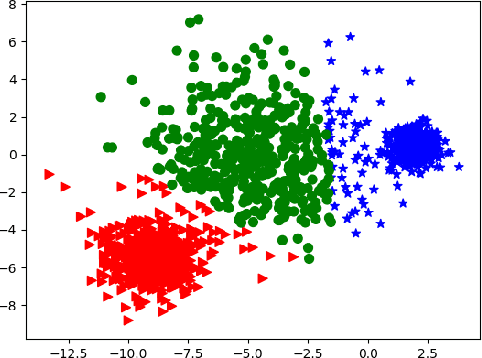
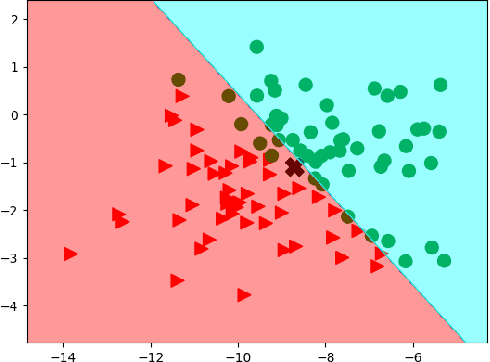
Explainable Artificial Intelligence (or xAI) has become an important research topic in the fields of Machine Learning and Deep Learning. In this paper, we propose a Genetic Programming (GP) based approach, named Genetic Programming Explainer (GPX), to the problem of explaining decisions computed by AI systems. The method generates a noise set located in the neighborhood of the point of interest, whose prediction should be explained, and fits a local explanation model for the analyzed sample. The tree structure generated by GPX provides a comprehensible analytical, possibly non-linear, symbolic expression which reflects the local behavior of the complex model. We considered three machine learning techniques that can be recognized as complex black-box models: Random Forest, Deep Neural Network and Support Vector Machine in twenty data sets for regression and classifications problems. Our results indicate that the GPX is able to produce more accurate understanding of complex models than the state of the art. The results validate the proposed approach as a novel way to deploy GP to improve interpretability.
Towards an Effective and Efficient Deep Learning Model for COVID-19 Patterns Detection in X-ray Images
Apr 28, 2020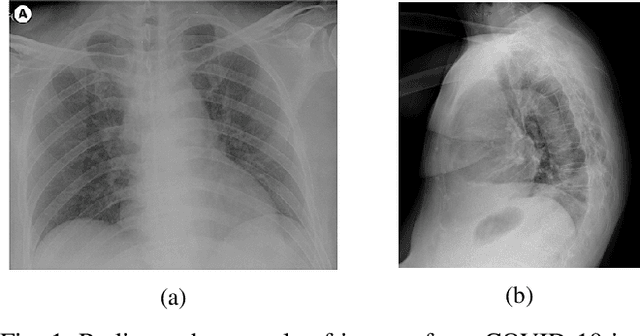
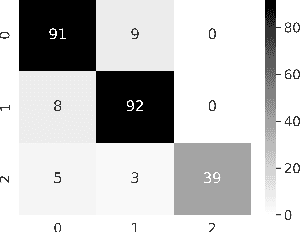
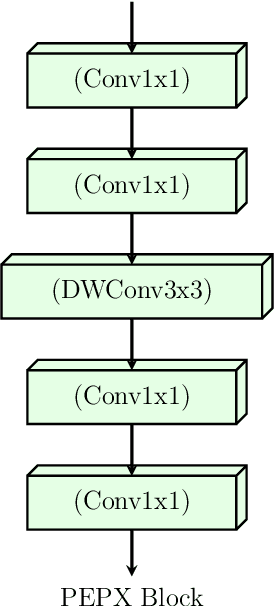
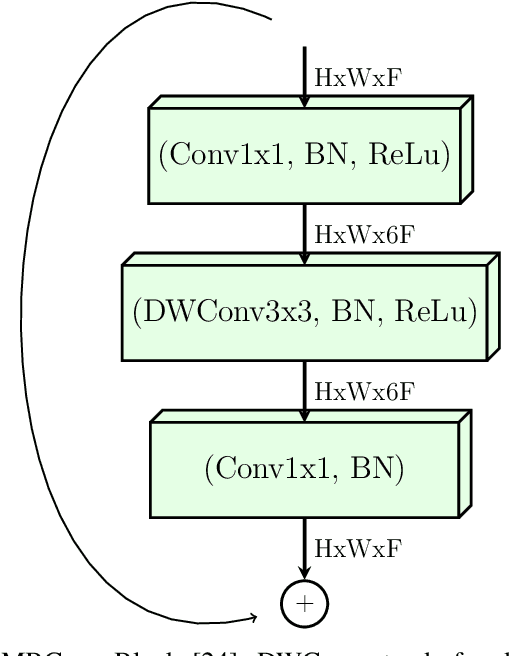
Confronting the pandemic of COVID-19 caused by the new coronavirus, the SARS-CoV-2, is nowadays one of the most prominent challenges of the human species. A key factor in slowing down the virus propagation is the rapid diagnosis and isolation of infected patients. Nevertheless, the standard method for COVID-19 identification, the Reverse transcription polymerase chain reaction (RT-PCR) method, is time-consuming and in short supply due to the pandemic. Researchers around the world have been looking for alternative screening methods. In this context, deep learning applied to chest X-rays of patients has been showing promising results in the identification of COVID-19. Despite their success, the computational cost of these methods remains high, which imposes difficulties in their accessibility and availability. Thus, in this work, we propose to explore and extend the EfficientNet family of models using chest X-rays images to perform COVID-19 detection. As a result, we can produce a high-quality model with an overall accuracy of 93.9%, COVID-19, sensitivity of 96.8% and positive prediction of 100% while having about 30 times fewer parameters than the baseline literature model, 28 and 5 times fewer parameters than the popular VGG16 and ResNet50 architectures, respectively. We believe the reported figures represent state-of-the-art results, both in terms of efficiency and effectiveness, for the COVIDx database, a database comprised of 13,800 X-ray images, 183 of which are from patients affected by COVID-19.
Forecasting in Non-stationary Environments with Fuzzy Time Series
Apr 27, 2020
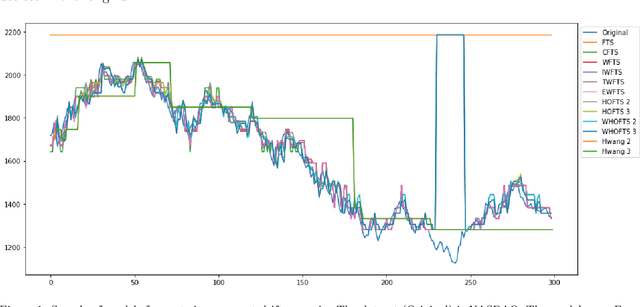
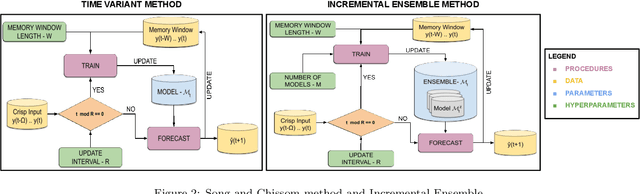

In this paper we introduce a Non-Stationary Fuzzy Time Series (NSFTS) method with time varying parameters adapted from the distribution of the data. In this approach, we employ Non-Stationary Fuzzy Sets, in which perturbation functions are used to adapt the membership function parameters in the knowledge base in response to statistical changes in the time series. The proposed method is capable of dynamically adapting its fuzzy sets to reflect the changes in the stochastic process based on the residual errors, without the need to retraining the model. This method can handle non-stationary and heteroskedastic data as well as scenarios with concept-drift. The proposed approach allows the model to be trained only once and remain useful long after while keeping reasonable accuracy. The flexibility of the method by means of computational experiments was tested with eight synthetic non-stationary time series data with several kinds of concept drifts, four real market indices (Dow Jones, NASDAQ, SP500 and TAIEX), three real FOREX pairs (EUR-USD, EUR-GBP, GBP-USD), and two real cryptocoins exchange rates (Bitcoin-USD and Ethereum-USD). As competitor models the Time Variant fuzzy time series and the Incremental Ensemble were used, these are two of the major approaches for handling non-stationary data sets. Non-parametric tests are employed to check the significance of the results. The proposed method shows resilience to concept drift, by adapting parameters of the model, while preserving the symbolic structure of the knowledge base.